一般我们训练深度学习模型都是等训练完成后才能查看loss acc等这些指标,然而当我们模型设计并不正确或者出现了过拟合甚至于数据拟合出现了很严重错误,但是在训练很深的网络的时候一般都要等上好久,我就遇到过用RestNet50训练100张图跑了三四天。这时候我们该浪费时间继续train呢还是等指标出来再判断,我们都不知道。庆幸的是现在我们用keras可以随时监督训练的过程,一旦训练出现了问题可以随时终止,然后也可以保存当前模型等下次训练的时候可以继续开始训练。
举个例子:用之前写的miniVGG来训练cifar10数据集:
先是重载keras的模块:trainmonitor.py
from keras.callbacks import BaseLogger
import matplotlib.pyplot as plt
import numpy as np
import json
import os
class TrainingMonitor(BaseLogger):
def __init__(self, figPath, jsonPath=None, startAt=0):
# 保存loss图片到指定路径,同时也保存json文件
super(TrainingMonitor, self).__init__()
self.figPath = figPath
self.jsonPath = jsonPath
# 开始模型开始保存的开始epoch
self.startAt = startAt
def on_train_begin(self, logs={}):
# 初始化保存文件的目录dict
self.H = {}
# 判断是否存在文件和该目录
if self.jsonPath is not None:
if os.path.exists(self.jsonPath):
self.H = json.loads(open(self.jsonPath).read())
# 开始保存的epoch是否提供
if self.startAt > 0:
for k in self.H.keys():
# 循环保存历史记录,从startAt开始
self.H[k] = self.H[k][:self.startAt]
def on_epoch_end(self, epoch, logs={}):
# 不断更新logs和loss accuracy等等
for (k, v) in logs.items():
l = self.H.get(k, [])
l.append(v)
self.H[k] = l
# 查看训练参数记录是否应该保存
# 主要是看jsonPath是否提供
if self.jsonPath is not None:
f = open(self.jsonPath, 'w')
f.write(json.dumps(self.H))
f.close()
# 保存loss acc等成图片
if len(self.H["loss"]) > 1:
N = np.arange(0, len(self.H["loss"]))
plt.style.use("ggplot")
plt.figure()
plt.plot(N, self.H["loss"], label="train_loss")
plt.plot(N, self.H["val_loss"], label="val_loss")
plt.plot(N, self.H["acc"], label="train_acc")
plt.plot(N, self.H["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy [Epoch {}]".format(len(self.H["loss"])))
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(self.figPath)
plt.close()
cifar10_monitor.py
import matplotlib
matplotlib.use("Agg")
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from miniVGG import MiniVGGNet
from keras.optimizers import SGD
from keras.callbacks import LearningRateScheduler
from trainingmonitor import TrainingMonitor
from keras.datasets import cifar10
from keras.datasets import cifar100
import matplotlib.pyplot as plt
import numpy as np
import argparse
import os
def step_decay(epoch):
initAlpha = 0.01
factor = 0.5
dropEvery = 5
alpha = initAlpha * (factor ** np.floor((1 + epoch) / dropEvery))
return float(alpha)
ap = argparse.ArgumentParser()
ap.add_argument("-o", "--output", required=True, help="path to the output loss/accuracy plot")
ap.add_argument("-m", "--model", required=True, help="path to save train model")
args = vars(ap.parse_args())
print("[INFO] process ID: {}".format(os.getpid()))
print("[INFO] loading CIFAR-10 dataset")
((trainX, trainY), (testX, testY)) = cifar100.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# 标签0-9代表的类别string
labelNames = ['airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print("[INFO] compiling model...")
# callbacks = [LearningRateScheduler(step_decay)]
# opt = SGD(lr=0.01, decay=0.01 / 70, momentum=0.9, nesterov=True)
opt = SGD(lr=0.01, momentum=0.9, nesterov=True)
model = MiniVGGNet.build(width=32, height=32, depth=3, classes=100)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=['accuracy'])
print(model.summary())
figPath = os.path.sep.join([args["output"], "{}.png".format(os.getpid())])
jsonPath = os.path.sep.join([args["output"], "{}.json".format(os.getpid())])
callbacks = [TrainingMonitor(figPath, jsonPath=jsonPath)]
print("[INFO] training network Lenet-5")
H = model.fit(trainX, trainY, validation_data=(testX, testY), batch_size=64, epochs=100,
callbacks=callbacks, verbose=1)
model.save(args["model"])
print("[INFO] evaluating Lenet-5..")
