Teradata 数据库介绍
Teradata在整体上是按Shared Nothing 架构体系进行组织的,他的定位就是大型数据仓库系统,定位比较高,他的软硬件都是NCR自己的,其他的都不识别;所以一般的企业用不起,价格很贵。由于Teradata通常被用于OLAP应用,因此单机的Teradata系统很少见,即使是单机系统,Teradata也建议使用SMP结构以尽可能地提供更好的数据库性能,在后面的介绍中,都是按多机系统进行说明的。
根据Shared Nothing的组成结构特点,在物理布局上,Teradata系统主要包括三个部分:
1. 处理节点(Node)、
2. 用于节点间通信的内部高速互联(InterConnection)
3. 数据存储介质(通常是磁盘阵列)。
每个节点都是SMP(对称多处理器结构)结构的单机,节点的物理和逻辑结构如图1所示,多个节点一起构成一个MPP(海量并行处理器结构)系统,多个节点之间的内部高速互联是通过一种被称为BYNET的硬件来实现的,整个系统的组成如图1所示。

单个节点的硬件结构
Teradata系统中的每个节点在物理上都是一个SMP处理单元,事实上就是一台多CPU或多核的计算机。节点硬件包括CPU、内存、用于安装操作系统和应用软件的本地磁盘、与外界交互的网卡及BYNET端口。节点的网卡根据具体的网络环境而不同,通常包括两种:
1. 一种是与IBM MainFrame连接的Channel Adapter
2. 另一种就是我们熟悉的局域网网卡。
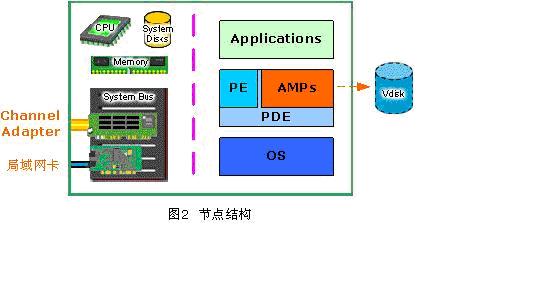
通常情况下一个节点上只会使用一种网卡,但会有多块网卡,分别用于不同的连接和冗余。
单个节点的软件结构
在软件结构上,每个节点自下向上包括操作系统软件(OS)、Teradata并行数据库扩展(PDE)和相关应用程序,其中PDE的主要职责是管理和运行虚拟处理器,其中主要包括PE和AMPs。
(1)Teradata并行数据库扩展(PDE,Parallel Database Extensions),是直接架构在操作系统之上的一个接口层,用于为Teradata提供并行环境,并保证这个并行环境的可运行性和健壮性。PDE的主要功能是执行虚拟处理器、进行Teradata并行任务调度、进行操作系统内核和Teradata数据库的运行时故障处理。
(2)虚拟处理器(VPROC,Virtual Processor),是一系列软件进程,这些进程驻留在一个节点上,依赖PDE环境运行,并接受PDE调度。可以把VPROC理解为一些Teradata的底层服务进程。虚拟处理器完成Teradata数据处理的主要工作,按照工作性质的不同,虚拟处理器主要包括两大类——解析引擎和存取模块处理器。
(3)解析引擎(PE,Parsing Engine),用于进行客户系统(通常是使用Teradata数据库的应用程序的SQL请求)和存取模块处理器之间的通讯和交互,主要的功能包括任务控制(Session Control),SQL语句的解析、优化、查询步骤的生成和分发,并行化预处理和返回查询结果。一个节点上通常只有一个或两个PE在工作。
(4)存取模块处理器(AMP,Access Module Processor),这是Teradata数据库的关键进程,用于处理所有与数据有关的文件系统的操作任务,是Teradata数据库Share Nothing架构的核心表现。通常情况下,一个节点上会有多个AMP在工作,每个AMP分别负责文件系统上不同的、固定的数据的存取操作。
(5)虚拟磁盘(VDisk,Virtual Disk),这是一个纯粹的逻辑概念,事实上不应该把它认为是软件结构的一部分。典型的Teradata MPP系统的数据存储都是以磁盘阵列(Disk Arrays)的形式实现的,在物理上是一个个存放于标准磁盘阵列柜中的磁盘阵列模块。Teradata系统中的每个AMP在处理数据存储时,会根据一种哈希算法把不同的数据均匀地分散存储到磁盘阵列中的不同的磁盘上(上海证券交易所的数据仓库就是teradata,每秒的io能达到2G,有1000多块磁盘,硬件昂贵。全表扫描一个几千万条的记录在几秒就完成了)。这样,在逻辑上我们就把磁盘阵列中不同磁盘上存储着的那些由同一个AMP负责存储和维护的数据合并在一起,就像它们在一个磁盘上一样,这就是VDisk的概念了。
BYNET
在Teradata MPP系统中,各个节点间(确切地说是各个AMP之间)的内部高速互联是通过BYNET实现的,我们可以认为它就是Teradata系统中那些松散耦合的节点之间互相联系的通讯总线,但事实上,它却远远没有这么简单。
BYNET是一组硬件和运行在这组硬件上的一些处理通讯任务的软件进程的组合体,用于节点之间的双向广播(bidirectional broadcast)、多路传递(multicast)和点对点通信(point-to-point communication),同时,BYNET还实现SQL查询过程中的合并功能(每个节点或AMP,均匀分布表中一部分数据,当查询的时候每个节点并行查询,结果汇总到某个节点反馈给查询者,提高查询速度。参考:http://blog.csdn.NET/NevePioneer/archive/2009/01/04/3704443.aspx)。
