五、重采样与频率转换
1. resample方法
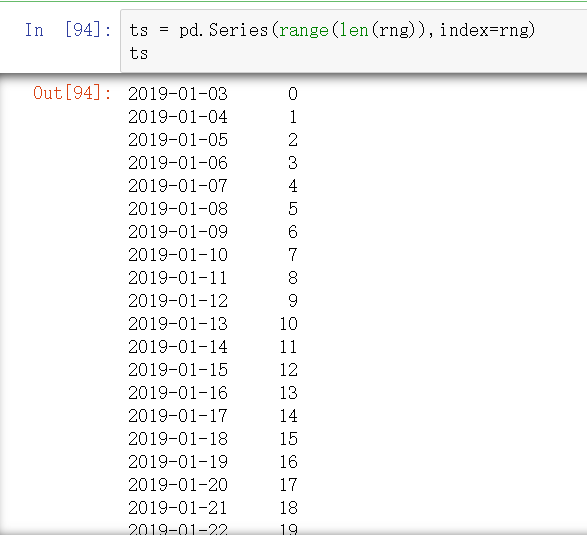
rng = pd.date_range('1/3/2019',periods=1000,freq='D')
rng

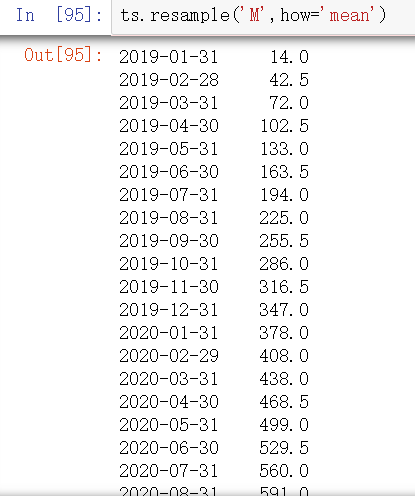
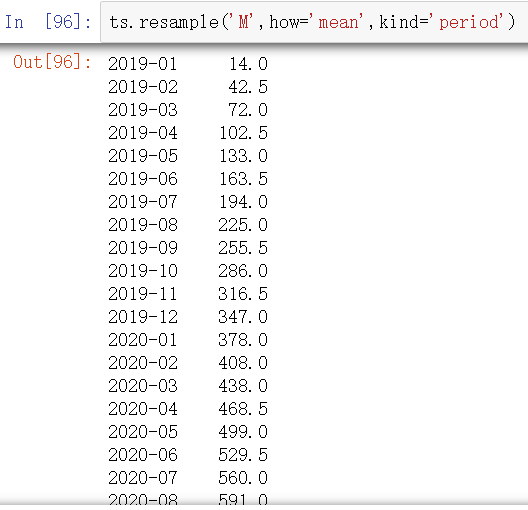


2. 降采样
(1)resample将高频率数据聚合到低频率
举例:已知:‘1分钟’数据,想要通过求和的方式将这些数据聚合到“5分钟”块中
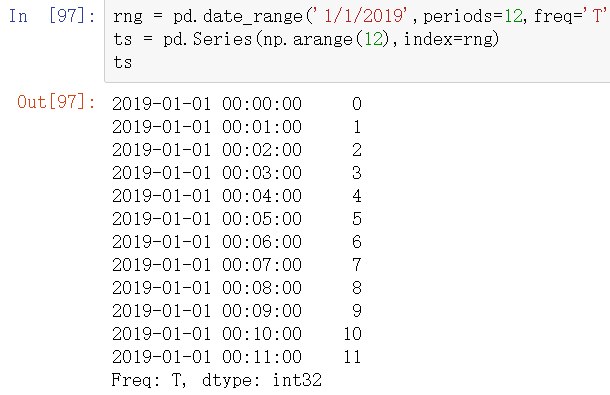
left:[0:5)、[5:10)、[10-15)
right :(0:5]、(5:10]、(10-15]
传入的频率将会以“5分钟”的增量定义面元边界。默认情况下,面元的右边界是包含的,因此00:00到00:05的区间中是包含00:05的。传入colsed='left'会让区间以左边界闭合:
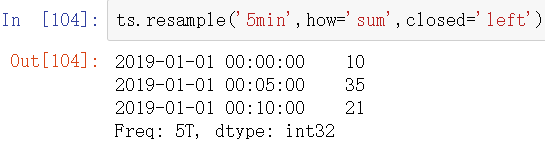
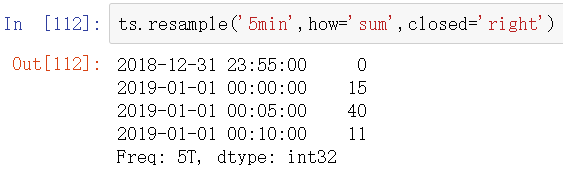
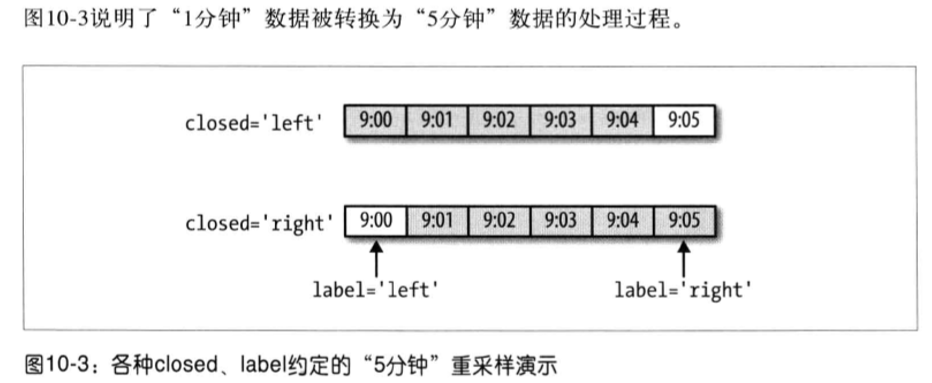
最后,你可以希望对结果索引做一些位移,比如从右边界减去一秒以便更容易明白该时间戳到底表示的是哪个区间。通过loffset设置一个字符串或日期片质量即可实现:

