时间序列(time series)数据是一种重要的结构化数据形式,。在多个时间点观察或测量到的任何时间都可以形成一段时间序列。很多时间, 时间序列是固定频率的, 也就是说, 数据点是根据某种规律定期出现的(比如每15秒。。。。)。时间序列也可以是不定期的。时间序列数据的意义取决于具体的应用场景。主要由以下几种:
1.时间戳;(timestamp)特定的时刻
2.固定时间:(period)如2010年全年或者某个月份
3.时间间隔:(interval)由起始和结束时间戳表示, 时期(period)可以被看做是间隔(interval)的特例
时间和日期数据类型及其工具:
在 hahh.python_dataming_test_book.TEST1.py
#coding=gbk
import numpy as np
import pandas as pd
from datetime import datetime
from datetime import timedelta
#字符串和时间的转换
stamp = datetime(2018, 7, 25)
print(str(stamp)) # 2018-07-25 00:00:00
stamp1 = stamp.strftime('%Y-%m-%d') #Year 年 month 月
print(stamp1) # 2018-07-25
value = '2018-1-12'
strp_time = datetime.strptime(value, '%Y-%m-%d')
print(strp_time) # 2018-01-12 00:00:00
datestrs = ['7/6/2011','8/6/2011']
print([datetime.strptime(x, '%m/%d/%Y') for x in datestrs])
# [datetime.datetime(2011, 7, 6, 0, 0), datetime.datetime(2011, 8, 6, 0, 0)]

对于一些常见的日期格式, 可以使用第三方库的dateutil 中的parser.parse 方法
from dateutil.parser import parse
print(parse('2012-12-12')) # datetime.datetime(2012, 12, 12, 0, 0)
print(parse('Jan 31, 1997 10:45 PM')) #1997-01-31 22:45:00
#加入时间是把日放在前面, 则可以使用 dayfirst = True
print(parse('6/12/2011', dayfirst = True)) #2011-12-06 00:00:00
#to_datetime 可以解析很多不同种类的日期表示
datestrs = ['2011-07-06 12:00:00','2011-08-06 00:00:00']
print(pd.to_datetime(datestrs))
# DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00'], dtype='datetime64[ns]', freq=None)
#处理一些应该被判定为缺失的值, NaT :Not a Time 用于表示时间戳为空值
idx = pd.to_datetime(datestrs + [None])
print(idx[2]) #NaT
print(idx.isnull()) # [False False True]
print(idx.notnull())时间序列基础
在pandas中,一个基本的时间序列对象,是一个用时间戳作为索引的Series,在pandas外部的话,通常是用python 字符串或datetime对象来表示的:
import pandas as pd
import numpy as np
from datetime import datetime
dates = [datetime(2011,1,2), datetime(2011,1,5),
datetime(2011,1,7), datetime(2011,1,8),
datetime(2011,1,10), datetime(2011,1,12)
]
np.random.seed(666)
ts = pd.Series(np.random.randn(6), index = dates) #使用时间戳作为索引
print(ts)
# 2011-01-02 0.824188
# 2011-01-05 0.479966
# 2011-01-07 1.173468
# 2011-01-08 0.909048
# 2011-01-10 -0.571721
# 2011-01-12 -0.109497
# dtype: float64
print(ts.index)
# #DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08',
# '2011-01-10', '2011-01-12'],
# dtype='datetime64[ns]', freq=None)
print(ts[ts.index[2]]) # 1.1734680120920244 选取第三行的元素
print(ts['20110105']) # 0.47996600310104814
#对于较长的时间序列, 可以传入年, 或者 月来进行索引
longer_date = pd.Series(np.random.randn(1000), index = pd.date_range('2012-01-01', periods=1000))
print(longer_date.shape) # (1000,)
print(longer_date[:3]) #打印出前3项出来
# 2012-01-01 0.019028
# 2012-01-02 -0.943761
# 2012-01-03 0.640573
# Freq: D, dtype: float64
print(longer_date['2014'][:3]) #依据年份进行索引, 打印出前3 项
# 2014-01-01 1.154235
# 2014-01-02 0.360002
# 2014-01-03 -1.197186
# Freq: D, dtype: float64
print(longer_date['2014-05'][:3]) #依据年 月
# 2014-05-01 -0.036317
# 2014-05-02 0.134003
# 2014-05-03 -0.863556
# Freq: D, dtype: float64
#使用时间戳进行切片
print(longer_date['2014-03-03':'2014-03-06']) #可以看到 3号 和 6 号都包括了
# 2014-03-03 -1.157900
# 2014-03-04 0.690954
# 2014-03-05 2.187638
# 2014-03-06 -0.194585
# Freq: D, dtype: float64
print(ts.truncate(after = '1/6/2011')) #定义最后一项是2011 -1-6 选取之前的日期
# 2011-01-02 0.824188
# 2011-01-05 0.479966
# dtype: float64重复索引的时间序列
dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000',
'1/2/2000', '1/3/2000'])
dup_ts = pd.Series(np.random.randn(5), index = dates)
print(dup_ts)