参考文章:
http://www.cnblogs.com/hustcat/articles/1627784.html
对于国内数据库人士来说,Teradata也许还不象Oracle那么熟悉。但在国外,由于它驱动着世界上几乎一半的数据仓库,并且世界上最大的几十个数据仓库均采用它作为核心引擎,因此,Teradata几乎成了数据仓库引擎的代名词。
Teradata是专门针对决策支持应用而设计的,早在1983年就推出了世界上第一个基于海量并行处理技术(MPP)的商用系统。
长期以来,Teradata公司投入了大量的人力、财力,对Teradata作了许多增强和优化,使得其更适合于进行海量数据的综合分析和处理。Teradata从早期基于硬件的封闭系统发展成运行于UNIX环境、基于虚拟处理器(VPROC)技术的关系型数据库管理系统。
特别值得强调的是,著名的评估机构Gartner Group于1994年将Teradata评为“商用并行处理的领导者”,1996年进一步指出,“只有Teradata的Teradata证明了其可扩展性”。
在数据库专业杂志“数据库编程与设计”(Database Programming & Design)每年的评选数据库十二大产品(Database Dozen)的活动中,Teradata已经连续第7年入选。在1999年的评选中,该杂志认为,“Teradata代表了数据库技术的发展方向”。
从90年代到今天,Teradata是Gartner Group领导厂商。
Teradata的各项特点可以从以下几个方面来进行概括
数据自动分配
Teradata中只有一种基于HASH算法的数据分配机制,当要插入一条记录时,根据主索引计算出相应的AMP,该条记录即通过此AMP存到其对应的磁盘上。由于主索引值的不同,一个表的各条记录将通过各AMP均匀地分布到各个磁盘上。分配过程完全自动进行,不需要DBA干预,这一点和其它OLTP DBMS有很大的区别。Teradata的HASHING算法经过长期的发展,已经十分完善。它采用了一个类似矩阵的HASH MAP,将计算出来的HASH值通过此矩阵的映射与AMP进行联系。这样,当重新配置AMP数时,只需要变动HASH MAP,速度非常快。
强大的并行处理能力和复杂查询处理能力
Teradata最显著的特色之一是其强大的并行处理能力,这也是为什么说它是数据仓库专用引擎的主要原因之一。其实现方式被称为多维并行处理机制,简单描述如下:
查询并行(Query并行):这种并行处理是基于上面介绍的HASHING数据分配机制实现的。每个AMP都是一个VPROC,各自独立负责一部分数据的处理,相互之间没有关系,每个节点一般配置4至16个这样的VPROC。所有关系运算如表的搜索、索引检索、投影、选择、联接、聚集、排序等都是由各个VPROC并行进行的。
步内并行(Within-a-Step并行):一个SQL查询进入系统后,首先由优化器进行优化处理,分解成一些小的步骤(Step),然后再分发给各VPROC进行处理。一个步骤可能非常简单,如“搜索一个表并返回结果”,也可能非常复杂,如“按照某条件搜索两个表,然后联接,结果投影到某几个列,对它们加和(SUM)后返回结果”。象这种复杂查询将处理多个关系运算,每个关系运算在一个VPROC内将启动多个进程来实现并行处理,称为步内并行。
多步并行(Multi-Step并行):上面说过,一个SQL被分解成多个小的步骤,这些步骤的执行将同时进行,称为多步并行。优化器分解一个SQL查询请求的原则是尽可能使各步独立。在目前所有的DBMS产品中,只有Teradata实现了多步并行。
下图以一个复杂查询的实例形象地说明了Teradata的多维并行处理机制。

线性可扩展能力
数据量增长时的线性度:当用户数据量成倍增加时,对于同一个系统(指硬件配置不变),响应时间是按比例线性增加的;
硬件平台的线性度:对于同一个查询,当硬件平台的配置增加一倍时,响应时间应减少一半;
并发用户增加时的线性:对于同一个系统,当并发用户的数目增加时,响应时间也按比例线性增加。
易于管理
下表是Teradata和一些传统的OLTP RDBMS在各种数据库管理任务上的简单比较:

由于DBA的减少,运行费用将大大降低,使得系统的整体拥有成本大大降低。
数据库内含丰富的OLAP功能
Teradata是专为数据仓库设计的,主要用来进行数据的综合分析和处理,因此在开发时嵌入了丰富的OLAP功能,主要包括:排序RANK、累计和CSUM、移动平均MAVG、移动和MSUM、移动差分MDIFF、采样SAMPLE、分位QUANTILE、限定QUALIFY等。这些函数可以和标准的SQL语句一起使用,而且所有这些函数都是在Teradata内部以并行方式来工作,速度非常快。在目前众多的数据库系统中,只有Teradata提供了这种由数据库本身完成的OLAP分析功能。