ES 简介
索引,分片,副本
ElasticSearch 是一个基于 Apache Lucene 搜索引擎的开源的搜索服务器项目,作为一个文档型搜索服务器,其存储和架构和 mongo 等 NoSQL 数据库十分类似,包括文档型的存储,分片,索引,集群和副本集等。
索引
注意,es 的索引和数据库的索引概念是不一样的。
es 的索引相当于mongo 数据库中的集合或者关系型数据库中的库。es 建立索引时的 mapping 字段则相当于mongo 数据库中的表。
以 MongoDB 为例,mongo 数据库中有 order 集合,order 下有 info, 其中order_id 为 info 表的索引。
那么在 es 中,索引是 order,info 是 mapping 的类型 _type。//mongo 数据 use order db.info.find() { "did": 490873, "order_id": 3 ... } //es 数据 { "_index": "order", "_type": "info", "_source": { "did": 490873, "order_id": 3 .... } }- 分片
当数据量达到单机物理极限时,可以使用分片进行水平扩展,即将数据分割为更小的单元,存储在不同的服务器上,每一个分片负责一部分数据的处理,总的查询将在各个分片查询结束后,汇总结果返回给调用方。因此一个索引的数据会分布在不同的物理机上。 副本
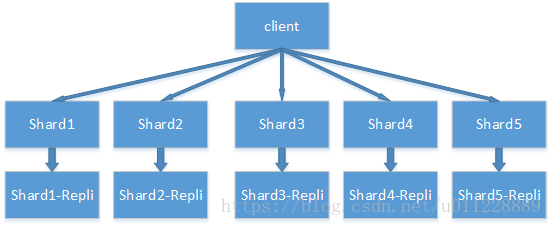
副本集主要用于数据容灾和提高查询的吞吐量,每个分片可以有多个副本集,副本集只是分片的一个复制,可以认为存储了几份相同的数据。分片和其对应的副本集之间,有一个主分片对外提供服务,当主分片故障或其他原因不可用时,将会从副本集中选择一个作为主分片,继续对外提供服务。如果不指定,es 将默认使用 5 个分片和 1个副本。其架构如下图所示:
REST API 接口
ES 所有的增删改查等操作均通过 REST API 接口实现,甚至包括管理索引,检查集群和节点状态等。
一个简单的 REST API 接口的模型就是 操作 + 状态 , es 支持的操作有增删改查,操作后面指定es 的地址和端口,
| GET | 获取对象信息,可以是集群信息,也可以是 es 中的数据信息,索引信息等 |
|---|---|
| PUT | 新建一个对象 |
| POST | 修改对象,除了可以设置索引,分片和数据修改外,还可以发送关机,重启等命令 |
| DELETE | 删除一个对象 |
获取 es 集群基本信息
curl -XGET 127.0.0.1:9200
{
"name" : "127.0.0.1",
"cluster_name" : "127.0.0.1",
"version" : {
"number" : "2.3.5",
"build_hash" : "90f439ff60a3c0f497f91663701e64ccd01edbb4",
"build_timestamp" : "2016-07-27T10:36:52Z",
"build_snapshot" : false,
"lucene_version" : "5.5.0"
},
"tagline" : "You Know, for Search"
}新建一个文档
# 在 curl 中使用 XPUT 时,-d 表示使用负载文本,后面的内容用于替换 1 , 所以 1 不能省略
curl -XPUT 127.0.0.1:9200/test/info/1 -d '{"title":"test"}'
{
"_index": "test",
"_type": "info",
"_id": "1",
"_version": 4,
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}注: es 部署的默认端口为9200
ES 开发步骤
setting
获取当前 setting
curl -XGET 127.0.0.1:9200/test/_settings?pretty分片, 索引和副本集等设置
es 中分片和副本集的大小设置是在 setting 的 index 字段中
curl -XPUT 127.0.0.1:9200/test -d '
{
"settings": {
"index" : {
"number_of_shards" : '5', #分片数
"number_of_replicas" : '1' #副本数
}
} 当第一次插入数据时,如果索引不存在,es 会自动创建索引,通过修改 es 的配置文件 elasticsearch.yml 关闭自动创建:
action.auto_create_index :false通过 PUT 来创建索引,以下是创建 名为 test 的索引。
curl -XPUT 127.0.0.1:9200/test/
#创建成功会返回