# 2000-01-01 0.721593
# 2000-01-02 -0.024682
# 2000-01-02 -0.813268
# 2000-01-02 -2.478950
# 2000-01-03 0.497203
# dtype: float64
print(dup_ts.index.duplicated())# [False False True True False]
print(dup_ts.index.is_unique) # False 代表不是唯一的
#聚合具有重复时间戳的数据, 一种方法是 groupby 使得 level = 0
grouped = dup_ts.groupby(level=0)
print(grouped.mean()) #计算相同时间的 平均值
# 2000-01-01 0.721593
# 2000-01-02 -1.105633
# 2000-01-03 0.497203
# dtype: float64
print(grouped.count()) #计算出现的次数
# 2000-01-01 1
# 2000-01-02 3
# 2000-01-03 1
# dtype: int64日期的范围,频率以及移动
普通的时间序列通常是不规律的,但我们希望能有一个固定的频度,比如每天,每月,或没15分钟,即使有一些缺失值也没关系。幸运的是,pandas中有一套方法和工具来进行重采样,推断频度,并生成固定频度的日期范围。例如,我们可以把样本时间序列变为固定按日的频度,需要调用resample:
import pandas as pd
import numpy as np
from datetime import datetime
dates = [datetime(2011,1,2), datetime(2011,1,5),
datetime(2011,1,7), datetime(2011,1,8),
datetime(2011,1,10), datetime(2011,1,12)
]
np.random.seed(666)
ts = pd.Series(np.random.randn(6), index = dates) #使用时间戳作为索引
print(ts)
# # 2011-01-02 0.824188
# # 2011-01-05 0.479966
# # 2011-01-07 1.173468
# # 2011-01-08 0.909048
# # 2011-01-10 -0.571721
# # 2011-01-12 -0.109497
# # dtype: float64
resampler = ts.resample('D') #下面会更深入地讲
print(resampler)
#生成日期的范围
index = pd.date_range('2012-04-01','2012-06-01') #只传入起始和结束时间
print(index[:5])
# DatetimeIndex(['2012-04-01', '2012-04-02', '2012-04-03', '2012-04-04',
# '2012-04-05'],
# dtype='datetime64[ns]', freq='D')
pd.date_range(end='2012-06-01', periods=20) # 输入结束时间也可以输入 start, 打印出20 个时间戳
#设定频度 freq
print(pd.date_range('2000-01-01','2000-12-01', freq = 'BM')) #设置频度为每个月的最后一个工作日
# DatetimeIndex(['2000-01-31', '2000-02-29', '2000-03-31', '2000-04-28',
# '2000-05-31', '2000-06-30', '2000-07-31', '2000-08-31',
# '2000-09-29', '2000-10-31', '2000-11-30'],
# dtype='datetime64[ns]', freq='BM')
#将时间戳进行归一化,将秒 进行清零
nor_date = pd.date_range('2015-05-02 12:50:21', periods = 5, normalize=True)
print(nor_date)
# DatetimeIndex(['2015-05-02', '2015-05-03', '2015-05-04', '2015-05-05',
# '2015-05-06'],
# dtype='datetime64[ns]', freq='D')
print(nor_date[0]) # 2015-05-02 00:00:00 可以看到分钟,秒都归为0 了

pandas中的频度由一个基本频度(base frequency)和一个乘法器(multiplier)组成。基本频度通常用一个字符串别名(string alias)来代表,比如'M'表示月,'H'表示小时。对每一个基本频度,还有一个被称之为日期偏移(date offset)的对象
from pandas.tseries.offsets import Hour, Minute
hour = Hour()
print(hour) #<Hour>
#通过传入一个参数, 可以定义一个乘以偏移的乘法
four_hour = Hour(4)
print(four_hour) # <4 * Hours>
#但是, 在很多情况下, 我们不需要创建这些对象, 而是使用字符串的别名, 比如‘H
print(pd.date_range('2000-01-01','2000-01-02 23:00', freq='6H'))
# DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 06:00:00',
# '2000-01-01 12:00:00', '2000-01-01 18:00:00',
# '2000-01-02 00:00:00', '2000-01-02 06:00:00',
# '2000-01-02 12:00:00', '2000-01-02 18:00:00'],
# dtype='datetime64[ns]', freq='6H')
print(pd.date_range('2000-01-01',periods=5,freq ='1h20min')) # 1h20min 也是可以解析的
# DatetimeIndex(['2000-01-01 00:00:00', '2000-01-01 01:20:00',
# '2000-01-01 02:40:00', '2000-01-01 04:00:00',
# '2000-01-01 05:20:00'],
# dtype='datetime64[ns]', freq='80T')
# Week of month dates 代表月中的第几周日期,使用 WOM
print(pd.date_range('2012-01-01','2012-09-01',freq ='WOM-3FRI')) #WOM-3FRI 代表每月的第3个星期五
# DatetimeIndex(['2012-01-20', '2012-02-17', '2012-03-16', '2012-04-20',
# '2012-05-18', '2012-06-15', '2012-07-20', '2012-08-17'],
# dtype='datetime64[ns]', freq='WOM-3FRI')偏移(shifting)表示按照时间把数据向前或向后推移。Series和DataFrame都有一个shift方法实现偏移,索引(index)不会被更改:
#偏移数据,按时间把数据向前或者先后推移
