一,下载jTessBoxEditor工具
jTessBoxEditor工具是采用Tesseract的一款专业的orc样本识别训练软件,基于java开发而来,可以进行Tesseract样本训练,形成自己的语言库,提高图片文字的识别率和准确率。
官网下载地址:
https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
二,使用方法
-
配置好Java开发环境,解压文件,点击下图中的两个文件都可以启动
启动成功后的界面
-
操作步骤
制作图片 --> 生成box文件 --> 训字操作 --> 制作新库 -
生成box文件
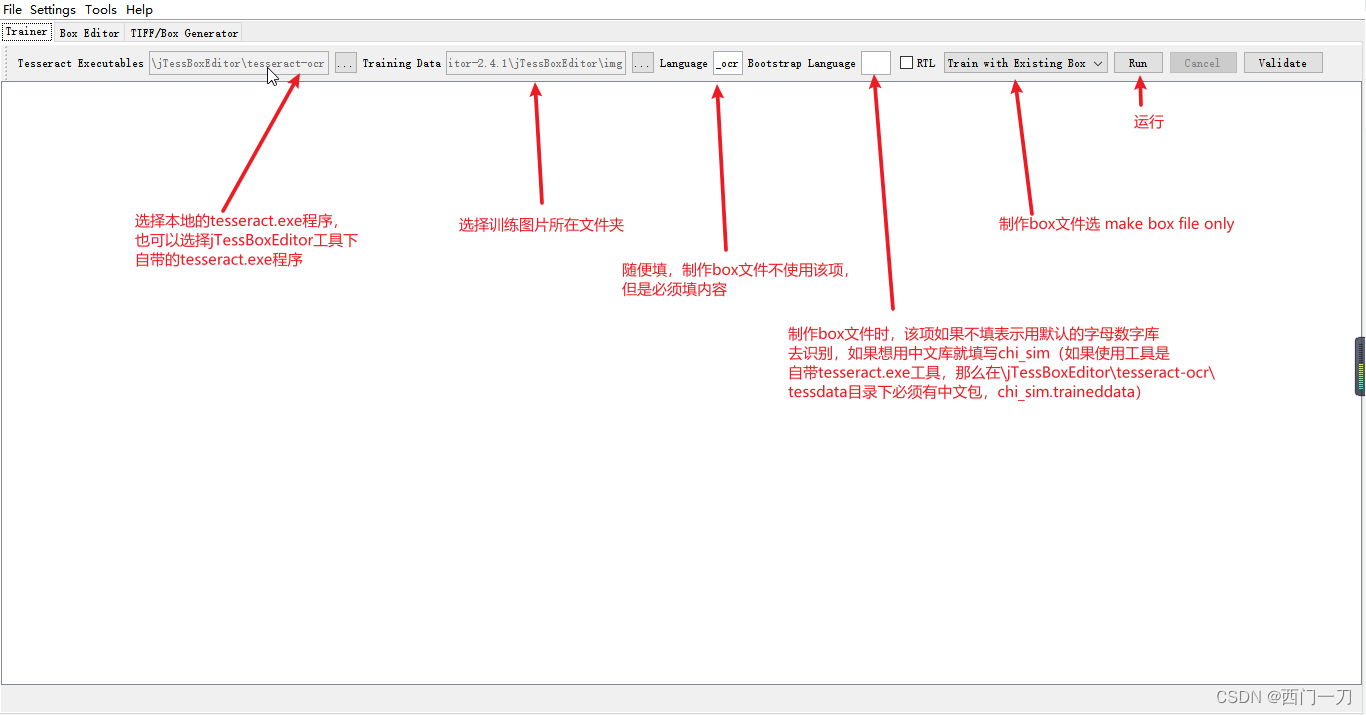
-
