1. 前言
BN是深度学习中的一项里程碑技术。它在训练过程中使用small-batch-size统计来标准化激活的输出,但在推理过程中使用的是总体统计的。
作者主要观察结果是:由于网络中BN的堆栈作用,估计偏移会被累积,这对测试性能有不利的影响,BN的限制是它的mini-batch问题——随着Batch规模变小,BN的误差迅速增加。而batch-free normalization(BFN)可以阻止这种估计偏移的累计。这些观察结果也促使了XBNBlock的设计,该模块可以在残差网络的bottleneck块中用BFN替换一个BN。
在ImageNet和COCO基准测试上的实验表明,XBNBlock持续地提高了不同架构的性能,包括ResNet和ResNeXt,并且似乎对分布式偏移更稳健。
2. BN与BFN的区别
2.1 Batch normalization
设 x ∈ R d x∈R^d x∈Rd,是给定的多层感知器(MLP)的输入。在训练过程中,批归一化将m个小批数据中的每个神经元/通道归一化为:
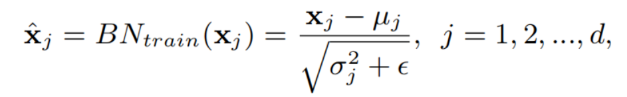
其中, μ j μ_j μj和 σ j 2 σ_j^2 σj2分别是每个神经元的均值和方差, ϵ ϵ ϵ是一个很小的数字,以防止分母为0。
在推理/测试过程中,BN需要层输入的总体均值和方差进行确定性预测,所以BN在训练和推理过程中的差异限制了其在递归神经网络中的使用,或者有损小批量训练的性能,因为估计可能不准确。
2.2 Batch-free normalization
Batch-free normalization避免沿Batch维度归一化,从而避免了统计量估计的问题。这些方法在训练和推理过程中使用了一致的操作。一种代表性的方法是层归一化(LN),它对每个训练样本神经元的层输入进行标准化,如下:
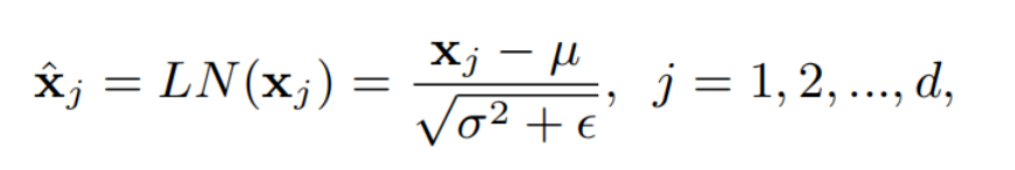
其中, μ μ μ和 σ 2 σ^2 σ2分别是每个神经元的均值和方差, ϵ ϵ ϵ是一个很小的数字,以防止分母为0。
LN通过进一步推广为组归一化(GN),将神经元划分为组,并分别在各组神经元内进行标准化。
通过改变组数,GN比LN更灵活,使其能够在小批量训练(如目标检测和分割)上获得良好的性能。虽然这些BFN方法可以在某些场景中很好地工作,但在大多数情况下,它们无法匹配BN的性能,并且在CNN架构中并不常用。
3. 代码实现
在实现之前,我们需要安装一个tensorflow添加的额外库,tensorflow_addons。
pip install tensorflow-addons==0.13.0
版本如下:

3.1 XBN Block的实现
def GroupNorm(x, num_groups=64, eps=1e-5):
if num_groups > x.shape[-1]:
num_groups = x.shape[-1]
return tfa.layers.GroupNormalization(num_groups, epsilon=eps)(x)
3.2 ResNet50 + XBN Block
from os import name
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
from tensorflow.keras.layers import Dense, ZeroPadding2D, Conv2D, MaxPool2D, GlobalAvgPool2D, Input, BatchNormalization, Activation, Add
from tensorflow.keras.models import Model
from plot_model import plot_model
def GroupNorm(x, num_groups=64, eps=1e-5):
if num_groups > x.shape[-1]:
num_groups = x.shape[-1]
return tfa.layers.GroupNormalization(num_groups, epsilon=eps)(x)
# 结构快
def block(x, filters, strides=1, conv_short=True):
if conv_short:
short_cut = Conv2D(filters=filters*4, kernel_size=1, strides=strides, padding='valid')(x)
short_cut = BatchNormalization(epsilon=1.001e-5)(short_cut)
else:
short_cut = x
# 三层卷积
x = Conv2D(filters=filters, kernel_size=1, strides=strides, padding='valid')(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = Activation('relu')(x)
x = Conv2D(filters=filters, kernel_size=3, strides=1, padding='same')(x)
# x = BatchNormalization(epsilon=1.001e-5)(x)
x = GroupNorm(x, num_groups=32)
x = Activation('relu')(x)
x = Conv2D(filters=filters*4, kernel_size=1, strides=1, padding='valid')(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = Add()([x, short_cut])
x = Activation('relu')(x)
return x
def Resnet50(inputs, classes):
x = ZeroPadding2D((3, 3))(inputs)