ts = pd.Series(np.random.randn(4), index = pd.date_range('2012-01-01',periods =4, freq ='M'))
print(ts)
# 2012-01-31 0.019028
# 2012-02-29 -0.943761
# 2012-03-31 0.640573
# 2012-04-30 -0.786443
# Freq: M, dtype: float64
print(ts.shift(2)) #将数据往后提, 往前提则为 ts.shift(-2)
# 2012-01-31 NaN
# 2012-02-29 NaN
# 2012-03-31 0.019028
# 2012-04-30 -0.943761
# Freq: M, dtype: float64
#计算时间序列的百分比变化
print(ts/ ts.shift(1) -1)
# 2012-01-31 NaN
# 2012-02-29 -50.597852
# 2012-03-31 -1.678745
# 2012-04-30 -2.227718
# Freq: M, dtype: float64
#如果频度是已知的, 可以吧频度传给shift ,时间戳会自动变化
print(ts)
# 2012-01-31 0.019028
# 2012-02-29 -0.943761
# 2012-03-31 0.640573
# 2012-04-30 -0.786443
# Freq: M, dtype: float64
print(ts.shift(2, freq='M')) #时间增加了2个月
# 2012-03-31 0.019028
# 2012-04-30 -0.943761
# 2012-05-31 0.640573
# 2012-06-30 -0.786443
# Freq: M, dtype: float64
#使用偏移量来移动日期, MonthEnd 到月份的最后一天
from pandas.tseries.offsets import Day, MonthEnd
now = datetime(2011,11,17)
print(now+ 3*Day()) #2011-11-20 00:00:00
print(now+ MonthEnd()) # 2011-11-30 00:00:00 到本月的最后一天
print(now+ MonthEnd(2)) # 2011-12-31 00:00:00 在其基础上增加1 个月
offset = MonthEnd()
print(offset.rollforward(now)) # 2011-11-30 00:00:00 向前滚动, 时间增加
print(offset.rollback(now)) # 2011-10-31 00:00:00
#日期偏移用法与groupby一起使用
ts = pd.Series(np.random.randn(20),
index = pd.date_range('1/15/2000',periods =20,freq='4D'))
print(ts.groupby(offset.rollforward).mean()) #计算每个月的平均值
# 2000-01-31 -0.075914
# 2000-02-29 -0.641551
# 2000-03-31 0.349022
# dtype: float64
#一个简单便捷的方法是 使用resample
print(ts.resample('M').mean())
# 2000-01-31 -0.075914
# 2000-02-29 -0.641551
# 2000-03-31 0.349022
# Freq: M, dtype: float64
时区处理
格林威治标准时间GMT
十七世纪,格林威治皇家天文台为了海上霸权的扩张计画而进行天体观测。1675年旧皇家观测所(Old Royal Observatory) 正式成立,到了1884年决定以通过格林威治的子午线作为划分地球东西两半球的经度零度。观测所门口墙上有一个标志24小时的时钟,显示当下的时间,对全球而言,这里所设定的时间是世界时间参考点,全球都以格林威治的时间作为标准来设定时间,这就是我们耳熟能详的「格林威治标准时间」(Greenwich Mean Time,简称G.M.T.)的由来,标示在手表上,则代表此表具有两地时间功能,也就是同时可以显示原居地和另一个国度的时间。
世界协调时间UTC
多数的两地时间表都以GMT来表示,但也有些两地时间表上看不到GMT字样,出现的反而是UTC这3个英文字母,究竟何谓UTC?事实上,UTC指的是Coordinated Universal Time- 世界协调时间(又称世界标准时间、世界统一时间),是经过平均太阳时(以格林威治时间GMT为准)、地轴运动修正后的新时标以及以「秒」为单位的国际原子时所综合精算而成的时间,计算过程相当严谨精密,因此若以「世界标准时间」的角度来说,UTC比GMT来得更加精准。其误差值必须保持在0.9秒以内,若大于0.9秒则由位于巴黎的国际地球自转事务中央局发布闰秒,使UTC与地球自转周期一致。所以基本上UTC的本质强调的是比GMT更为精确的世界时间标准,不过对于现行表款来说,GMT与UTC的功能与精确度是没有差别的。
pandas包含了一些pytz的功能, 时区名字可以通过下方方法查找
import pytz
print(pytz.common_timezones[-5:])
# ['US/Eastern', 'US/Hawaii', 'US/Mountain', 'US/Pacific', 'UTC']
#获得一个时区对象,使用timezone
tz = pytz.timezone('America/New_York')
print(tz)
# <DstTzInfo 'America/New_York' LMT-1 day, 19:04:00 STD>#时区定位和转换
import pandas as pd
import numpy as np
np.random.seed(666)
index = pd.date_range('3/9/2012 9:30', periods = 6, freq = 'D')
ts = pd.Series(np.random.randn(len(index)), index = index)
print(ts)
# 2012-03-09 09:30:00 0.824188
# 2012-03-10 09:30:00 0.479966
# 2012-03-11 09:30:00 1.173468
# 2012-03-12 09:30:00 0.909048
# 2012-03-13 09:30:00 -0.571721
# 2012-03-14 09:30:00 -0.109497
# Freq: D, dtype: float64
print(ts.index.tz) # None tz表示时区 tz= ‘UTC’世界协调时间
ts_utc = ts.tz_localize('UTC') #使用tz_localize 方法可以从朴素到本地化的转变
print(ts_utc)
# 2012-03-09 09:30:00+00:00 0.824188
# 2012-03-10 09:30:00+00:00 0.479966
# 2012-03-11 09:30:00+00:00 1.173468
# 2012-03-12 09:30:00+00:00 0.909048
# 2012-03-13 09:30:00+00:00 -0.571721
# 2012-03-14 09:30:00+00:00 -0.109497
# Freq: D, dtype: float64
#一旦时间被定位到某个时区, 它就可以转换到任何的其他时区,使用tz_convert
print(ts_utc.tz_convert('America/New_York')) #转换到纽约的时间
