三、开源框架和容器
3.1、SSM/Servlet
Servlet的生命周期(链接)
加载—>实例化—>服务—>销毁
转发与重定向的区别(链接)
一句话,转发是服务器行为,重定向是客户端行为。为什么这样说呢,这就要看两个动作的工作流程:
转发过程:客户浏览器发送http请求----》web服务器接受此请求--》调用内部的一个方法在容器内部完成请求处理和转发动作----》将目标资源发送给客户;在这里,转发的路径必须是同一个web容器下的url,其不能转向到其他的web路径上去,中间传递的是自己的容器内的request。在客户浏览器路径栏显示的仍然是其第一次访问的路径,也就是说客户是感觉不到服务器做了转发的。转发行为是浏览器只做了一次访问请求。
重定向过程:客户浏览器发送http请求----》web服务器接受后发送302状态码响应及对应新的location给客户浏览器--》客户浏览器发现是302响应,则自动再发送一个新的http请求,请求url是新的location地址----》服务器根据此请求寻找资源并发送给客户。在这里location可以重定向到任意URL,既然是浏览器重新发出了请求,则就没有什么request传递的概念了。在客户浏览器路径栏显示的是其重定向的路径,客户可以观察到地址的变化的。重定向行为是浏览器做了至少两次的访问请求的。
BeanFactory 和 ApplicationContext 有什么区别(链接)
,两者都是通过xml配置文件加载bean,ApplicationContext和BeanFacotry相比,提供了更多的扩展功能,但其主要区别在于后者是延迟加载,如果Bean的某一个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才会抛出异常;而ApplicationContext则在初始化自身是检验,这样有利于检查所依赖属性是否注入;所以通常情况下我们选择使用ApplicationContext.
Spring Bean 的生命周期(点击打开链接)
Spring IOC 如何实现(点击打开链接)
java程序中的每个业务逻辑至少需要两个或以上的对象来协作完成,通常,每个对象在使用他的合作对象时,自己均要使用像new object() 这样的语法来完成合作对象的申请工作。你会发现:对象间的耦合度高了。而IOC的思想是:Spring容器来实现这些相互依赖对象的创建、协调工作。对象只需要关系业务逻辑本身就可以了。从这方面来说,对象如何得到他的协作对象的责任被反转了(IOC、DI)。
这是我对Spring的IOC的体会。DI其实就是IOC的另外一种说法。DI是由Martin Fowler 在2004年初的一篇论文中首次提出的。他总结:控制的什么被反转了?就是:获得依赖对象的方式反转了。Spring中Bean的作用域,默认的是哪一个
1.singleton
singleton,也称单例作用域。在每个 Spring IoC 容器中有且只有一个实例,而且其完整生命周期完全由 Spring 容器管理。对于所有获取该 Bean 的操作 Spring 容器将只返回同一个 Bean。
需要注意的是,若一个 Bean 未指定 scope 属性,默认也为 singleton 。
2.prototype
prototype,也称原型作用域。每次向 Spring IoC 容器请求获取 Bean 都返回一个全新的Bean。相对于 singleton 来说就是不缓存 Bean,每次都是一个根据 Bean 定义创建的全新 Bean。
Web 作用域
1.reqeust
request,表示每个请求需要容器创建一个全新Bean。
在 Spring IoC 容器,即XmlWebApplicationContext 会为每个 HTTP 请求创建一个全新的 RequestPrecessor 对象。当请求结束后,该对象的生命周期即告结束。当同时有 10 个 HTTP 请求进来的时候,容器会分别针对这 10 个请求创建 10 个全新的 RequestPrecessor 实例,且他们相互之间互不干扰,从不是很严格的意义上说,request 可以看做 prototype 的一种特例,除了场景更加具体之外,语意上差不多。
