ResNet-BN tensorflow源码解析
标签(空格分隔): tensorflow 深度学习之网络结构
Github: https://github.com/tensorflow/models/blob/master/research/slim/nets/
Paper: https://arxiv.org/abs/1603.05027
残差单元
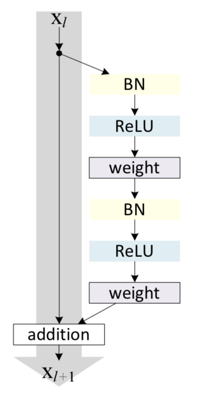
tensorflow 源码
残差单元
@slim.add_arg_scope
#该函数定义了一个残差单元
def bottleneck(inputs, depth, depth_bottleneck, stride, rate=1,
outputs_collections=None, scope=None):
"""Bottleneck residual unit variant with BN before convolutions.
This is the full preactivation residual unit variant proposed in [2]. See
Fig. 1(b) of [2] for its definition. Note that we use here the bottleneck
variant which has an extra bottleneck layer.
When putting together two consecutive ResNet blocks that use this unit, one
should use stride = 2 in the last unit of the first block.
Args:
inputs: A tensor of size [batch, height, width, channels].
depth: The depth of the ResNet unit output.
depth_bottleneck: The depth of the bottleneck layers.
stride: The ResNet unit's stride. Determines the amount of downsampling of
the units output compared to its input.
rate: An integer, rate for atrous convolution.
outputs_collections: Collection to add the ResNet unit output.
scope: Optional variable_scope.
Returns:
The ResNet unit's output.
"""
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4)
preact = slim.batch_norm(inputs, activation_fn=tf.nn.relu, scope='preact')
if depth == depth_in:
“'如果输入通道和输出通道个数相等,则直接根据stride对input进行下采样,否则对preact(input经过BN-ReLU得来的)进行卷积输出通道数为depth,求出shortcut特征图”'
shortcut = resnet_utils.subsample(inputs, stride, 'shortcut')
else:
shortcut = slim.conv2d(preact, depth, [1, 1], stride=stride,
normalizer_fn=None, activation_fn=None,
scope='shortcut')
#以下是求残差部分,通过1x1卷积通道数变为depth_bottleneck,然后3x3卷积特征提取,而后通道恢复为depth
residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride=1,
scope='conv1')
residual = resnet_utils.conv2d_same(residual, depth_bottleneck, 3, stride,
rate=rate, scope='conv2')
residual = slim.conv2d(residual, depth, [1, 1], stride=1,
normalizer_fn=None, activation_fn=None,
scope='conv3')
output = shortcut + residual#进行元素级相加,并输出
return slim.utils.collect_named_outputs(outputs_collections,
sc.name,
output)
残差块定义
"""
定义一个数据类型,用来存放残差块中,残差单元的配置,其中'unit_fn'表示为残差单元函数(bottleneck)
"""
class Block(collections.namedtuple('Block', ['scope', 'unit_fn', 'args'])):
"""A named tuple describing a ResNet block.
Its parts are:
scope: The scope of the `Block`.
unit_fn: The ResNet unit function which takes as input a `Tensor` and
returns another `Tensor` with the output of the ResNet unit.
args: A list of length equal to the number of units in the `Block`. The list
contains one (depth, depth_bottleneck, stride) tuple for each unit in the
block to serve as argument to unit_fn.
"""
"""
在残差网络中(ResNet-50,101,152),一般有四个残差块,每个残差块中有若干个残差单元,下面这个函数则是定义一个残差块,其中num_units这个参量决定了残差单元的个数,
"""
def resnet_v2_block(scope, base_depth, num_units, stride):
"""Helper function for creating a resnet_v2 bottleneck block.
Args:
scope: The scope of the block.
base_depth: The depth of the bottleneck layer for each unit.
num_units: The number of units in the block.
stride: The stride of the block, implemented as a stride in the last unit.
All other units have stride=1.
Returns:
A resnet_v2 bottleneck block.