# 2012-03-09 04:30:00-05:00 0.824188
# 2012-03-10 04:30:00-05:00 0.479966
# 2012-03-11 05:30:00-04:00 1.173468
# 2012-03-12 05:30:00-04:00 0.909048
# 2012-03-13 05:30:00-04:00 -0.571721
# 2012-03-14 05:30:00-04:00 -0.109497
# Freq: D, dtype: float64
#处理时间序列的时候, 我们可以把时间定位到纽约时间, 然后在转到柏林时间
ts_eastern = ts.tz_localize('America/New_York')
# print(ts_eastern)
print(ts_eastern.tz_convert('UTC'))
# 2012-03-09 14:30:00+00:00 0.824188
# 2012-03-10 14:30:00+00:00 0.479966
# 2012-03-11 13:30:00+00:00 1.173468
# 2012-03-12 13:30:00+00:00 0.909048
# 2012-03-13 13:30:00+00:00 -0.571721
# 2012-03-14 13:30:00+00:00 -0.109497
# Freq: D, dtype: float64
print(ts_eastern.tz_convert('Europe/Berlin')) #转换成柏林时间
# 2012-03-09 15:30:00+01:00 0.824188
# 2012-03-10 15:30:00+01:00 0.479966
# 2012-03-11 14:30:00+01:00 1.173468
# 2012-03-12 14:30:00+01:00 0.909048
# 2012-03-13 14:30:00+01:00 -0.571721
# 2012-03-14 14:30:00+01:00 -0.109497
# Freq: D, dtype: float64
#tz_localize 和 tz_convert 方法也是 DatetimeIndex 的实例方法
print(ts.index.tz_localize('Asia/Shanghai'))
# DatetimeIndex(['2012-03-09 09:30:00+08:00', '2012-03-10 09:30:00+08:00',
# '2012-03-11 09:30:00+08:00', '2012-03-12 09:30:00+08:00',
# '2012-03-13 09:30:00+08:00', '2012-03-14 09:30:00+08:00'],
# dtype='datetime64[ns, Asia/Shanghai]', freq='D')
#单独的时间戳对象将本地化转换为有时区的日期
stamp = pd.Timestamp('2011-03-12 04:00')
stamp_utc = stamp.tz_localize('UTC')
print(stamp_utc.tz_convert('America/New_York')) # 2011-03-11 23:00:00-05:00 转换成纽约时间
#创建时间戳的时候, 也可以传递时区
stamp_moscow = pd.Timestamp('2011-03-12 04:00', tz= 'Europe/Moscow')
print(stamp_moscow) # 2011-03-12 04:00:00+03:00
#在使用pandas的 DateOffset对象进行运算时,如果夏令时存在, pandas也是会考虑进去的
from pandas.tseries.offsets import Hour
stamp = pd.Timestamp('2012-11-04 00:30', tz = 'US/Eastern')
print(stamp) # 2012-11-04 00:30:00-04:00
print(stamp + Hour(2)) # 2012-11-04 01:30:00-05:00如果两个不同时区序列被合并, 那么结果就是UTC
In [5]:
import pandas as pd
import numpy as np
np.random.seed(666)
rng = pd.date_range('3/7/2012 9:30', periods =10, freq = 'B')
ts = pd.Series(np.random.randn(len(rng)), index = rng)
ts
Out[5]:
2012-03-07 09:30:00 0.824188
2012-03-08 09:30:00 0.479966
2012-03-09 09:30:00 1.173468
2012-03-12 09:30:00 0.909048
2012-03-13 09:30:00 -0.571721
2012-03-14 09:30:00 -0.109497
2012-03-15 09:30:00 0.019028
2012-03-16 09:30:00 -0.943761
2012-03-19 09:30:00 0.640573
2012-03-20 09:30:00 -0.786443
Freq: B, dtype: float64
In [8]:
ts1 = ts[:7].tz_localize('Europe/London')
ts2 = ts1[2:].tz_convert('Europe/Moscow')
result = ts1 + ts2
result.index
Out[8]:
DatetimeIndex(['2012-03-07 09:30:00+00:00', '2012-03-08 09:30:00+00:00',
'2012-03-09 09:30:00+00:00', '2012-03-12 09:30:00+00:00',
'2012-03-13 09:30:00+00:00', '2012-03-14 09:30:00+00:00',
'2012-03-15 09:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='B')时期及其算术运算
Periods(周期)表示时间跨度(timespans),比如天,月,季,年。Period类表示的就是这种数据类型,构建的时候需要用字符串或整数,以及一个频度
#coding=gbk
#周期和周期计算
import pandas as pd
import numpy as np
p = pd.Period(2007, freq = 'A-DEC') # dec表示12 月份
print(p) # 2007 这个period对象代表了整个2007年一年的跨度,在period上加减, 会有和频度进行shift一样的效果
print(p +5) # 2012
#固定范围的周期,可以使用period_range 创建
rng = pd.period_range('2000-01-01', '2000-06-03', freq= 'M')
print(rng)
# PeriodIndex(['2000-01', '2000-02', '2000-03', '2000-04', '2000-05', '2000-06'], dtype='period[M]', freq='M')
np.random.seed(666)
ts = pd.Series(np.random.randn(len(rng)), index = rng)
print(ts)