{"acknowledged":true}analyzer 自定义分析器设置
es 中的分析器 analyzer 也是在setting 字段中设置,用于字符串类型的分析,系统 默认的分析器有以下几种:
standard 、simple 、whiteSpace 、stop 、keyword 、pattern 、 language 、snowball
除使用默认之外可以自定义分析器,analyzer 在 setting 字段中设置, 1 个 analyzer = 1 个分词器 + n 个过滤器
{
"settings": {
"analysis": {
"analyzer": {
//自定义分析器名字为 char_analyzer
"char_analyzer": {
"type": "custom",
//一个分词器
"tokenizer": "char_split", //这个分词器 char_split 是自定义的
//多个过滤器
"filter": [ "lowercase", //这个过滤器是系统自带的 "myFilter" //这个过滤器是自定义的 ] }
},
//自定义的分词器 char_split
"tokenizer": {
"char_split": {
"type": "nGram",
"min_gram": "1",
"max_gram": "1",
"token_chars": ["letter", "digit", "whitespace", "punctuation", "symbol"] }
},
//自定义的过滤器 myFilter
"filter":{
"myFilter":{
"type":"kstem" }
}
}
}
}mapping
在 es 的 json 结构中,mapping 字段是与 setting 字段同级的,es 通过 mapping 来自定义索引的结构和字段之间的映射关系,常用的数据类型有 long 、string 和 nested
获取当前 mapping
curl -XGET 127.0.0.1:9200/test/_mappings?pretty简单数据类型及自动推导
long : 数值型和 数值型的 数组 字段均使用 long 类型, es 中可以通过 { “dynamic”: “true” } 设置是否动态推断数据类型,设为 true时 数值型的字段可以不用设置mapping值,由 es 自动推导其类型
string: 字符串类型,用于搜索和半匹配,可以结合分析器一起使用
复杂数据类型
对于一个包含内部对象的数组,存储时会被扁平化,比如以下数组
{
"followers": [
{ "age": 35, "name": "Mary White"},
{ "age": 26, "name": "Alex Jones"},
{ "age": 19, "name": "Lisa Smith"}
]
}最终存储结果:
{
"followers.age": [19, 26, 35],
"followers.name": [alex, jones, lisa, smith, mary, white]
}{age: 35}与{name: Mary White}之间的关联会消失,因每个多值的栏位会变成一个值集合,而非有序的阵列。
此时使用nested 类型来处理这些嵌套的结构,比如以下的 properties.prop 就是一个多值字段。
以下是一个基本的 mapping 结构
{
"mappings": {
"person": {
"dynamic": "false",
"properties": {
"id": {
"type": "long" },
"name": {
"type": "string",
"analyzer": "char_analyzer", //指定分析器
//如果希望字符串是全词匹配的,要指定 not_analyzed
//"index": "not_analyzed" },
"prop": {
//嵌套结构使用 nested
"type": "nested",
"properties": { "propid": {"type": "long", "index": "not_analyzed"}, "propname": {"type": "string", "analyzer": "char_analyzer"}, } }
}
}
}
}DSL
业务模块已经对 es 接口做了一层封装,需要使用 es 的模块执行初始化之后,调用相应的接口函数即可,下面是使用 REST API 接口的DSL操作
增删改
先看一个 es 文档的具体结构:
{
"_index": "order",
"_type": "info",
"_id": "did-490873_id-3",
"_version": 6,
"_score": 1,
"_routing": "490873",
"_source": {
"did": 490873,
"order_id": 3,
....