"""
"""
从这个函数可以看出,每一个残差块输入到输出的stride作用在最后一个残差单元中,且depth_bottleneck是输出通道数(depth)的0.25
"""
return resnet_utils.Block(scope, bottleneck, [{
'depth': base_depth * 4,
'depth_bottleneck': base_depth,
'stride': 1
}] * (num_units - 1) + [{
'depth': base_depth * 4,
'depth_bottleneck': base_depth,
'stride': stride
}])定义ResNet-50、101、152、200的配置结构
"""
在这几个函数中,blocks这个list首先定义其残差结构,具体来说,就是每个残差块包含多少个残差单元,以及stride等等一些东西,再通过resnet_v2这个函数将blocks展开,并且定义残差网络的图模型
"""
"""
ResNet-50 -> [3,4,6,3]
ResNet-101 -> [3,4,23,3]
ResNet-152 -> [3,8,36,3]
ResNet-50 -> [3,24,36,3]
"""
def resnet_v2_50(inputs,
num_classes=None,
is_training=True,
global_pool=True,
output_stride=None,
spatial_squeeze=True,
reuse=None,
scope='resnet_v2_50'):
"""ResNet-50 model of [1]. See resnet_v2() for arg and return description."""
blocks = [
resnet_v2_block('block1', base_depth=64, num_units=3, stride=2),
resnet_v2_block('block2', base_depth=128, num_units=4, stride=2),
resnet_v2_block('block3', base_depth=256, num_units=6, stride=2),
resnet_v2_block('block4', base_depth=512, num_units=3, stride=1),
]#ResNet-50结构
return resnet_v2(inputs, blocks, num_classes, is_training=is_training,
global_pool=global_pool, output_stride=output_stride,
include_root_block=True, spatial_squeeze=spatial_squeeze,
reuse=reuse, scope=scope)
resnet_v2_50.default_image_size = resnet_v2.default_image_size
def resnet_v2_101(inputs,
num_classes=None,
is_training=True,
global_pool=True,
output_stride=None,
spatial_squeeze=True,
reuse=None,
scope='resnet_v2_101'):
"""ResNet-101 model of [1]. See resnet_v2() for arg and return description."""
blocks = [
resnet_v2_block('block1', base_depth=64, num_units=3, stride=2),
resnet_v2_block('block2', base_depth=128, num_units=4, stride=2),
resnet_v2_block('block3', base_depth=256, num_units=23, stride=2),
resnet_v2_block('block4', base_depth=512, num_units=3, stride=1),
]#ResNet-101结构
return resnet_v2(inputs, blocks, num_classes, is_training=is_training,
global_pool=global_pool, output_stride=output_stride,
include_root_block=True, spatial_squeeze=spatial_squeeze,
reuse=reuse, scope=scope)
resnet_v2_101.default_image_size = resnet_v2.default_image_size
def resnet_v2_152(inputs,
num_classes=None,
is_training=True,
global_pool=True,
output_stride=None,
spatial_squeeze=True,
reuse=None,
scope='resnet_v2_152'):
"""ResNet-152 model of [1]. See resnet_v2() for arg and return description."""
blocks = [
resnet_v2_block('block1', base_depth=64, num_units=3, stride=2),
resnet_v2_block('block2', base_depth=128, num_units=8, stride=2),
resnet_v2_block('block3', base_depth=256, num_units=36, stride=2),
resnet_v2_block('block4', base_depth=512, num_units=3, stride=1),
]#ResNet-152结构
return resnet_v2(inputs, blocks, num_classes, is_training=is_training,
global_pool=global_pool, output_stride=output_stride,
include_root_block=True, spatial_squeeze=spatial_squeeze,
reuse=reuse, scope=scope)
resnet_v2_152.default_image_size = resnet_v2.default_image_size
def resnet_v2_200(inputs,
num_classes=None,
is_training=True,
global_pool=True,
output_stride=None,
spatial_squeeze=True,
reuse=None,
scope='resnet_v2_200'):
"""ResNet-200 model of [2]. See resnet_v2() for arg and return description."""