(2)通过groupby进行重采样


3. 上采样与插值
将低频率数据转换到高频率,就不需要聚合了

将其重采样到日频率,默认会引入缺失值
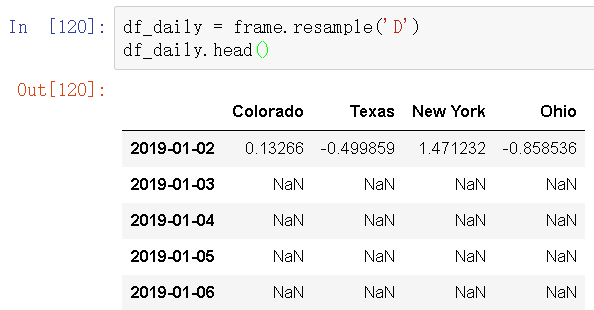
如果你想要用前面的周型值填充“非星期三”。resampling的填充和插值方式跟fillna和reindex的一样。
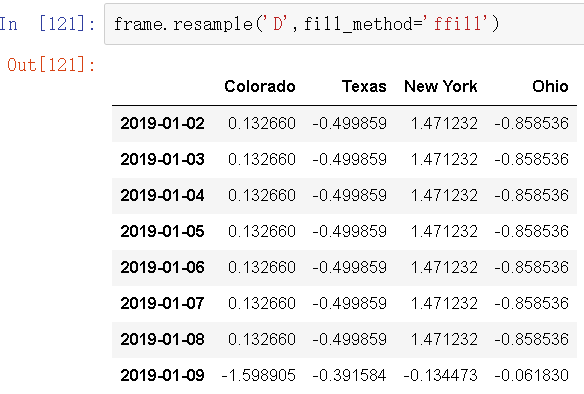
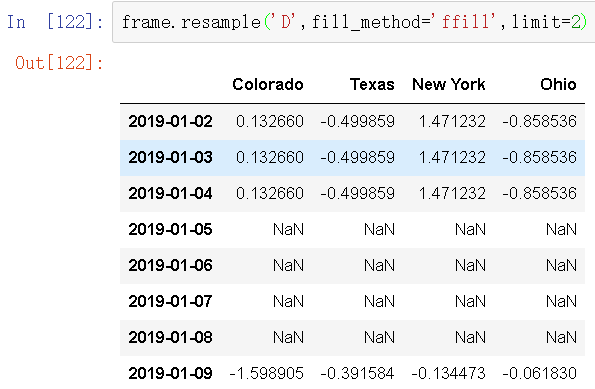
同时,这里可以只填充指定的日期数(目的是限制前面的观察值的持续使用距离)。
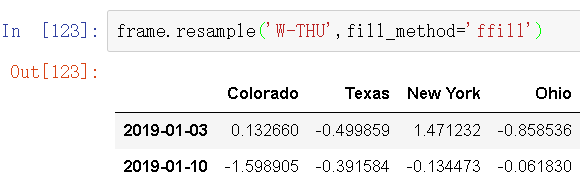
注意,新的日期索引完全没必要和旧的相交:
4. 通过日期进行重采样
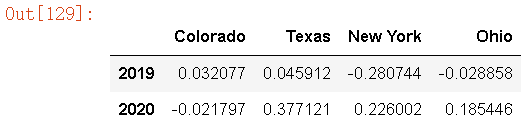
(1)降采样