}
}可以看到,一个es 文档一定包含以下字段:
_index : 索引名称 , 可以理解为 mongo 中的数据库名,也用于在执行其他操作时指定的索引 $es_addr/_index
_type : 类型名称, 可以理解为 mongo 中的表名
_id : 唯一标识符, 一般由各个模块自己指定,用类似 did-10000_id-1 的格式作为 _id 的值
_version: es 自动维护的版本号,数据每次更改会自增
_source : 文档元数据
_routing : 路由值。由于es 中的索引时存储在各个分片上的,当我们创建或检索一个文档时,要知道或指定是在哪一个分片上。所有的文档 操作都接收一个_routing参数,它用来自定义文档到分片的映射。自定义路由值可以确保所有相关文档——例如属于同一公司的文档——被保存在同一分片上。 可以看到目前所有业务模块的路由值全部使用的 did
搜索
搜索可以同时在多个索引的多个类型上进行
//搜索格式:
curl -X GET '127.0.0.1:9200/index/type/_search'
//没有指定索引 默认在所有索引上搜索
curl -X GET '127.0.0.1:9200/_search/'
//同时指定 order 和 custm 索引搜索
curl -X GET '127.0.0.1:9200/order,custm/_search/'\
//在以g或u开头的索引的所有类型中搜索
curl -X GET '127.0.0.1:9200/g*,u*/_search'
//在order 索引的 info 类型中搜索
curl -X GET '127.0.0.1:9200/order/info/_search'
//在 order 索引的类型 info, setting 中搜索
curl -X GET '127.0.0.1:9200/order/info,setting/_search'
//在所有索引的类型为 info 的集合上搜索
curl -X GET '127.0.0.1:9200/_all/user,tweet/_search'查询是业务调用最为频繁的接口,也是最复杂的接口,业务模块的主要处理是根据不同的查询操作,制定查询方案,以下是目前一些通用的查询,可以覆盖大多数的搜索方案。
最外层的是 query 和 bool , bool 以内分为四种查询方式:must 、 filter 、should、 must_not
以下是官方文档对四种查询的解释
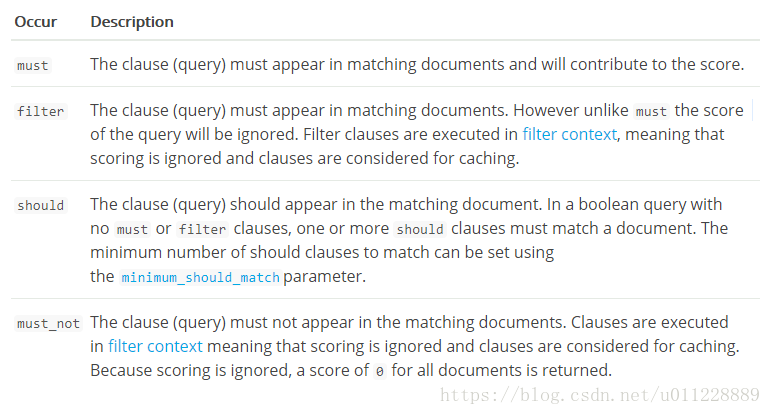
可以看到如果无需系统评分或相关度计算,仅仅用于搜索,使用filter就可以了。一个典型的查询结构如下图所示:
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "user" : "kimchy" }
},
"filter": {
"term" : { "tag" : "tech" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 } }
},
"should" : [
{ "term" : { "tag" : "wow" } },
{ "term" : { "tag" : "elasticsearch" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}在上面四种查询方式下,就是更小一级的对数据的过滤,如 term/terms 、match 、and 、or 、range 等等
term 和 terms
term 是最常用的查询,该查询不会使用分词,必须全匹配, 大小写也是敏感的,所以常用于数字型的搜索
terms 是 term 的数组形式,用于简单的数值型数组的匹配,满足数组中任何一个元素即返回
{
//查询 did 为 10000, 且 pid 为数组 [22,23,24,25] 子集的文档
"term":{ "did":10000 },
"terms":{ "pid":[22,23,24,25] }
}match 和 match_phrase
match_phrase 和 match 用于字符串搜索,在定义了分词器的情况下都会使用分词
在 match_phrase 中 所有的 term 都出现在数据中时才会返回数据
数据中出现的顺序必须和给定的查询顺序一致才会返回数据
netsted 类型数据查询
netsted 类型的数据查询需要制定 path, 也就是嵌套结构中类型为 nested 的字段,然后嵌套结构内的字段用dot 查询。
以下是一个完整的包含所有查询方式的 json
{
"query": {
"bool": {
"filter": {
// and 下的条件是需要 同时满足的
"and": [{
//对于数字类型的搜索,使用 term
"term": { "did": 519390 } },{
//对于数组类型的搜索 使用 terms
"terms": { "follower_pids": [40984,40985] } }, {
//范围搜索, 用 range
"range": { "create_time": { "gte": 1488211200000, "lte": 1488988799999 } } }
]
},
//should 下的条件 满足之一即可
"should": [{
//使用 match_phrase 的是使用分词的,用于搜索字符串,且半词匹配
"match_phrase": {
"contact_names": "44" }
}
],
//should 中应该至少满足的条件个数
"minimum_should_match": 1,
//must 下的也是必须满足的,其实跟放在 and 下也可以 但是and 下一般放数值型的匹配
"must": [{
"match_phrase": {
"name": "234" }
}, {
// nested 用于匹配 json 中嵌套json 的数据,在建立 mapping 的时候要使用 nested 并指定 path
"nested": {
"path": "props",