2.session
session,表示每个会话需要容器创建一个全新 Bean。比如对于每个用户一般会有一个会话,该用户的用户信息需要存储到会话中,此时可以将该 Bean 配置为 web 作用域。
3.globalSession
globalSession,类似于session 作用域,只是其用于 portlet 环境的 web 应用。如果在非portlet 环境将视为 session 作用域。
说说 Spring AOP、Spring AOP 实现原理(点击打开链接)
AOP技术则恰恰相反,它利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。AOP代表的是一个横向的关系,如果说“对象”是一个空心的圆柱体,其中封装的是对象的属性和行为;那么面向方面编程的方法,就仿佛一把利刃,将这些空心圆柱体剖开,以获得其内部的消息。而剖开的切面,也就是所谓的“方面”了。然后它又以巧夺天功的妙手将这些剖开的切面复原,不留痕迹。
使用“横切”技术,AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处都基本相似。比如权限认证、日志、事务处理。Aop 的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。正如Avanade公司的高级方案构架师Adam Magee所说,AOP的核心思想就是“将应用程序中的商业逻辑同对其提供支持的通用服务进行分离。”
实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码
动态代理(CGLib 与 JDK)、优缺点、性能对比、如何选择(点击打开链接)
JDK动态代理是面向接口,在创建代理实现类时比CGLib要快,创建代理速度快。
CGLib动态代理是通过字节码底层继承要代理类来实现(如果被代理类被final关键字所修饰,那么抱歉会失败),在创建代理这一块没有JDK动态代理快,但是运行速度比JDK动态代理要快。
使用注意:
如果要被代理的对象是个实现类,那么Spring会使用JDK动态代理来完成操作(Spirng默认采用JDK动态代理实现机制)
如果要被代理的对象不是个实现类那么,Spring会强制使用CGLib来实现动态代理。
Spring事务机制是一种典型的策略模式,PlatformTransactionManager代表事务管理接口,但它并不知道到底如何管理事务,它只要求事务管理提供开始事务getTransaction(),提交事务commit()和回滚事务rollback()这三个方法,但具体如何实现则交给其实现类完成。编程人员只需要在配置文件中根据具体需要使用的事务类型做配置,Spring底层就自动会使用具体的事务实现类进行事务操作,而对于程序员来说,完全不需要关心底层过程,只需要面向PlatformTransactionManager接口进行编程即可。PlatformTransactionManager接口中提供了如下方法:getTransaction(..), commit(); rollback(); 这些都是与平台无关的事务操作。
1、TransactionDefinition接口中定义五个隔离级别(isolation):
说明:
脏读:一个事务读取了另一个事务改写但还未提交的数据,如果这些数据被回滚,则读到的数据是无效的。
不可重复读:在同一事务中,多次读取到同一数据的结果有所不同。也就是说,后续读取可以读到另一个事务已经提交的更新数据。
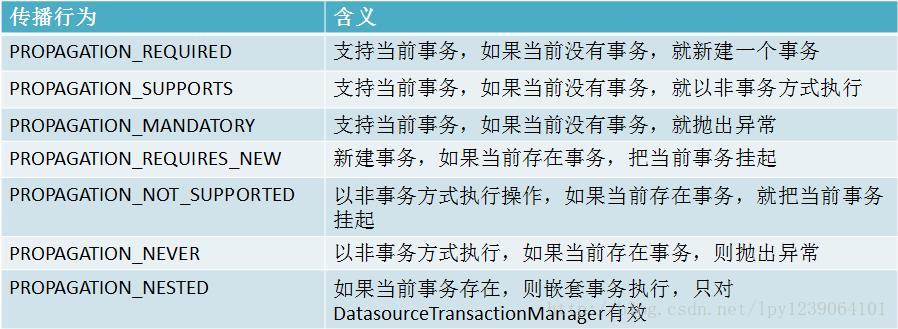
幻读:一个事务读取了几行记录后,另一个事务插入一些记录,幻读就发生了,再查询的时候,第一个事务就会发现有些原来没有的记录。2. 在TransactionDefinition接口中定义了七个事务传播行为(propagationBehavior):