blocks = [
resnet_v2_block('block1', base_depth=64, num_units=3, stride=2),
resnet_v2_block('block2', base_depth=128, num_units=24, stride=2),
resnet_v2_block('block3', base_depth=256, num_units=36, stride=2),
resnet_v2_block('block4', base_depth=512, num_units=3, stride=1),
]#ResNet-150结构
return resnet_v2(inputs, blocks, num_classes, is_training=is_training,
global_pool=global_pool, output_stride=output_stride,
include_root_block=True, spatial_squeeze=spatial_squeeze,
reuse=reuse, scope=scope)根据配置,建立残差图模型 resnet_v2
def resnet_v2(inputs,
blocks,
num_classes=None,
is_training=True,
global_pool=True,
output_stride=None,
include_root_block=True,
spatial_squeeze=True,
reuse=None,
scope=None):
"""
关键参数说明:
input: 网络的整个输入
blocks: 网络的配置(主要是残差块的配置)
num_classes: 默认为分类任务,分类的类别数
output_stride: 对于某些其他任务(比如图像分割),输出特征图和原始图像之间的的stride
"""
"""Generator for v2 (preactivation) ResNet models.
This function generates a family of ResNet v2 models. See the resnet_v2_*()
methods for specific model instantiations, obtained by selecting different
block instantiations that produce ResNets of various depths.
Training for image classification on Imagenet is usually done with [224, 224]
inputs, resulting in [7, 7] feature maps at the output of the last ResNet
block for the ResNets defined in [1] that have nominal stride equal to 32.
However, for dense prediction tasks we advise that one uses inputs with
spatial dimensions that are multiples of 32 plus 1, e.g., [321, 321]. In
this case the feature maps at the ResNet output will have spatial shape
[(height - 1) / output_stride + 1, (width - 1) / output_stride + 1]
and corners exactly aligned with the input image corners, which greatly
facilitates alignment of the features to the image. Using as input [225, 225]
images results in [8, 8] feature maps at the output of the last ResNet block.
For dense prediction tasks, the ResNet needs to run in fully-convolutional
(FCN) mode and global_pool needs to be set to False. The ResNets in [1, 2] all
have nominal stride equal to 32 and a good choice in FCN mode is to use
output_stride=16 in order to increase the density of the computed features at
small computational and memory overhead, cf. http://arxiv.org/abs/1606.00915.
Args:
inputs: A tensor of size [batch, height_in, width_in, channels].
blocks: A list of length equal to the number of ResNet blocks. Each element
is a resnet_utils.Block object describing the units in the block.
num_classes: Number of predicted classes for classification tasks.
If 0 or None, we return the features before the logit layer.
is_training: whether batch_norm layers are in training mode.
global_pool: If True, we perform global average pooling before computing the
logits. Set to True for image classification, False for dense prediction.
output_stride: If None, then the output will be computed at the nominal
network stride. If output_stride is not None, it specifies the requested
ratio of input to output spatial resolution.
include_root_block: If True, include the initial convolution followed by
max-pooling, if False excludes it. If excluded, `inputs` should be the
results of an activation-less convolution.
spatial_squeeze: if True, logits is of shape [B, C], if false logits is
of shape [B, 1, 1, C], where B is batch_size and C is number of classes.
To use this parameter, the input images must be smaller than 300x300
pixels, in which case the output logit layer does not contain spatial
information and can be removed.
reuse: whether or not the network and its variables should be reused. To be
able to reuse 'scope' must be given.
scope: Optional variable_scope.
Returns:
net: A rank-4 tensor of size [batch, height_out, width_out, channels_out].
If global_pool is False, then height_out and width_out are reduced by a
factor of output_stride compared to the respective height_in and width_in,
else both height_out and width_out equal one. If num_classes is 0 or None,
then net is the output of the last ResNet block, potentially after global
average pooling. If num_classes is a non-zero integer, net contains the
pre-softmax activations.
end_points: A dictionary from components of the network to the corresponding
activation.
Raises:
ValueError: If the target output_stride is not valid.