annual_frame = frame.resample('A-DEC',how='mean')
annual_frame
(2)上采样
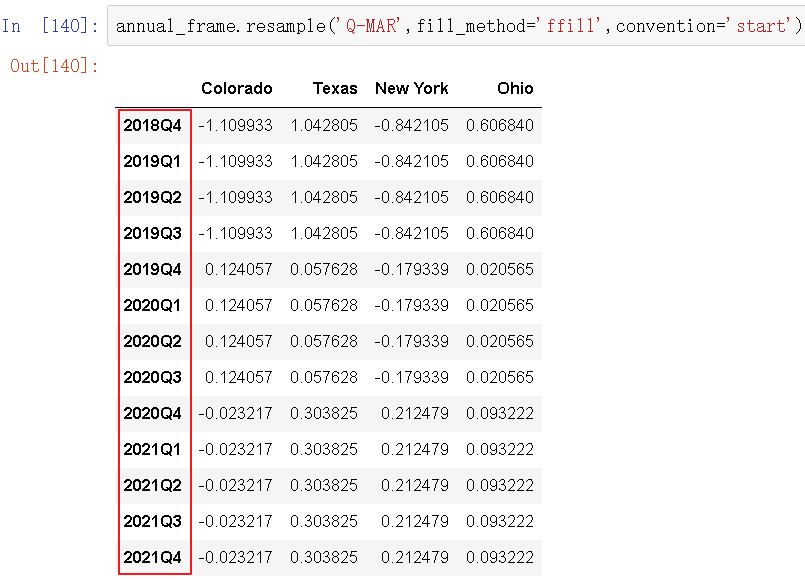
上采样必须要决定在新频率中各区间的哪段用于放置原来的值,就像asfreq方法那样。convention参数默认为'end',可设置为'start':
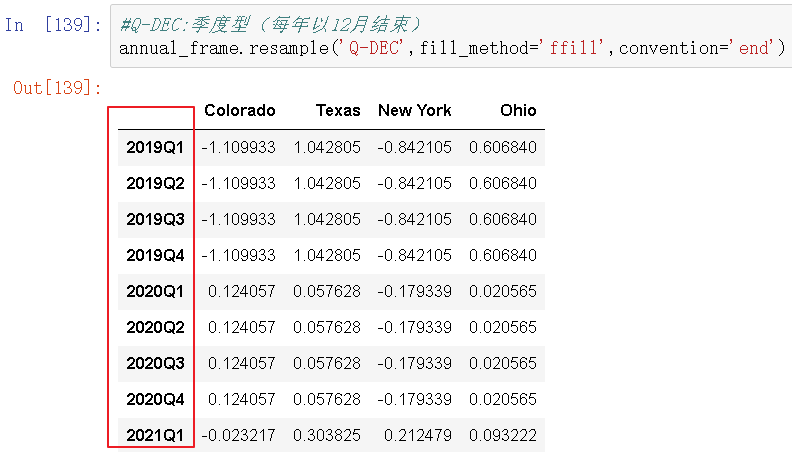
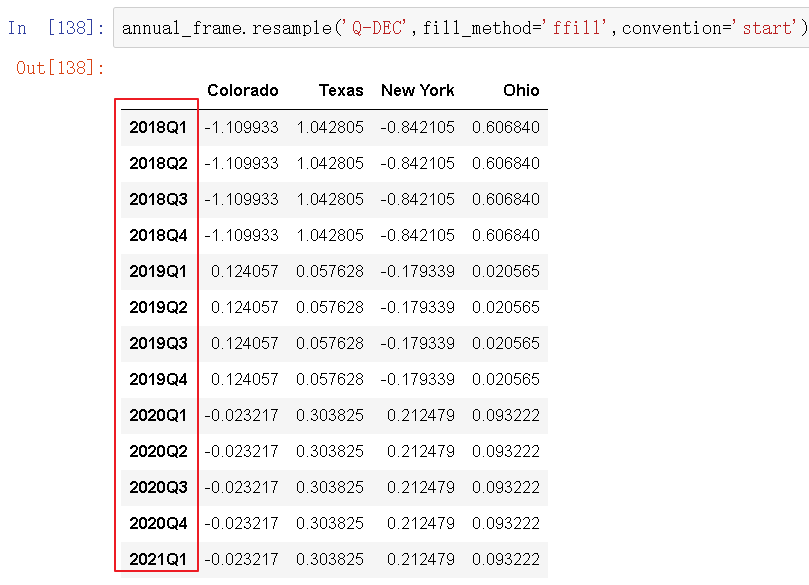
由于时期指的是时间区间,所以上采样和降采样的规则就比较严格:
- 在降采样中,目标频率必须是源频率的子时期(subperiod);
- 在上采样中,目标频率必须是源频率的超时期(superperiod)
如果不满足这些条件,就会发生异常。这主要影响的是按季、年、周计算的频率。例如,由Q-MAR定义的时间区间只能升采样为A-MAR、A-JUN、A-SEP、A-DEC等。