# 2000-01 0.824188
# 2000-02 0.479966
# 2000-03 1.173468
# 2000-04 0.909048
# 2000-05 -0.571721
# 2000-06 -0.109497
# Freq: M, dtype: float64
#由字符串组成的数组,也可以使用PeriodIndex 类
values = ['2012Q1','2012Q2','2012Q3']
index = pd.PeriodIndex(values, freq= 'Q-DEC')
print(index)
# PeriodIndex(['2012Q1', '2012Q2', '2012Q3'], dtype='period[Q-DEC]', freq='Q-DEC')
#周期频度转换,使用asfreq方法可以是Periods和PeriodIndex 对象转换成其他频度 年度周期为annual period 所以以A 开头
p =pd.Period('2007',freq= 'A-DEC')
p1 = p.asfreq('M', how='start') #将其频度转换成月份, 开始时间为1 月份
print(p1) # 2007-01
print(p.asfreq('M','end')) # 2007-12 也可以不用写how
p_jun = pd.Period('2007',freq= 'A-JUN')
print(p_jun)
print(p_jun.asfreq('M','start')) # 2006-07
print(p_jun.asfreq('M','end')) # 2007-06 时间跨度为1年, 结束为 6月
季度周期频率, pandas支持12个周期的频度, 从Q-JAN 到 Q-DEC

#季度周期频率, pandas支持12个周期的频度, 从Q-JAN 到 Q-DEC
p =pd.Period('2012Q4',freq='Q-JAN') #表示以2012年 1 月为季度的最后一天
print(p) #2012Q4
print(p.asfreq('D','start')) # 2011-11-01
print(p.asfreq('D','end')) # 2012-01-31 改变周期频率为天,
#时间戳和周期相互转换,可以使用to_period 转换成周期, 使用to_timestamp 转换成时间戳
rng= pd.date_range('1/29/2000',periods =6, freq='D')
ts = pd.Series(np.random.randn(6), index=rng)
print(ts)
# 2000-01-29 0.019028
# 2000-01-30 -0.943761
# 2000-01-31 0.640573
# 2000-02-01 -0.786443
# 2000-02-02 0.608870
# 2000-02-03 -0.931012
# Freq: D, dtype: float64
print(ts.to_period('M')) #转换成周期,频率为月
# 2000-01 0.019028
# 2000-01 -0.943761
# 2000-01 0.640573
# 2000-02 -0.786443
# 2000-02 0.608870
# 2000-02 -0.931012
# Freq: M, dtype: float64
pts = ts.to_period()
print(pts.to_timestamp())从数组中创建一个周期索引
In [10]:
data = pd.read_csv(r'D:\datasets\macrodata.csv')
data.head()
Out[10]:
year quarter realgdp realcons realinv realgovt realdpi cpi m1 tbilrate unemp pop infl realint
0 1959.0 1.0 2710.349 1707.4 286.898 470.045 1886.9 28.98 139.7 2.82 5.8 177.146 0.00 0.00
1 1959.0 2.0 2778.801 1733.7 310.859 481.301 1919.7 29.15 141.7 3.08 5.1 177.830 2.34 0.74
2 1959.0 3.0 2775.488 1751.8 289.226 491.260 1916.4 29.35 140.5 3.82 5.3 178.657 2.74 1.09
3 1959.0 4.0 2785.204 1753.7 299.356 484.052 1931.3 29.37 140.0 4.33 5.6 179.386 0.27 4.06
4 1960.0 1.0 2847.699 1770.5 331.722 462.199 1955.5 29.54 139.6 3.50 5.2 180.007 2.31 1.19
In [11]:
data.year[:5]
Out[11]:
0 1959.0
1 1959.0
2 1959.0
3 1959.0
4 1960.0
Name: year, dtype: float64
In [12]:
data['quarter'][:5]
Out[12]:
0 1.0
1 2.0
2 3.0
3 4.0
4 1.0
Name: quarter, dtype: float64
In [13]:
index = pd.PeriodIndex(year=data.year, quarter =data.quarter, freq='Q-DEC')
index
Out[13]:
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='period[Q-DEC]', length=203, freq='Q-DEC')
In [14]:
data.index= index
data.index= index
In [15]:
data.head()
Out[15]:
year quarter realgdp realcons realinv realgovt realdpi cpi m1 tbilrate unemp pop infl realint
1959Q1 1959.0 1.0 2710.349 1707.4 286.898 470.045 1886.9 28.98 139.7 2.82 5.8 177.146 0.00 0.00
1959Q2 1959.0 2.0 2778.801 1733.7 310.859 481.301 1919.7 29.15 141.7 3.08 5.1 177.830 2.34 0.74
1959Q3 1959.0 3.0 2775.488 1751.8 289.226 491.260 1916.4 29.35 140.5 3.82 5.3 178.657 2.74 1.09
1959Q4 1959.0 4.0 2785.204 1753.7 299.356 484.052 1931.3 29.37 140.0 4.33 5.6 179.386 0.27 4.06
1960Q1 1960.0 1.0 2847.699 1770.5 331.722 462.199 1955.5 29.54 139.6 3.50 5.2 180.007 2.31 1.19
In [16]:
data.infl[:5]
Out[16]:
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
Freq: Q-DEC, Name: infl, dtype: float64重采样及频率转换