"""
with tf.variable_scope(scope, 'resnet_v2', [inputs], reuse=reuse) as sc:
end_points_collection = sc.original_name_scope + '_end_points'
with slim.arg_scope([slim.conv2d, bottleneck,
resnet_utils.stack_blocks_dense],
outputs_collections=end_points_collection):
with slim.arg_scope([slim.batch_norm], is_training=is_training):
net = inputs
if include_root_block:
if output_stride is not None:
if output_stride % 4 != 0:
raise ValueError('The output_stride needs to be a multiple of 4.')
output_stride /= 4
#在ResNet前两层分别是conv 3x3 stride 2 maxPooling 2x2,output_stride>4 且 output_stride
# We do not include batch normalization or activation functions in
# conv1 because the first ResNet unit will perform these. Cf.
# Appendix of [2].
with slim.arg_scope([slim.conv2d],
activation_fn=None, normalizer_fn=None):
net = resnet_utils.conv2d_same(net, 64, 7, stride=2, scope='conv1')
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
#stack_blocks_dense函数将blocks的配置展开,建立图模型
net = resnet_utils.stack_blocks_dense(net, blocks, output_stride)
# This is needed because the pre-activation variant does not have batch
# normalization or activation functions in the residual unit output. See
# Appendix of [2].
net = slim.batch_norm(net, activation_fn=tf.nn.relu, scope='postnorm')
# Convert end_points_collection into a dictionary of end_points.
end_points = slim.utils.convert_collection_to_dict(
end_points_collection)
if global_pool:#全局池化层
# Global average pooling.
net = tf.reduce_mean(net, [1, 2], name='pool5', keep_dims=True)
end_points['global_pool'] = net
if num_classes:#分类层
net = slim.conv2d(net, num_classes, [1, 1], activation_fn=None,
normalizer_fn=None, scope='logits')
end_points[sc.name + '/logits'] = net
if spatial_squeeze: #是否压缩,不压缩,则输出为[b,1,1,c];压缩 ,则为[b,c]
net = tf.squeeze(net, [1, 2], name='SpatialSqueeze')
end_points[sc.name + '/spatial_squeeze'] = net
end_points['predictions'] = slim.softmax(net, scope='predictions')
return net, end_points #输出 网络的输出以及记录在案的某些层的输出。。。单独说明stack_blocks_dense
@slim.add_arg_scope
"""
该函数把blocks中的残差块配置展开
关键参数说明:
net: 该子网络的输入;
blocks: 预定义的残差块们的配置;
output_stride: 该部分输出相对于输入的stride
store_non_strided_activations: 该子网络的stride 强行为1
"""
def stack_blocks_dense(net, blocks, output_stride=None,
store_non_strided_activations=False,
outputs_collections=None):
"""Stacks ResNet `Blocks` and controls output feature density.
First, this function creates scopes for the ResNet in the form of
'block_name/unit_1', 'block_name/unit_2', etc.
Second, this function allows the user to explicitly control the ResNet
output_stride, which is the ratio of the input to output spatial resolution.
This is useful for dense prediction tasks such as semantic segmentation or
object detection.
Most ResNets consist of 4 ResNet blocks and subsample the activations by a
factor of 2 when transitioning between consecutive ResNet blocks. This results
to a nominal ResNet output_stride equal to 8. If we set the output_stride to
half the nominal network stride (e.g., output_stride=4), then we compute
responses twice.
Control of the output feature density is implemented by atrous convolution.
Args:
net: A `Tensor` of size [batch, height, width, channels].
blocks: A list of length equal to the number of ResNet `Blocks`. Each
element is a ResNet `Block` object describing the units in the `Block`.
output_stride: If `None`, then the output will be computed at the nominal
network stride. If output_stride is not `None`, it specifies the requested
ratio of input to output spatial resolution, which needs to be equal to
the product of unit strides from the start up to some level of the ResNet.
For example, if the ResNet employs units with strides 1, 2, 1, 3, 4, 1,
then valid values for the output_stride are 1, 2, 6, 24 or None (which
is equivalent to output_stride=24).
store_non_strided_activations: If True, we compute non-strided (undecimated)
activations at the last unit of each block and store them in the
`outputs_collections` before subsampling them. This gives us access to
higher resolution intermediate activations which are useful in some
dense prediction problems but increases 4x the computation and memory cost
at the last unit of each block.
outputs_collections: Collection to add the ResNet block outputs.
Returns:
net: Output tensor with stride equal to the specified output_stride.