preds = model.predict(testX, batch_size=64)
print(classification_report(testY.argmax(axis=1), preds.argmax(axis=1),
target_names=labelNames))
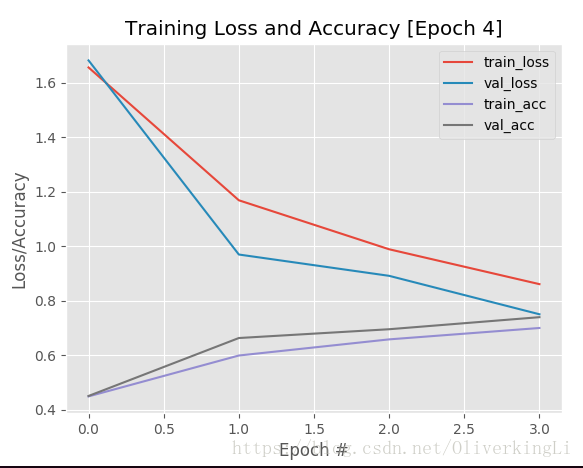
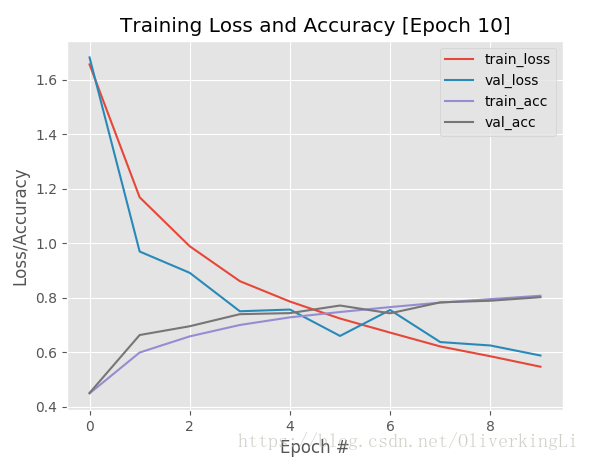
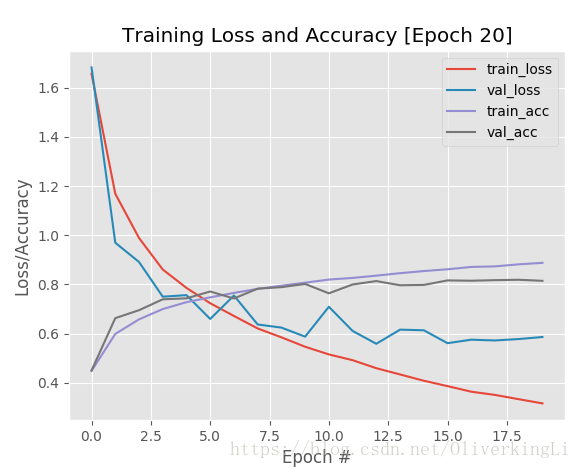
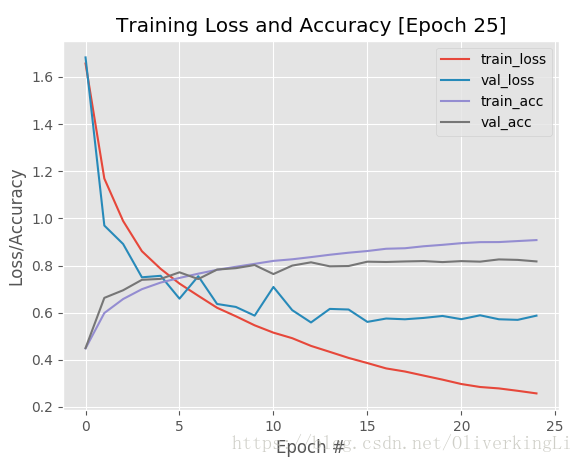
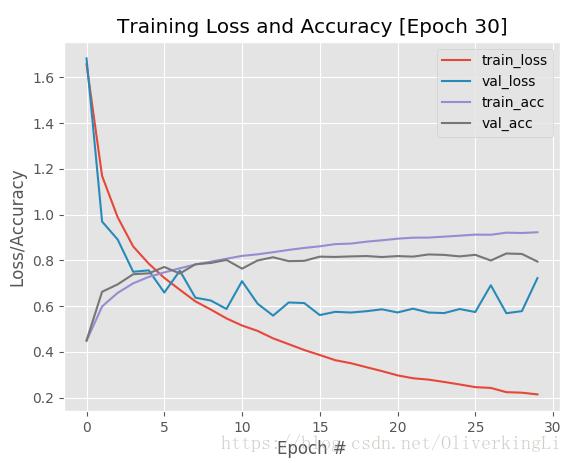
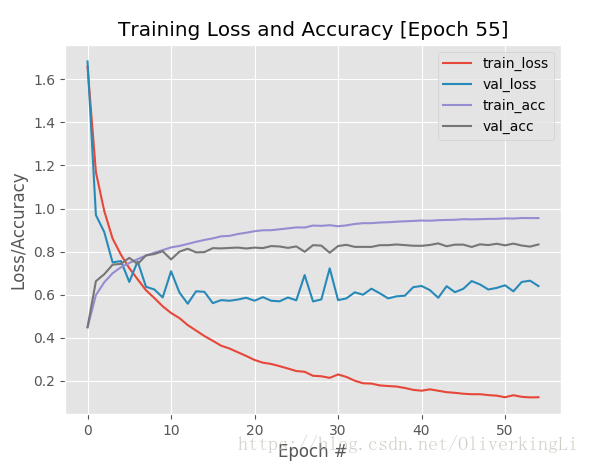

这样其实就可以看出,在接近25epoch的时候,就有明显的过拟合了,那么我们就可以终止目前的训练,因为之后大批次的训练也没意义。还要让我们的GPU高负荷高温运转...
然后接着说怎么去保存训练过程的模型,一般训练都是完全完成一次训练后才保存一个最终模型,万一在中途已经出现beyond acceptance的过拟合了,那么最终的保存的模型反而不是最好了。这时候中间训练的某个epoch恰恰才是很适合的模型,可我们没有保存到,这就很che dan。keras让我们可以很好的解决这个问题,不得不说,keras相对于tensorflow使用确实友好。下面给了demo:
demo-cifar10-checkpoint.py
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from miniVGG import MiniVGGNet
from keras.callbacks import ModelCheckpoint
from keras.optimizers import SGD
from keras.datasets import cifar10
import argparse
import os
ap = argparse.ArgumentParser()
ap.add_argument("-w", "--weights", required=True, help="path toweights directory")
args = vars(ap.parse_args())
print("[INFO] loading CIFAR-10 dataset")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# 标签0-9代表的类别string
labelNames = ['airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print("[INFO] compiling model...")
opt = SGD(lr=0.01, decay=0.01 / 40, momentum=0.9, nesterov=True)
model = MiniVGGNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
# 定义模型保存的模板
fname = os.path.sep.join([args["weights"], "weights={epoch:03d}-{val_loss:.4f}.hdf5"])
# 调用keras的模块然后根据参数进行保存,具体的monitor mode等参数我觉得最后的学习方法就是直接去看原文档
checkpoint = ModelCheckpoint(fname, monitor="val_loss", mode="min", save_best_only=True, verbose=1)
callbacks = [checkpoint]
print("[INFO] training our network MiniVGG...")