x = Conv2D(filters=64, kernel_size=7, strides=2, padding='valid')(x)
x = BatchNormalization(epsilon=1.001e-5)(x)
x = Activation('relu')(x)
x = ZeroPadding2D((1, 1))(x)
x = MaxPool2D(pool_size=3, strides=2, padding='valid')(x)
x = block(x, filters=64, strides=1, conv_short=True)
x = block(x, filters=64, conv_short=False)
x = block(x, filters=64, conv_short=False)
x = block(x, filters=128, strides=2, conv_short=True)
x = block(x, filters=128, conv_short=False)
x = block(x, filters=128, conv_short=False)
x = block(x, filters=128, conv_short=False)
x = block(x, filters=256, strides=2, conv_short=True)
x = block(x, filters=256, conv_short=False)
x = block(x, filters=256, conv_short=False)
x = block(x, filters=256, conv_short=False)
x = block(x, filters=256, conv_short=False)
x = block(x, filters=256, conv_short=False)
x = block(x, filters=512, strides=2, conv_short=True)
x = block(x, filters=512, conv_short=False)
x = block(x, filters=512, conv_short=False)
x = GlobalAvgPool2D()(x)
x = Dense(classes, activation='softmax')(x)
return x
3.3 MobileNetv2 + XBN Block
倒残差结构如下:

import tensorflow_addons as tfa
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import (
Activation, BatchNormalization, Conv2D, DepthwiseConv2D, Dropout,ZeroPadding2D, Add, Dense,
GlobalAveragePooling2D, Input, Reshape
)
from tensorflow.keras.models import Model
from tensorflow.keras import backend as K
def correct_pad(inputs, kernel_size):
img_dim = 1
input_size = K.int_shape(inputs)[img_dim:(img_dim + 2)]
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
if input_size[0] is None:
adjust = (1, 1)
else:
adjust = (1 - input_size[0] % 2, 1 - input_size[1] % 2)
correct = (kernel_size[0] // 2, kernel_size[1] // 2)
return ((correct[0] - adjust[0], correct[0]),
(correct[1] - adjust[1], correct[1]))
# 保证特征层为8得倍数
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
def relu6(x):
return K.relu(x, max_value=6)
def Conv2D_block(inputs, filters, kernel_size=(3, 3), strides=(1, 1)):
x = Conv2D(
filters=filters, kernel_size=kernel_size, padding='valid',
use_bias=False, strides=strides
)(inputs)
x = BatchNormalization(epsilon=1e-3,
momentum=0.999)(x)
x = Activation(relu6)(x)
return x
def GroupNorm(x, num_groups=64, eps=1e-5):
if num_groups > x.shape[-1]:
num_groups = x.shape[-1]
return tfa.layers.GroupNormalization(num_groups, epsilon=eps)(x)
def bottleneck(inputs, expansion, stride, alpha, filters):
in_channels = K.int_shape(inputs)[-1]
pointwise_conv_filters = int(filters * alpha)
pointwise_filters = _make_divisible(pointwise_conv_filters, 8)
x = inputs
# 数据扩充
x = Conv2D(expansion * in_channels,
kernel_size=1,
