转自:https://www.jianshu.com/p/fb97b21aeb1d
深入理解决策树
面试问题1:什么是决策树?
答:决策树是一种分类和回归的基本模型,可从三个角度来理解它,即:
- 一棵树
- if-then规则的集合,该集合是决策树上的所有从根节点到叶节点的路径的集合
- 定义在特征空间与类空间上的条件概率分布,决策树实际上是将特征空间划分成了互不相交的单元,每个从根到叶的路径对应着一个单元。决策树所表示的条件概率分布由各个单元给定条件下类的条件概率分布组成。实际中,哪个类别有较高的条件概率,就把该单元中的实例强行划分为该类别。
面试问题2:和其他模型比,它的优点?
答:主要的优点有两个:
- 模型具有可解释性,容易向业务部门人员描述。
- 分类速度快
当然也有其他优点,比如可以同时处理类别数据和数值数据。在运用分类决策树分类时,我们的数据一般会进行离散化
面试问题3:如何学习一棵决策树?
答:决策树的学习本质上就是从训练数据集中归纳出一组分类规则,使它与训练数据矛盾较小的同时具有较强的泛华能力。从另一个角度看,学习也是基于训练数据集估计条件概率模型(至此,回答完了模型部分,下面接着说策略和算法)。
决策树的损失函数通常是正则化的极大似然函数,学习的策略是以损失函数为目标函数的最小化(说完了策略,该说算法了)。
由于这个最小化问题是一个NP完全问题,现实中,我们通常采用启发式算法(这里,面试官可能会问什么是启发式算法,要有准备,SMO算法就是启发式算法)来近似求解这一最优化问题,得到的决策树是次最优的。
该启发式算法可分为三步:
- 特征选择
- 模型生成
- 决策树的剪枝
面试官此时心理活动:“嗯,看来这小子对决策树还是了解的,下面继续测测他的掌握深度,不信问不倒他!”
面试问题4:能具体谈谈这三个步骤吗?
答:从总体上看,这三个步骤就是一个递归地选择最优特征,并根据该特征对训练数据进行分割,使得对各个子数据集有一个最好的分类的过程,这个过程就是划分特征空间,构建决策树的过程。
面试官插问:如何选择最优特征呢?
简单讲,根据特征的分类能力去选择最优特征,特征分类能力的衡量通常采用信息增益或信息增益比。
面试官:谈谈你对信息增益和信息增益比的理解。
要理解信息增益,首先要理解熵这个概念。从概率统计的角度看,熵是对随机变量不确定性的度量,也可以说是对随机变量的概率分布的一个衡量。熵越大,随机变量的不确定性越大。对同一个随机变量,当它的概率分布为均匀分布时,不确定性最大,熵也最大。对有相同概率分布的不同的随机变量,取值越多的随机变量熵越大。(这是精华)。
其次,要理解条件熵的概念。正如熵是对随机变量不确定性的度量一样,条件熵是指,有相关的两个随机变量X和Y,在已知随机变量X的条件下随机变量Y的不确定性。定义为X给定条件下Y的条件概率分布的熵对X的数学期望。
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别为经验熵与经验条件熵。
所谓信息增益,也叫互信息,就是指集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,
用信息增益去选择特征有一个问题,即偏向于选择取值较多的特征。解决思路就是对取值较多的特征进行适当的惩罚(这里如果面试官感兴趣,可以说说惩罚思想,如L1,L2都是一种惩罚的做法),这就是信息增益比所干的事
面试官插问:递归的终止条件是什么呢?
通常有两个终止条件,一是所有训练数据子集被基本正确分类。二是没有合适的特征可选,即可用特征为0,或者可用特征的信息增益或信息增益比都很小了。
面试官提问:什么是决策树剪枝,怎么剪枝?
答:由于根据训练数据生成的决策树往往过于复杂,导致泛华能力比较弱,所以,实际的决策树学习中,会将已生成的决策树进行简化,以提高其泛华能力,这一过程叫做剪枝。具体说就是在已生成的决策树上裁掉一些子树或叶节点,并将其根节点或父节点作为新的叶节点。
具体剪枝时,有一般的剪枝算法和CART剪枝算法两种。下面分别叙述:
一般剪枝算法
不管是一般剪枝算法还是CART剪枝算法,都基于同一个思想,即减小决策树模型的整体损失函数,前面提到过,这个整体损失函数是正则化的极大似然函数,其形式如下:
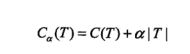
C(T)表示决策树T对训练数据集的预测误差,即模型与数据的拟合程度,|T|表示决策树的叶节点个数,即模型复杂度。α是权衡因子。较大的α促使选择较简单的模型。α=0表示只考虑模型与数据的拟合程度,不考虑模型的复杂度C(T)通常有两种衡量方法,一种用熵,一种用基尼指数
基尼指数也是一种衡量随机变量不确定性的指标,其公式如下:

一般剪枝算法,给定α后,通过不断剪枝来减小决策树模型的整体损失。
核心步骤是:假设一组叶节点回缩到其父节点之前与之后的整体树分别为T_B与T_A,其对应的损失函数值分别是C_α(T_B)与C_α(T_A),如果
C_α(T_A) ≦C_α(T_B)
则进行剪枝,将父节点变为新的叶节点。
递归地进行以上步骤,知道不能继续为止,得到损失函数最小的子树T_α。
具体实现这个算法时可采用动态规划(说出动态规划,应当是加分项)
CART剪枝算法
相比一般剪枝算法,CART剪枝算法的优势在于,不用提前确定α值,而是在剪枝的同时找到最优的α值。
下面简要叙述其数学过程,具体证明过程比较复杂,就不写了,感兴趣的可以参考其他资料。
对决策树T的每一个内部节点t,计算
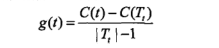
T_t代表以内部节点t为根节点的子树。 这样计算出的值表示剪枝后整体损失函数减少的程度。
选择g(t)值最小的内部节点t进行剪枝,得到一棵新树T_g(t)。
然后,对这棵新树继续上面的剪枝过程,又得到一棵新树。
如此,一直到单节点树,可以得到一系列的树,它们互相嵌套。用交叉验证法从中选出最优的子树T_g(t),它对应的α值为g(t)。