重采样(Resampling)指的是把时间序列的频度变为另一个频度的过程。把高频度的数据变为低频度叫做降采样(downsampling),把低频度变为高频度叫做增采样(upsampling)。并不是所有的重采样都会落入上面这几个类型,例如,把W-WED(weekly on Wednesday)变为W-FRI,既不属于降采样,也不属于增采样。
#pandas对象自带的resample方法,可以用于所有的频度的变化。我们可以使用resample对数据进行分组,类似于groupby,然后调用聚合函数
import pandas as pd
import numpy as np
np.random.seed(666)
rng = pd.date_range('2000-01-01', periods = 100, freq='D')
ts = pd.Series(np.random.randn(100), index=rng)
print(ts.head()) #打印出数据前5项
# 2000-01-01 0.824188
# 2000-01-02 0.479966
# 2000-01-03 1.173468
# 2000-01-04 0.909048
# 2000-01-05 -0.571721
# Freq: D, dtype: float64
print(ts[-2:]) #可以看到数据是从 1月到 4月
# 2000-04-08 1.133356
# 2000-04-09 1.722047
# Freq: D, dtype: float64
print(ts.resample('M').mean()) #输出每个月 的数据的平均数
# 2000-01-31 -0.036904
# 2000-02-29 -0.039269
# 2000-03-31 -0.016232
# 2000-04-30 0.202995
# Freq: M, dtype: float64
print(ts.resample('M',kind='period').mean()) #这种显示的数据比较准确, 使用period
# 2000-01 -0.036904
# 2000-02 -0.039269
# 2000-03 -0.016232
# 2000-04 0.202995
# Freq: M, dtype: float64
降采样:
把数据聚合为规律、低频度是一个很普通的时间序列任务。用于处理的数据不必是有固定频度的;我们想要设定的频度会定义箱界(bin edges),根据bin edges会把时间序列分割为多个片段,然后进行聚合。例如,转换为月度,比如'M'或'BM',我们需要把数据以月为间隔进行切割。每一个间隔都是半开放的(half-open);一个数据点只能属于一个间隔,所有间隔的合集,构成整个时间范围(time frame)。当使用resample去降采样数据的时候,有很多事情需要考虑:
- 在每个间隔里,哪一边要闭合
- 怎样对每一个聚合的bin贴标签,可以使用间隔的开始或结束
rng1 = pd.date_range('2000-01-01', periods =12, freq='T') # 频率是 分钟
ts1 = pd.Series(np.arange(12), index=rng1)
print(ts1)
# 2000-01-01 00:00:00 0
# 2000-01-01 00:01:00 1
# 2000-01-01 00:02:00 2
# 2000-01-01 00:03:00 3
# 2000-01-01 00:04:00 4
# 2000-01-01 00:05:00 5
# 2000-01-01 00:06:00 6
# 2000-01-01 00:07:00 7
# 2000-01-01 00:08:00 8
# 2000-01-01 00:09:00 9
# 2000-01-01 00:10:00 10
# 2000-01-01 00:11:00 11
# Freq: T, dtype: int32
print(ts1.resample('5min', closed='right').sum()) #closed表示, 右边界为闭合的
# 1999-12-31 23:55:00 0
# 2000-01-01 00:00:00 15
# 2000-01-01 00:05:00 40
# 2000-01-01 00:10:00 11
# Freq: 5T, dtype: int32
print(ts1.resample('5min',closed='right', label='right').mean()) # 输出显示为右边界的时间
# 2000-01-01 00:00:00 0
# 2000-01-01 00:05:00 3
# 2000-01-01 00:10:00 8
# 2000-01-01 00:15:00 11
# Freq: 5T, dtype: int32

我们可能想要对结果的索引进行位移,比如在右边界减少一秒。想要实现的话,传递一个字符串或日期偏移给loffset:
#对时间索引进行偏移 也可以使用shift
print(ts1.resample('5min', closed='right', label='right', loffset='-1s').sum())
# 1999-12-31 23:59:59 0
# 2000-01-01 00:04:59 15
# 2000-01-01 00:09:59 40
# 2000-01-01 00:14:59 11
# Freq: 5T, dtype: int32
#股价图重采样, open-high-low-close 开盘-盘高-盘低-收盘图,可以使用ohlc聚合函数
print(ts1.resample('5min').ohlc())
# open high low close
# 2000-01-01 00:00:00 0 4 0 4
# 2000-01-01 00:05:00 5 9 5 9
# 2000-01-01 00:10:00 10 11 10 11增采样和插值
frame = pd.DataFrame(np.random.randn(2,4), index = pd.date_range('1/1/2000', periods = 2, freq='W-WEd'),
columns = ['Colorado','Texas','New York','Ohio']
)
print(frame)
# Colorado Texas New York Ohio
# 2000-01-05 0.609378 0.590351 -0.634946 1.862890
# 2000-01-12 -0.869812 -0.784517 -0.407707 1.053001
#使用asfreq 方法转换成高频度
print(frame.resample('D').asfreq()) #可以看到中间的都是空值
# Colorado Texas New York Ohio
# 2000-01-05 0.609378 0.590351 -0.634946 1.862890
# 2000-01-06 NaN NaN NaN NaN
# 2000-01-07 NaN NaN NaN NaN
# 2000-01-08 NaN NaN NaN NaN
# 2000-01-09 NaN NaN NaN NaN
# 2000-01-10 NaN NaN NaN NaN
# 2000-01-11 NaN NaN NaN NaN
# 2000-01-12 -0.869812 -0.784517 -0.407707 1.053001
print(frame.resample('D').ffill()) #空值向前填充