3、TransactionDefinition接口中定义了事务超时
所谓事务超时,就是指一个事务所允许执行的最长时间,如果超过该时间限制但事务还没有完成,则自动回滚事务。在 TransactionDefinition 中以 int 的值来表示超时时间,其单位是秒。
默认设置为底层事务系统的超时值,如果底层数据库事务系统没有设置超时值,那么就是none,没有超时限制。
4、事务只读属性
只读事务用于客户代码只读但不修改数据的情形,只读事务用于特定情景下的优化,比如使用Hibernate的时候,默认为读写事务。隔离级别越高,越能保证数据的完整性和一致性,但是对并发性能的影响也越大。
大多数的数据库默认隔离级别为 Read Commited,比如 SqlServer、Oracle
少数数据库默认隔离级别为:Repeatable Read 比如: MySQL InnoDB
Spring 事务底层原理(点击打开链接)
Spring事务失效(事务嵌套),JDK动态代理给Spring事务埋下的坑,可参考《JDK动态代理给Spring事务埋下的坑!》
如何自定义注解实现功能
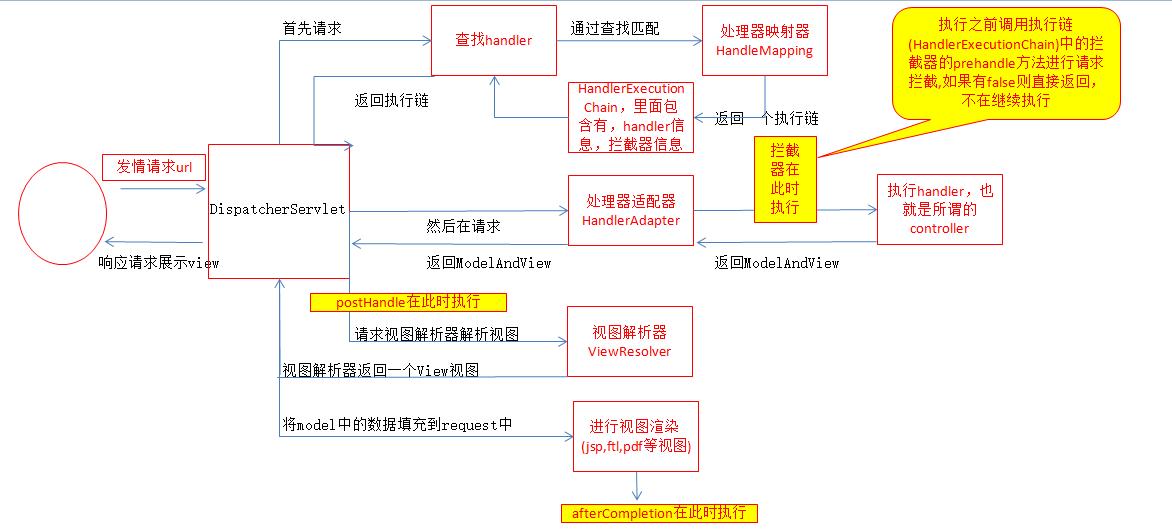
Spring MVC 运行流程(点击打开链接)
在整个Spring MVC框架中,DispatcherServlet处于核心位置,它负责协调和组织不同组件完成请求处理并返回响应的工作。具体流程为:
1)客户端发送http请求,web应用服务器接收到这个请求,如果匹配DispatcherServlet的映射路径(在web.xml中配置),web容器将请求转交给DispatcherServlet处理;
2)DispatcherServlet根据请求的信息及HandlerMapping的配置找到处理该请求的Controller;
3)Controller完成业务逻辑处理后,返回一个ModelAndView给DispatcherServlet;
4)DispatcherServlet借由ViewResolver完成ModelAndView中逻辑视图名到真实视图对象View的解析工作;
5)DispatcherServlet根据ModelAndView中的数据模型对View对象进行视图渲染,最终客户端得到的响应消息可能是一个普通的html页面,也可能是一个xml或json串,甚至是一张图片或一个PDF文档等不同的媒体形式。----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
文字叙述
1 用户浏览器发起请求
2 前端控制器DispatcherServlet首先会去请求Handler(也就是Controller),
怎么请求Handler----通过查找HandlerMapping(里面有xml或者注解方式配置的Handler映射信息信息)来匹配用户请求url对应的Handler,
将查找到的请求信息,放入到执行链HandlerExecutionChain中,然后在放入该url对应的拦截器信息。
然后将执行链HandlerExecutionChain返回给前端控制器DispatcherServlet
3 前端控制器DispatcherServlet通过请求到的handler,再请求处理器适配器HandlerAdapter去执行handler,
::: 执行之前需要先请求执行链中的拦截器的preHandle方法进行某些请求校验等。
4 处理器适配器执行handler后返回给前端控制器DispatcherServlet一个ModelAndView(里面放有视图信息,模型数据信息)
::: 执行拦截器的postHandle方法
5 前端控制器DispatcherServlet请求视图解析器解析视图,根据逻辑名(xxxx/xxxx/xxxx.jsp)解析成真正的视图view(jsp,ftl等)
6 视图解析器解析完成后,返回给前端控制器DispatcherServlet一个View
7 前端控制器DispatcherServlet进行视图渲染,将模型数据填充到request中