训字操作
- 运行后在图片同目录生成box文件
- 还是使用jTessBoxEditor软件,打开图片,见到如下界面

- 矫正错误的字
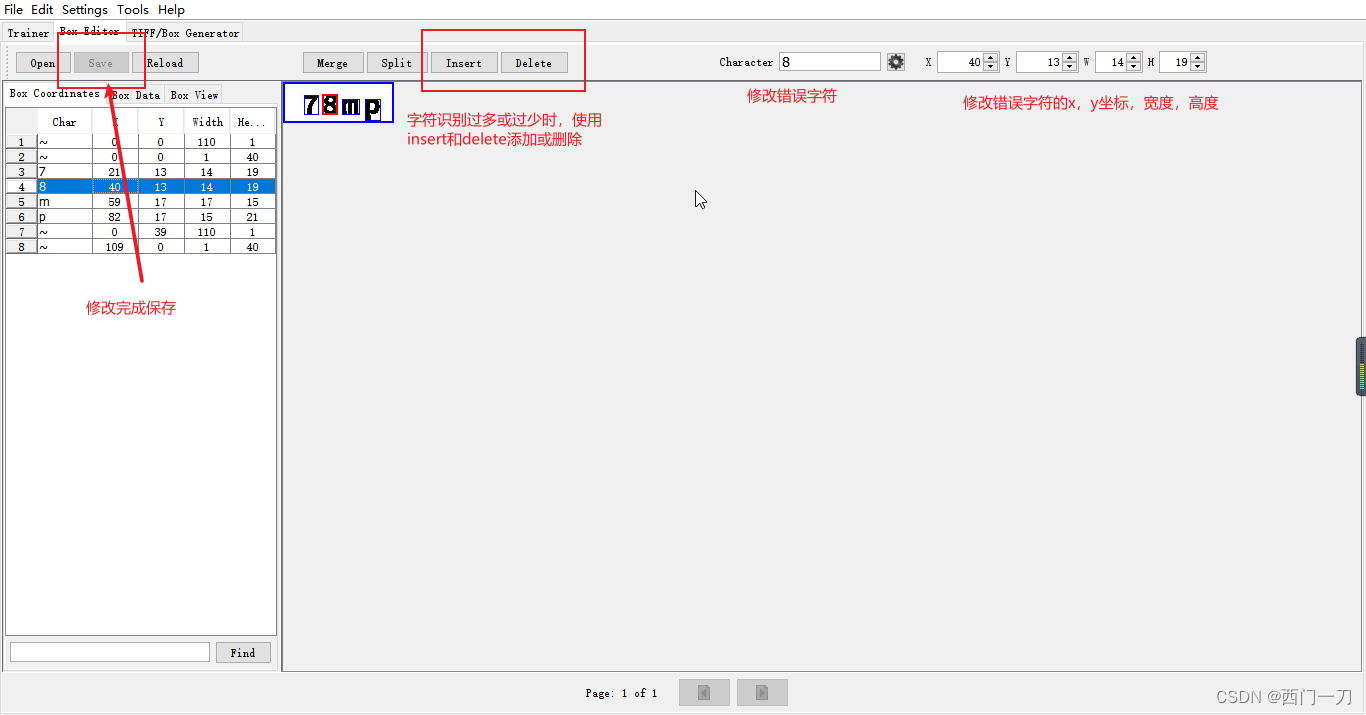
- 制作新库
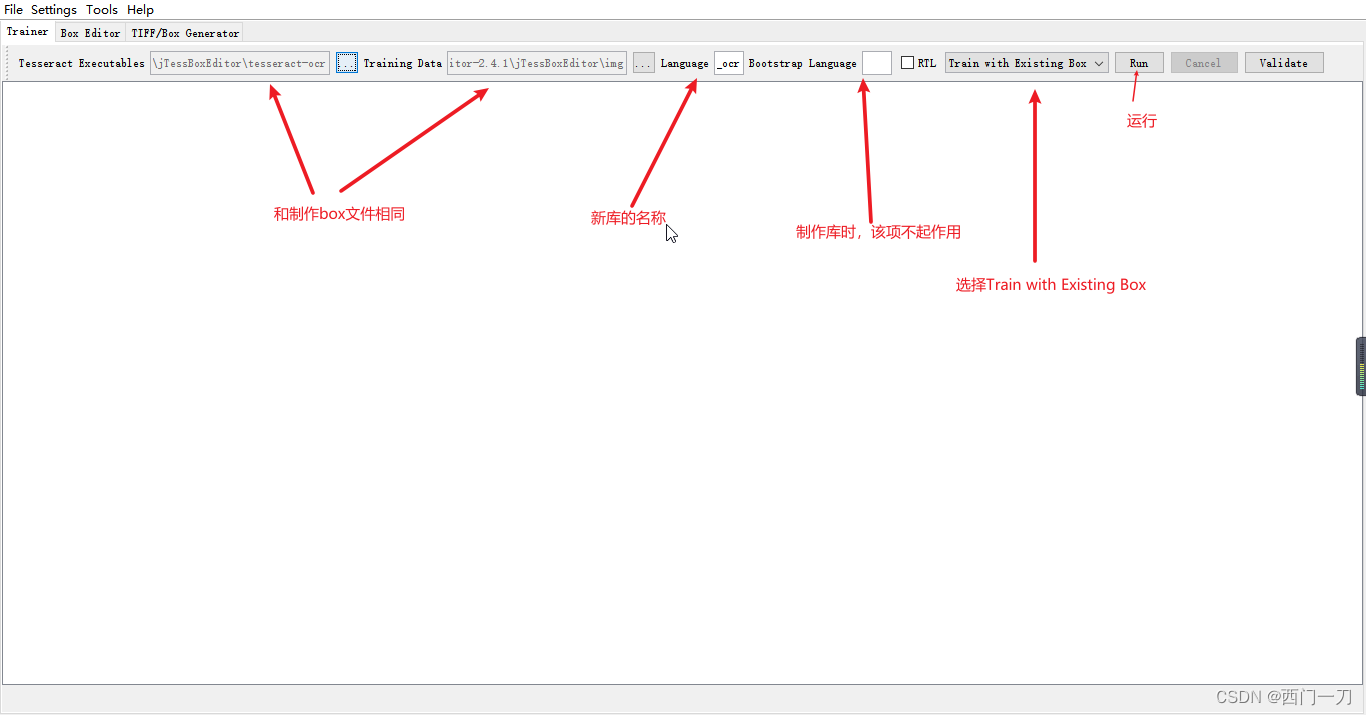
- 新库制作完成,在图片文件夹下会产生tessdata目录,制作的新库就在tessdata目录下

- 使用新库
- 然后把新库拷到Tesseract-OCR\tessdata目录下就可以使用了:
- 在Python代码中使用新库时,记得修改配置
text = pytesseract.image_to_string(im, lang='pingan_ocr')