# Colorado Texas New York Ohio
# 2000-01-05 0.609378 0.590351 -0.634946 1.862890
# 2000-01-06 0.609378 0.590351 -0.634946 1.862890
# 2000-01-07 0.609378 0.590351 -0.634946 1.862890
# 2000-01-08 0.609378 0.590351 -0.634946 1.862890
# 2000-01-09 0.609378 0.590351 -0.634946 1.862890
# 2000-01-10 0.609378 0.590351 -0.634946 1.862890
# 2000-01-11 0.609378 0.590351 -0.634946 1.862890
# 2000-01-12 -0.869812 -0.784517 -0.407707 1.053001
#使用limit 只对一部分的值进行填充
print(frame.resample('D').ffill(limit=2)) # 只对前2组数据进行填充
# Colorado Texas New York Ohio
# 2000-01-05 0.609378 0.590351 -0.634946 1.862890
# 2000-01-06 0.609378 0.590351 -0.634946 1.862890
# 2000-01-07 0.609378 0.590351 -0.634946 1.862890
# 2000-01-08 NaN NaN NaN NaN
# 2000-01-09 NaN NaN NaN NaN
# 2000-01-10 NaN NaN NaN NaN
# 2000-01-11 NaN NaN NaN NaN
# 2000-01-12 -0.869812 -0.784517 -0.407707 1.053001
print(frame.resample('W-THU').ffill()) # 先对其进行重采样,得到新的2个时间索引,再进行填充
# Colorado Texas New York Ohio
# 2000-01-06 0.609378 0.590351 -0.634946 1.862890
# 2000-01-13 -0.869812 -0.784517 -0.407707 1.053001对周期进行重采样, Resample with Periods,与对时间戳的采样类似
3,对周期进行重采样, Resample with Periods,与对时间戳的采样类似
In [5]:
import pandas as pd
import numpy as np
np.random.seed(666)
frame = pd.DataFrame(np.random.randn(24,4), index=pd.period_range('1-2000','12-2001', freq='M'),columns = ['Colorado','Texas','New York','Ohio'])
frame.head()
import pandas as pd
import numpy as np
np.random.seed(666)
frame = pd.DataFrame(np.random.randn(24,4), index=pd.period_range('1-2000','12-2001', freq='M'),columns = ['Colorado','Texas','New York','Ohio'])
frame.head()
Out[5]:
Colorado Texas New York Ohio
2000-01 0.824188 0.479966 1.173468 0.909048
2000-02 -0.571721 -0.109497 0.019028 -0.943761
2000-03 0.640573 -0.786443 0.608870 -0.931012
2000-04 0.978222 -0.736918 -0.298733 -0.460587
2000-05 -1.088793 -0.575771 -1.682901 0.229185
In [7]:
annual_frame = frame.resample('A-DEC').mean()
annual_frame
Out[7]:
Colorado Texas New York Ohio
2000 -0.276404 -0.138994 0.178313 -0.011416
2001 -0.492031 0.289169 -0.391047 0.606910
In [9]:
frame.resample('Q-DEC').sum()
Out[9]:
Colorado Texas New York Ohio
2000Q1 0.893040 -0.415974 1.801366 -0.965725
2000Q2 -1.867196 -0.468056 -1.704414 0.621499
2000Q3 -0.487948 0.279374 1.139782 -0.154590
2000Q4 -1.854748 -1.063268 0.903022 0.361829
2001Q1 -0.800493 -0.203703 -1.119238 2.822614
2001Q2 -2.204521 4.670230 -0.892122 0.143998
2001Q3 -0.308845 0.417768 0.554051 2.939952
2001Q4 -2.590509 -1.414267 -3.235256 1.376360
In [12]:
frame.resample('Q-DEC', convention='start').sum()
Out[12]:
Colorado Texas New York Ohio
2000Q1 0.893040 -0.415974 1.801366 -0.965725
2000Q2 -1.867196 -0.468056 -1.704414 0.621499
2000Q3 -0.487948 0.279374 1.139782 -0.154590
2000Q4 -1.854748 -1.063268 0.903022 0.361829
2001Q1 -0.800493 -0.203703 -1.119238 2.822614
2001Q2 -2.204521 4.670230 -0.892122 0.143998
2001Q3 -0.308845 0.417768 0.554051 2.939952
2001Q4 -2.590509 -1.414267 -3.235256 1.376360移动窗口函数
一种用于时间序列操作的重要用法,是使用滑窗(sliding windown)或呈指数降低的权重(exponentially decaying weights),来对时间序列进行统计值计算和其他一些函数计算。 这个对于消除噪声或有缺陷的数据是很有用的。这里我们称之为Moving Window Functions(移动窗口函数),不过其中也包括了不适用固定长度窗口的函数(functions without a fixed-length window),比如指数加权移动平均数(exponentially weighted moving average)。和其他一些统计函数以后,这些函数也会自动无视缺失值。
移动窗口函数
In [13]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
In [14]:
%matplotlib inline
In [16]:
close_px_all = pd.read_csv(r'D:\datasets\stock_px_2.csv', index_col=0, parse_dates= True)
close_px = close_px_all[['AAPL','MSFT','XOM']]
close_px.head()
Out[16]:
AAPL MSFT XOM