"query": { "bool": { "filter": [{ "term": { "props.propid": 583 } }, { "match_phrase": { "props.propvalue": "44" } } ] } } }
}, {
"nested": {
"path": "props",
"query": { "bool": { "filter": [{ "term": { "props.propid": 585 } }, { "range": { "props.timestamp": { "gte": 1489507200000, "lte": 1490111999999 } } } ] } } }
}, {
"nested": {
"path": "props",
"query": { "bool": { "filter": [{ "term": { "props.propid": 588 } }, { "terms": { "props.propmultiselect": ["one"] } } ] } } }
}
],
"must_not": [{
"terms": {
"prop_ids": [584] }
}
]
}
},
"sort": [{
"props.timestamp": {
"order": "asc",
"nested_path": "props",
"nested_filter": {
"term": {
"props.propid": 586 }
}
}
}
],
"fields": ["custmid", "contid"],
"from": 0,
"size": 51
}深度分页
es 默认采用的分页方式是 from+ size的形式,在深度分页的情况下,这种使用方式效率是非常低的,比如 from = 5000, size=10, es 需要在各个分片上匹配排序并得到5010 条有效数据,然后返回最后10条数据,这种方式类似于mongo的 skip + size。目前支持最大的 skip值是 max_result_window ,默认1w。为了满足深度分页的场景,es 提供了 scroll + scan 的方式进行分页读取。
先获取一个 scroll_id
curl -XGET 127.0.0.1:9200/product/info/_search?pretty&scroll=2m -d
{"query":{"match_all":{}}}
# 返回结果
{
"_scroll_id": "cXVlcnlBbmRGZXRjaDsxOzg3OTA4NDpTQzRmWWkwQ1Q1bUlwMjc0WmdIX2ZnOzA7",
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"failed": 0
},
"hits":{...}
}然后后续的文档读取根据这个scroll_id 来
使用 Go 写 es 导入工具
重建分片和索引,并导入数据
当索引结构改变,需要重新建立索引时,要先清空数据,然后重建索引,再将数据重新导入到 es 里
curl -XDELETE 127.0.0.1:9200/order
#或者使用数据清理脚本,其中 order 是索引地址
es_clean_data.sh 127.0.0.1:9200 orderES 开发中的问题集合
同样的查询,使用curl 正常而使用head 插件时无数据返回:
将操作请求从 GET 改为 POST
使用 skip 时,对于10000 条以后的数据无法返回:
这是 es 本身默认对skip 的限制,es 分页使用的是
{ from:100 , size : 10 }即从第 100 条开始取10条数据。在 es 索引中有个字段 index.max_result_window 默认设置为 10000。
如果 from + size > index.max_result_window ,es 不会返回数据,该字段可以修改,比如指定custm 索引的值为 50000curl -XPUT "127.0.0.1:9200/custm/_settings" -d '{ "index" : { "max_result_window" : 50000 } }'设置之后可以使用以下命令查看 custm 索引的setting 信息
curl -XGET 127.0.0.1:9200/custm/_settings?pretty如果要将当前所有的索引都设置,将索引名改成 _all 就可以
curl -XPUT "127.0.0.1:9200/all/_settings" -d '{ "index" : { "max_result_window" : 50000 } }'但是后续新建的索引要自己手动加,系统不会帮你加
es 安装问题
如果是初始化安装部署,es 搜索有问题,先看看服务有没有启动,然后判断 es 服务是否可用:
[root@local]# curl -X GET 127.0.0.1:9200 { "name" : "xx.xx.xx.xx", "cluster_name" : "xx.xx.xx.xx", "version" : { "number" : "2.3.5", "build_hash" : "90f439ff60a3c0f497f91663701e64ccd01edbb4", "build_timestamp" : "2016-07-27T10:36:52Z", "build_snapshot" : false, "lucene_version" : "5.5.0" }, "tagline" : "You Know, for Search" }如果显示的是 connection refused ,要注意 es 的运行的 host 与系统的 host 是否一致,如果是使用配置运行的,检查配置是否正确:/usr/local/elasticsearch/config/elasticsearch.yml
ES 相关资源
在线资源
https://www.gitbook.com/book/looly/elasticsearch-the-definitive-guide-cn
ES head 插件
浏览器直接访问地址: http://127.0.0.1:9200/_plugin/head/
使用Chrome 插件访问: Google 应用商店搜索 ES Head 下载即可