padding='same',
use_bias=False,
activation=None)(x)
x = BatchNormalization(epsilon=1e-3,
momentum=0.999)(x)
x = Activation(relu6)(x)
if stride == 2:
x = ZeroPadding2D(padding=correct_pad(x, 3))(x)
# 深度卷积
x = DepthwiseConv2D(kernel_size=3,
strides=stride,
activation=None,
use_bias=False,
padding='same' if stride == 1 else 'valid')(x)
# x = BatchNormalization(epsilon=1e-3,
# momentum=0.999)(x)
x = GroupNorm(x, num_groups=16, eps=1e-5)
x = Activation(relu6)(x)
# 1x1卷积用于改变通道数
x = Conv2D(pointwise_filters,
kernel_size=1,
padding='same',
use_bias=False,
activation=None)(x)
x = BatchNormalization(epsilon=1e-3,
momentum=0.999)(x)
x = Activation(relu6)(x)
if (in_channels == pointwise_filters) and stride == 1:
return Add()([inputs, x])
return x
def MobilenetV2_xbn(inputs, alpha=0.35, dropout=1e-3, classes=17):
first_block_filters = _make_divisible(32 * alpha, 8)
x = ZeroPadding2D(padding=correct_pad(inputs, 3))(inputs)
x = Conv2D_block(x, filters=first_block_filters, kernel_size=3, strides=(2, 2))
x = bottleneck(x, filters=16, alpha=alpha, stride=1, expansion=1)
x = bottleneck(x, filters=24, alpha=alpha, stride=2, expansion=6)
x = bottleneck(x, filters=24, alpha=alpha, stride=1, expansion=6)
x = bottleneck(x, filters=32, alpha=alpha, stride=2, expansion=6)
x = bottleneck(x, filters=32, alpha=alpha, stride=1, expansion=6)
x = bottleneck(x, filters=32, alpha=alpha, stride=1, expansion=6)
x = bottleneck(x, filters=64, alpha=alpha, stride=2, expansion=6)
x = bottleneck(x, filters=64, alpha=alpha, stride=1, expansion=6)
x = bottleneck(x, filters=64, alpha=alpha, stride=1, expansion=6)
x = bottleneck(x, filters=64, alpha=alpha, stride=1, expansion=6)
x = bottleneck(x, filters=96, alpha=alpha, stride=1, expansion=6)
x = bottleneck(x, filters=96, alpha=alpha, stride=1, expansion=6)
x = bottleneck(x, filters=96, alpha=alpha, stride=1, expansion=6)
x = bottleneck(x, filters=160, alpha=alpha, stride=2, expansion=6)
x = bottleneck(x, filters=160, alpha=alpha, stride=1, expansion=6)
x = bottleneck(x, filters=160, alpha=alpha, stride=1, expansion=6)
x = bottleneck(x, filters=320, alpha=alpha, stride=1, expansion=6)
if alpha > 1.0:
last_block_filters = _make_divisible(1280 * alpha, 8)
else:
last_block_filters = 1280
x = Conv2D_block(x, filters=last_block_filters, kernel_size=1, strides=(1, 1))
x = GlobalAveragePooling2D()(x)
shape = (1, 1, int(last_block_filters))
x = Reshape(shape, name='reshape_1')(x)
x = Dropout(dropout, name='dropout')(x)
x = Conv2D(classes, (1, 1),padding='same', name='conv_preds')(x)
x = Activation('softmax', name='act_softmax')(x)
x = Reshape((classes,), name='reshape_2')(x)
return x