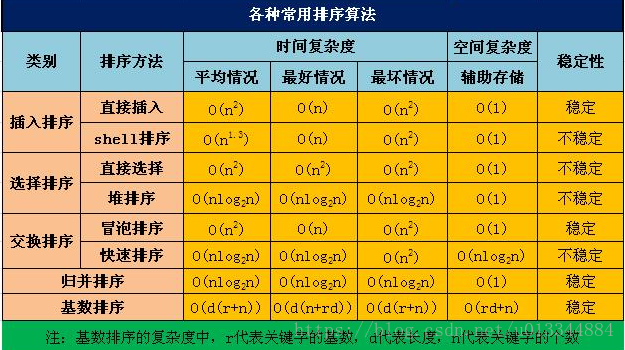
1、快速排序
list1 = [1,4,2,3,10,8,7,5,4,2,11,23,15]
def quick_sort(L):
if len(L) <= 1: return L
else:
return quick_sort([i for i in L[1:] if i < L[0]]) + L[0:1] + quick_sort([j for j in L[1:] if j >= L[0]])返回递归函数拼接的列表,[i for i in L[1:] if i <= L[0]] 列表推导表达式,返回一个比 L[0] 小的列表,[j for j in L[1:] if j >= L[0]], 返回一个比L[0] 大的列表, 再加上L[0] 就构成完整的列表(此处必须L[0:1],因为这样返回的是列表,列表才能与列表拼接)
L[0:1]列表切片不包含右边的取值,list[-2:-1]也是,取到的是倒数第二元素作为列表,但list[:-1]除外(包含-1),取到的是整个列表
2、冒泡排序
冒泡重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
list1 = [1,4,2,3,10,8,7,5,4,2,11,23,15]
def bubble_sort(L):
#冒泡排序
count = len(L)
for i in range(count):
for j in range(i+1,count):
if L[j] < L[i]:
temp = L[i]
L[i] = L[j]
L[j] = temp
return L
print(bubble_sort(list1))其中,两变量交换可以直接 L[i],L[j] = L[j],L[i]3、插入排序
插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为O(n^2)。是稳定的排序方法。插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。
list1 = [1,4,2,3,10,8,7,5,4,2,11,23,15]
def insert_sort(L):
#插入排序
count = len(L)
for i in range(1,count):
j = i - 1
temp = L[i] #先记录L[i],后面循环会变
while j>=0:
if L[j] > temp:
L[j+1] = L[j]
L[j] = temp
j -= 1
return L
print(insert_sort(list1))4、希尔排序(Shell Sort)
希尔排序(Shell Sort)是插入排序的一种。也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因DL.Shell于1959年提出而得名。 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。
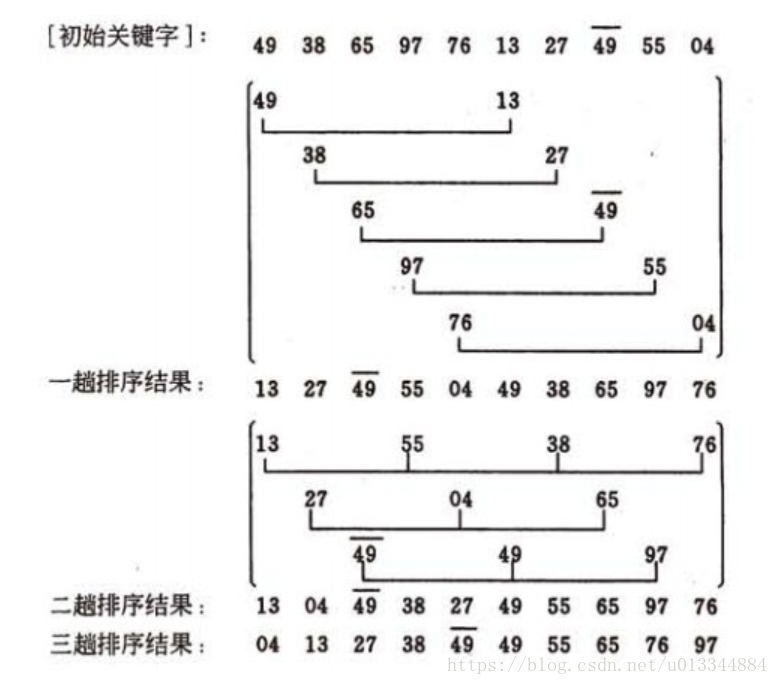
第一次增量的取法为: d=count/2;
第二次增量的取法为: d=(count/2)/2;
最后一直到: d=1;