提示,我当前Tesseract-OCR 版本是 4.0 ,jTessBoxEditorFX是2.0.1
1.下载Tesseract-OCR 链接
2.下载jTessBoxEditorFX 链接,如果中文一定要选择FX版本(基于Java,需安装JDK)
3.Tesseract-data目录 Github,下载下来将需要的文件放到Tesseract-OCR安装目录下的tessdata目录下
4.将Tesseract-OCR目录配置到环境变量(不添加也行,比较麻烦)
中文训练步骤
1.创建一个png文件(其他格式也行)

2.打开jTessBoxEditorFX,Tools -- Merge TIFF选择文件,注意选择格式,输入文件名 mychi.myfont.exp0.tif,点击确定,图片目录下会出现一个tif格式文件


3.图片目录下打开命令行,输入 tesseract mychi.myfont.exp0.tif mychi.myfont.exp0 -l chi_sim batch.nochop makebox,会生成一个box文件
4.使用jTessBoxEditorFX打开box文件(打开tif会默认打开box文件),Box Editor -- Open ,选择 mychi.myfont.exp0.tif,修改其中错误的识别字符,可以调整识别框的大小

5.继续使用命令行工具,输入 tesseract mychi.myfont.exp0.tif mychi.myfont.exp0 nobatch box.train,生成tr文件
6.输入 unicharset_extractor mychi.myfont.exp0.box,生成unicharset文件并重命名为mychi.unicharset

7.输入 echo myfont 0 0 0 0 0>font_properties,生成文件

8.输入 mftraining -F font_properties -U mychi.unicharset -O mychi.unicharset mychi.myfont.exp0.tr和
cntraining mychi.myfont.exp0.tr,共生成四个文件
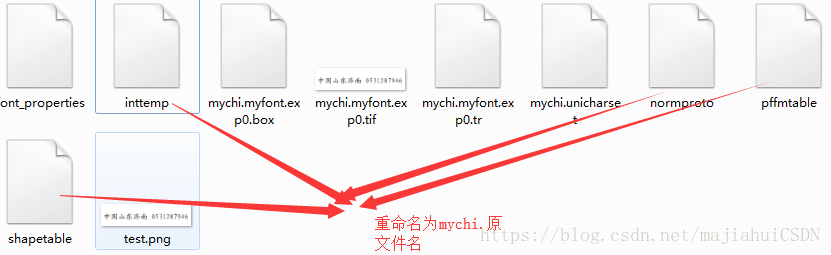
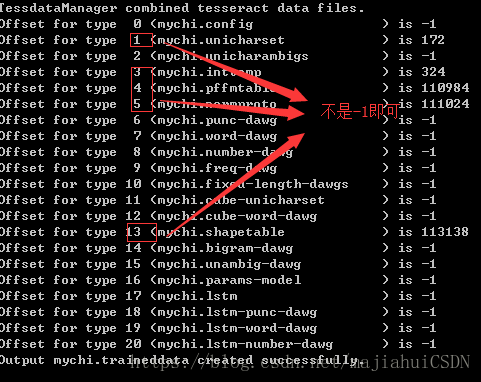
9.输入 combine_tessdata mychi.生成mychi.traineddata
10.测试,将mychi。traineddata复制到Tesseract-OCR目录下的tessdata,输入 tesseract test.png result -l mychi,完成