2003-01-02 7.40 21.11 29.22
2003-01-03 7.45 21.14 29.24
2003-01-06 7.45 21.52 29.96
2003-01-07 7.43 21.93 28.95
2003-01-08 7.28 21.31 28.83
In [19]:
close_px = close_px.resample('B').ffill()
close_px.head(10)
Out[19]:
AAPL MSFT XOM
2003-01-02 7.40 21.11 29.22
2003-01-03 7.45 21.14 29.24
2003-01-06 7.45 21.52 29.96
2003-01-07 7.43 21.93 28.95
2003-01-08 7.28 21.31 28.83
2003-01-09 7.34 21.93 29.44
2003-01-10 7.36 21.97 29.03
2003-01-13 7.32 22.16 28.91
2003-01-14 7.30 22.39 29.17
2003-01-15 7.22 22.11 28.77
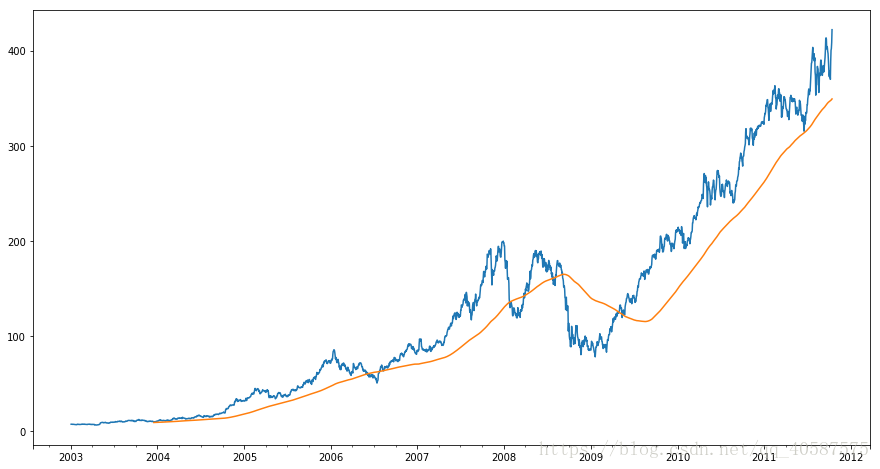
rolling(250) 是创建了一个新的对象,并在一个有250天的滑窗上进行分组,得到一个250天的移动滑窗平均值
In [22]:
close_px.AAPL.plot()
close_px.AAPL.rolling(250).mean().plot(figsize=(15,8))
apple_stad250 = close_px.AAPL.rolling(250, min_periods=10).std()#前9项不计算
apple_stad250[0:12]
Out[26]:
2003-01-02 NaN
2003-01-03 NaN
2003-01-06 NaN
2003-01-07 NaN
2003-01-08 NaN
2003-01-09 NaN
2003-01-10 NaN
2003-01-13 NaN
2003-01-14 NaN
2003-01-15 0.077496
2003-01-16 0.074760
2003-01-17 0.112368
Freq: B, Name: AAPL, dtype: float64
In [29]:
apple_stad250.plot(figsize=(15,8)) #计算标注差
Out[29]:
<matplotlib.axes._subplots.AxesSubplot at 0x8f78400>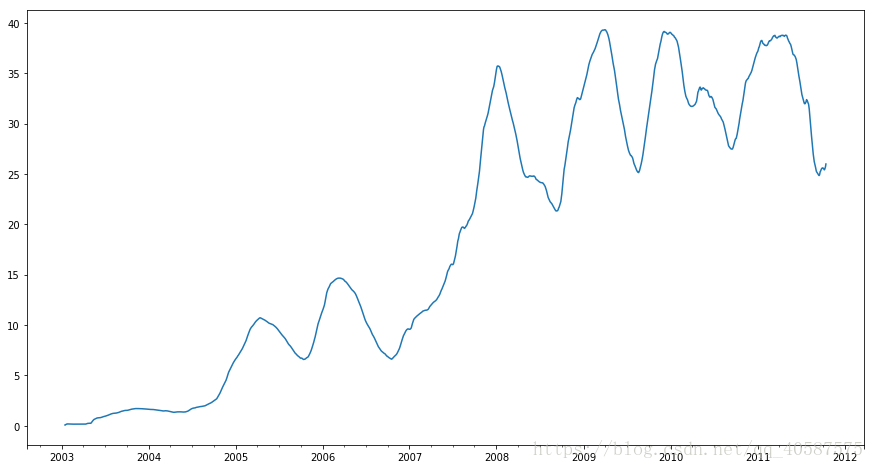
为了计算扩张窗口平均(expanding window mean),我们要使用expanding操作符,而不是用rolling。这个扩张平均的时间窗口是从时间序列开始的地方作为开始,窗口的大小会逐渐递增,直到包含整个序列。一个扩张窗口平均在时间序列上的计算像下面这样,我们拿apple_std250来做例子:
In [45]:
expanding_mean = apple_stad250.expanding().mean()
close_px.rolling(60).mean().plot(logy=True, figsize=(15,8))
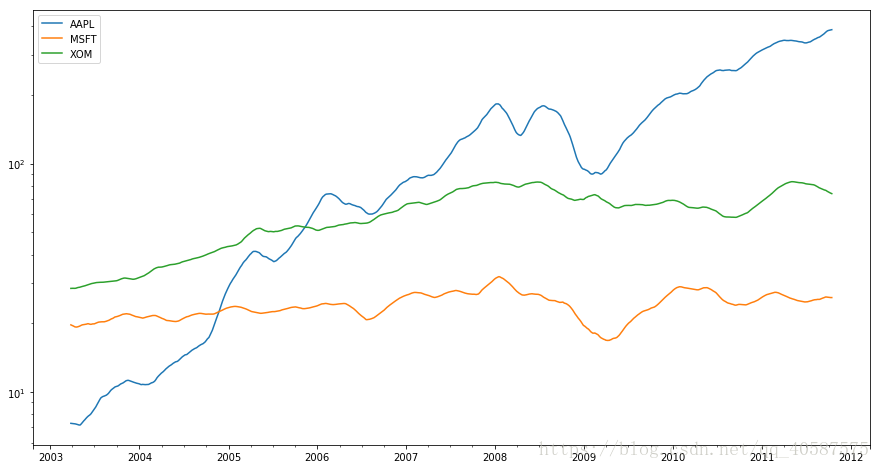
计算一个20天的滑动平均
In [32]:
rolling_mean = close_px.rolling('20D').mean()
print(rolling_mean.head())
print(rolling_mean.tail())
AAPL MSFT XOM
2003-01-02 7.400000 21.110000 29.220000
2003-01-03 7.425000 21.125000 29.230000
2003-01-06 7.433333 21.256667 29.473333
2003-01-07 7.432500 21.425000 29.342500
2003-01-08 7.402000 21.402000 29.240000
AAPL MSFT XOM
2011-10-10 389.351429 25.602143 72.527857
2011-10-11 388.505000 25.674286 72.835000
2011-10-12 388.531429 25.810000 73.400714
2011-10-13 388.826429 25.961429 73.905000
2011-10-14 391.038000 26.048667 74.185333
指数权重函数
pandas有一个ewm操作符,可以与rolling和expanding一起使用。这里有一个例子,在设置EW移动平均(moving average)为span=60的情况下,比较苹果股价的60天移动平均:
In [33]:
appl_px = close_px.AAPL['2006':'2007']
appl_px = close_px.AAPL['2006':'2007']
In [34]:
ma60 = appl_px.rolling(30, min_periods=20).mean()
ewma60 = appl_px.ewm(span=30).mean()
In [39]:
ma60.plot(style='k--',label='Simple MA', figsize=(15,8))
ewma60.plot(style='k-', label='EW MA', figsize=(15,8))
plt.legend()
Out[39]:
<matplotlib.legend.Legend at 0xb878b38>
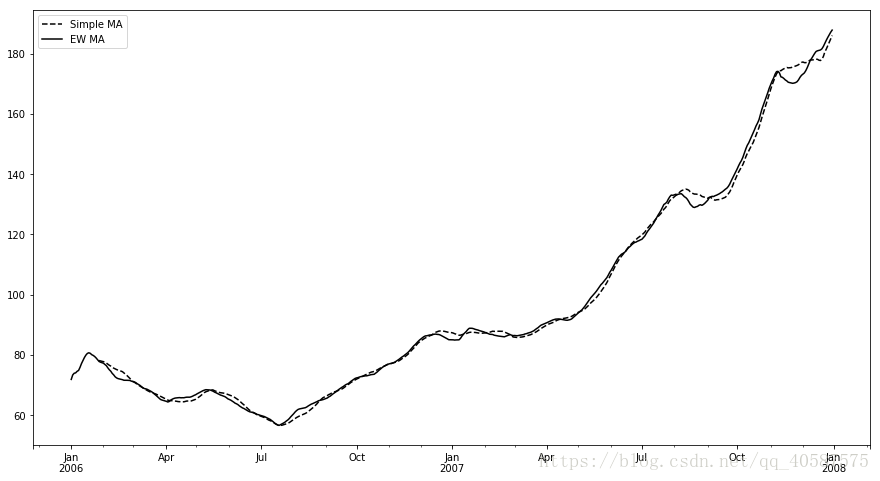
二元移动窗口函数
一些统计计算符,比如相关性和协方差,需要在两个时间序列上进行计算。例如,经济分析通常喜欢比较一只股票与基础指数标普500之间的相关性。我们先计算一下时间序列的百分比变化:
In [40]:
spx_px = close_px_all['SPX']#spx为标普500
spx_rets = spx_px.pct_change()
returns = close_px.pct_change()
In [42]:
corr = returns.AAPL.rolling(125, min_periods=100).corr(spx_rets)
corr.plot(figsize=(15,8))
Out[42]:
<matplotlib.axes._subplots.AxesSubplot at 0xc3d8ba8>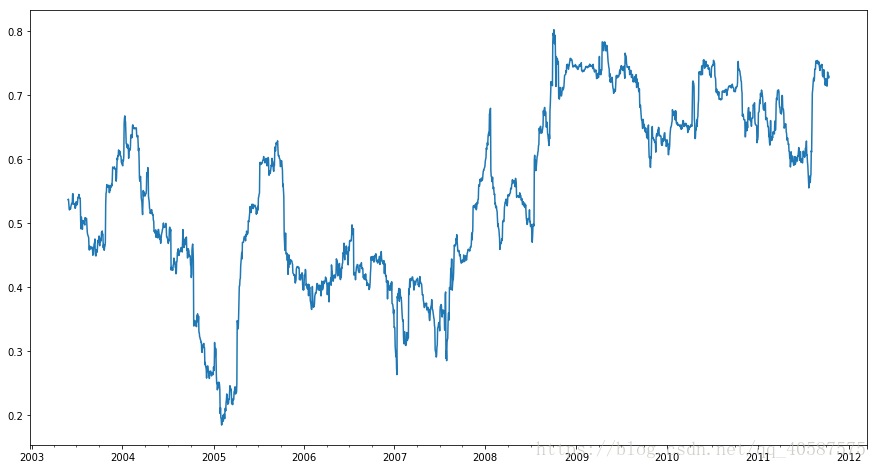
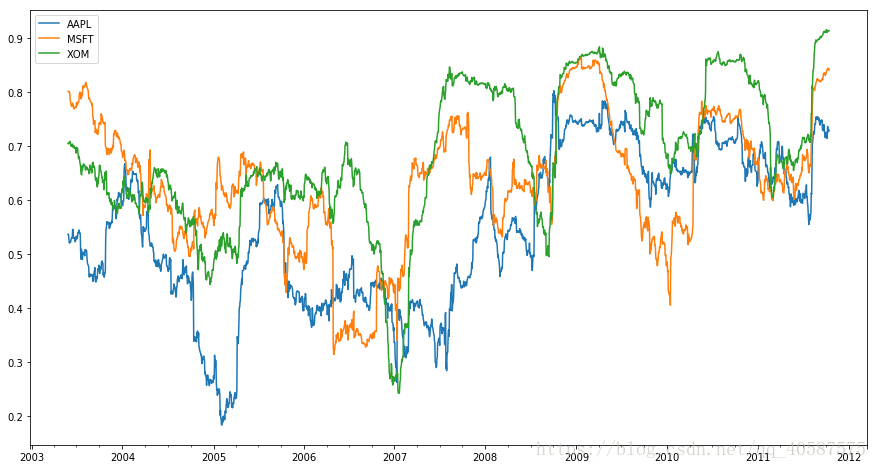
假设我们想要一次计算很多股票与标普500指数的相关性。写一个循环,创建一个新的DataFrame虽然简单但是重复性高,所以我们可以传入一个Series和DataFrame,然后用rolling_corr这样的函数来计算每一列与Series的相关性(在这里例子里,Series指的是spx_rets):
In [44]:
corr = returns.rolling(125,min_periods=100).corr(spx_rets)
corr.plot(figsize=(15,8))
corr = returns.rolling(125,min_periods=100).corr(spx_rets)
corr.plot(figsize=(15,8))
Out[44]:
<matplotlib.axes._subplots.AxesSubplot at 0xb878d68>