8 响应用户请求,展示jsp等视图信息。
Spring MVC 启动流程
Spring 的单例实现原理(点击打开链接)
- 我们来看看Spring中的单例实现,当我们试图从Spring容器中取得某个类的实例时,默认情况下,Spring会才用单例模式进行创建。
<bean id="date" class="java.util.Date"/> <bean id="date" class="java.util.Date" scope="singleton"/> (仅为Spring2.0支持) <bean id="date" class="java.util.Date" singleton="true"/> 以上三种创建对象的方式是完全相同的,容器都会向客户返回Date类的单例引用。那么如果我不想使用默认的单例模式,每次请求我都希望获得一个新的对象怎么办呢?很简单,将scope属性值设置为prototype(原型)就可以了
<bean id="date" class="java.util.Date" scope="prototype"/> 通过以上配置信息,Spring就会每次给客户端返回一个新的对象实例。
那么Spring对单例的底层实现,到底是饿汉式单例还是懒汉式单例呢?呵呵,都不是。Spring框架对单例的支持是采用单例注册表的方式进行实现的,源码如下: -
刚才的源码中,大家真正要记住的是Spring对bean实例的创建是采用单例注册表的方式进行实现的,而这个注册表的缓存是HashMap对象,如果配置文件中的配置信息不要求使用单例,Spring会采用新建实例的方式返回对象实例
Spring 框架中用到了哪些设计模式
1.工厂模式,这个很明显,在各种BeanFactory以及ApplicationContext创建中都用到了;
2.模版模式,这个也很明显,在各种BeanFactory以及ApplicationContext实现中也都用到了;
3.代理模式,在Aop实现中用到了JDK的动态代理;
4.策略模式,第一个地方,加载资源文件的方式,使用了不同的方法,比如:ClassPathResourece,FileSystemResource,ServletContextResource,UrlResource但他们都有共同的借口Resource;第二个地方就是在Aop的实现中,采用了两种不同的方式,JDK动态代理和CGLIB代理;
5.单例模式,这个比如在创建bean的时候
Spring 其他产品(Srping Boot、Spring Cloud、Spring Secuirity、Spring Data、Spring AMQP 等)
有没有用到Spring Boot,Spring Boot的认识、原理
它的核心功能是由@EnableAutoConfiguration这个注解提供的/Spring boot出现之后,得益于“习惯优于配置”这个理念,再也没有繁琐的配置、难以集成的内容(大多数流行第三方技术都被集成在内)。
Hibernate的原理(点击打开链接)
1.通过Configuration config = new Configuration().configure();//读取并解析hibernate.cfg.xml配置文件
2.由hibernate.cfg.xml中的<mapping resource="com/xx/User.hbm.xml"/>读取并解析映射信息
3.通过SessionFactory sf = config.buildSessionFactory();//创建SessionFactory
4.Session session = sf.openSession();//打开Sesssion
5.Transaction tx = session.beginTransaction();//创建并启动事务Transation
6.persistent operate操作数据,持久化操作
7.tx.commit();//提交事务
8.关闭Session