Raises:
ValueError: If the target output_stride is not valid.
"""
# The current_stride variable keeps track of the effective stride of the
# activations. This allows us to invoke atrous convolution whenever applying
# the next residual unit would result in the activations having stride larger
# than the target output_stride.
current_stride = 1
# The atrous convolution rate parameter.
rate = 1
for block in blocks: #展开四个残差块循环
with tf.variable_scope(block.scope, 'block', [net]) as sc:
block_stride = 1
for i, unit in enumerate(block.args): #展开每个残差块中的残差单元循环
if store_non_strided_activations and i == len(block.args) - 1: #强行为1
# Move stride from the block's last unit to the end of the block.
block_stride = unit.get('stride', 1)
unit = dict(unit, stride=1)
with tf.variable_scope('unit_%d' % (i + 1), values=[net]):
# If we have reached the target output_stride, then we need to employ
# atrous convolution with stride=1 and multiply the atrous rate by the
# current unit's stride for use in subsequent layers.
if output_stride is not None and current_stride == output_stride:
#这个实际调用的是bottleneck
net = block.unit_fn(net, rate=rate, **dict(unit, stride=1))
rate *= unit.get('stride', 1)
else:
net = block.unit_fn(net, rate=1, **unit)
current_stride *= unit.get('stride', 1)
if output_stride is not None and current_stride > output_stride:
raise ValueError('The target output_stride cannot be reached.')
# Collect activations at the block's end before performing subsampling.
net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net)
# Subsampling of the block's output activations.
if output_stride is not None and current_stride == output_stride:
rate *= block_stride
else:
net = subsample(net, block_stride)
current_stride *= block_stride
if output_stride is not None and current_stride > output_stride:
raise ValueError('The target output_stride cannot be reached.')
if output_stride is not None and current_stride != output_stride:
raise ValueError('The target output_stride cannot be reached.')
return netResNet的卷积、BN以及正则配置
def resnet_arg_scope(weight_decay=0.0001,
batch_norm_decay=0.997,
batch_norm_epsilon=1e-5,
batch_norm_scale=True,
activation_fn=tf.nn.relu,
use_batch_norm=True):
"""Defines the default ResNet arg scope.
TODO(gpapan): The batch-normalization related default values above are
appropriate for use in conjunction with the reference ResNet models
released at https://github.com/KaimingHe/deep-residual-networks. When
training ResNets from scratch, they might need to be tuned.
Args:
weight_decay: The weight decay to use for regularizing the model.
batch_norm_decay: The moving average decay when estimating layer activation
statistics in batch normalization.
batch_norm_epsilon: Small constant to prevent division by zero when
normalizing activations by their variance in batch normalization.
batch_norm_scale: If True, uses an explicit `gamma` multiplier to scale the
activations in the batch normalization layer.
activation_fn: The activation function which is used in ResNet.
use_batch_norm: Whether or not to use batch normalization.
Returns:
An `arg_scope` to use for the resnet models.
"""
batch_norm_params = {
'decay': batch_norm_decay,
'epsilon': batch_norm_epsilon,
'scale': batch_norm_scale,
'updates_collections': tf.GraphKeys.UPDATE_OPS,
'fused': None, # Use fused batch norm if possible.
}
with slim.arg_scope(
[slim.conv2d],
weights_regularizer=slim.l2_regularizer(weight_decay),
weights_initializer=slim.variance_scaling_initializer(),
activation_fn=activation_fn,
normalizer_fn=slim.batch_norm if use_batch_norm else None,
normalizer_params=batch_norm_params):
with slim.arg_scope([slim.batch_norm], **batch_norm_params):
# The following implies padding='SAME' for pool1, which makes feature
# alignment easier for dense prediction tasks. This is also used in
# https://github.com/facebook/fb.resnet.torch. However the accompanying
# code of 'Deep Residual Learning for Image Recognition' uses
# padding='VALID' for pool1. You can switch to that choice by setting
# slim.arg_scope([slim.max_pool2d], padding='VALID').
with slim.arg_scope([slim.max_pool2d], padding='SAME') as arg_sc:
return arg_sc