9.关闭SesstionFactory1. 面向对象设计的软件内部运行过程可以理解成就是在不断创建各种新对象、建立对象之间的关系,调用对象的方法来改变各个对象的状态和对象消亡的过程,不管程序运行的过程和操作怎么样,本质上都是要得到一个结果,程序上一个时刻和下一个时刻的运行结果的差异就表现在内存中的对象状态发生了变化。
2.为了在关机和内存空间不够的状况下,保持程序的运行状态,需要将内存中的对象状态保存到持久化设备和从持久化设备中恢复出对象的状态,通常都是保存到关系数据库来保存大量对象信息。从Java程序的运行功能上来讲,保存对象状态的功能相比系统运行的其他功能来说,应该是一个很不起眼的附属功能,java采用jdbc来实现这个功能,这个不起眼的功能却要编写大量的代码,而做的事情仅仅是保存对象和恢复对象,并且那些大量的jdbc代码并没有什么技术含量,基本上是采用一套例行公事的标准代码模板来编写,是一种苦活和重复性的工作。
3.通过数据库保存java程序运行时产生的对象和恢复对象,其实就是实现了java对象与关系数据库记录的映射关系,称为ORM(即Object Relation Mapping),人们可以通过封装JDBC代码来实现了这种功能,封装出来的产品称之为ORM框架,Hibernate就是其中的一种流行ORM框架。使用Hibernate框架,不用写JDBC代码,仅仅是调用一个save方法,就可以将对象保存到关系数据库中,仅仅是调用一个get方法,就可以从数据库中加载出一个对象。
4.使用Hibernate的基本流程是:配置Configuration对象、产生SessionFactory、创建session对象,启动事务,完成CRUD操作,提交事务,关闭session。
5.使用Hibernate时,先要配置hibernate.cfg.xml文件,其中配置数据库连接信息和方言等,还要为每个实体配置相应的hbm.xml文件,hibernate.cfg.xml文件中需要登记每个hbm.xml文件。
6.在应用Hibernate时,重点要了解Session的缓存原理,级联,延迟加载和hql查询。
Hibernate与 MyBatis的比较(点击打开链接)、
-
springmvc与struts2比较(点击打开链接)
struts2是 类级别的拦截 , 一个类对应一个request上下文,
springmvc是 方法级别的拦截 ,一个方法对应一个request上下文,而方法同时又跟一个url对应
所以说从架构本身上 spring3 mvc就容易实现restful url
而struts2的架构实现起来要费劲
因为struts2 action的一个方法可以对应一个url
而其类属性却被所有方法共享,这也就无法用注解或其他方式标识其所属方法了
===================================
spring3mvc的方法之间基本上独立的,独享request response数据
请求数据通过参数获取,处理结果通过ModelMap交回给框架
方法之间不共享变量
而struts2搞的就比较乱,虽然方法之间也是独立的,但其所有Action变量是共享的
这不会影响程序运行,却给我们编码 读程序时带来麻烦
====================================
spring3 mvc的验证也是一个亮点,支持JSR303
处理ajax的请求更是方便 只需一个注解@ResponseBody ,然后直接返回响应文本即可
可参考《为什么会有Spring》
可参考《为什么会有Spring AOP》

3.2、Netty
为什么选择 Netty
说说业务中,Netty 的使用场景
原生的 NIO 在 JDK 1.7 版本存在 epoll bug
什么是TCP 粘包/拆包
TCP粘包/拆包的解决办法
Netty 线程模型
说说 Netty 的零拷贝
Netty 内部执行流程
Netty 重连实现
3.3、Tomcat
Tomcat的基础架构(Server、Service、Connector、Container)
Tomcat如何加载Servlet的
Pipeline-Valve机制
可参考:《四张图带你了解Tomcat系统架构!》
-