H = model.fit(trainX, trainY, validation_data=(testX, testY), batch_size=64, epochs=50, callbacks=callbacks, verbose=2)
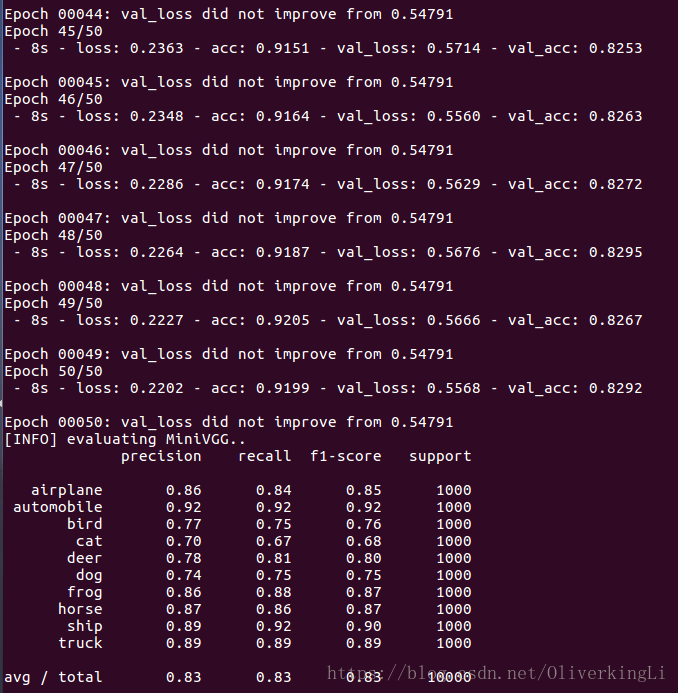
print("[INFO] evaluating MiniVGG..")
preds = model.predict(testX, batch_size=64)
print(classification_report(testY.argmax(axis=1), preds.argmax(axis=1),
target_names=labelNames))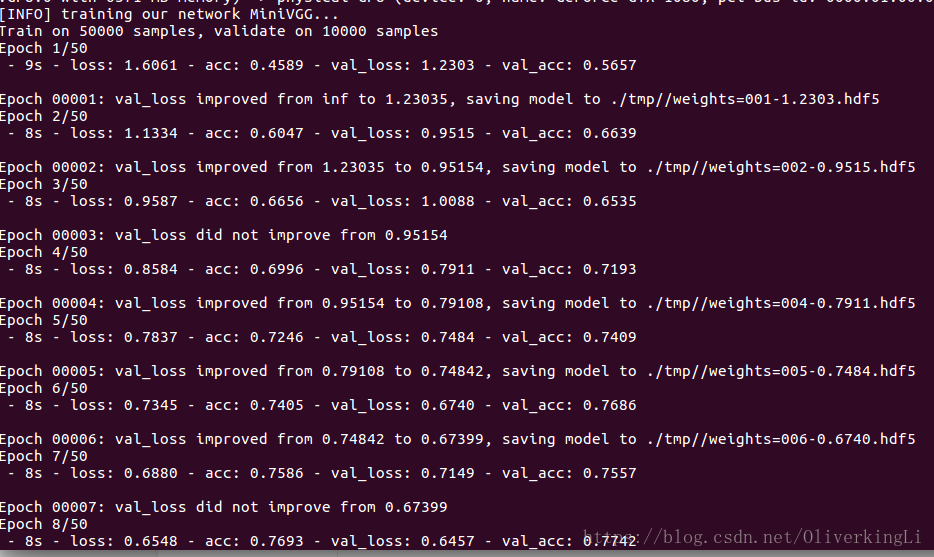

如果说你嫌弃每次训练一个epoch,只要loss或者acc有朝着正向方向变化,都要保存一个模型,岂不是很浪费硬盘存储,OK,那你可以只用保存整个训练过程最好的一个模型:
demo-cifar10-best.py
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from miniVGG import MiniVGGNet
from keras.callbacks import ModelCheckpoint
from keras.optimizers import SGD
from keras.datasets import cifar10
import argparse
import os
ap = argparse.ArgumentParser()
ap.add_argument("-w", "--weights", required=True, help="path toweights directory")
args = vars(ap.parse_args())
print("[INFO] loading CIFAR-10 dataset")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# 标签0-9代表的类别string
labelNames = ['airplane', 'automobile', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
print("[INFO] compiling model...")
opt = SGD(lr=0.01, decay=0.01 / 40, momentum=0.9, nesterov=True)
model = MiniVGGNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
# fname = os.path.sep.join([args["weights"], "weights={epoch:03d}-{val_loss:.4f}.hdf5"])
# 这里就改为一个文件保存模型,同样的是保存validation loss最低的那个模型
checkpoint = ModelCheckpoint(args["weights"], monitor="val_loss", mode="min", save_best_only=True, verbose=1)
callbacks = [checkpoint]
print("[INFO] training our network MiniVGG...")
H = model.fit(trainX, trainY, validation_data=(testX, testY), batch_size=64, epochs=50, callbacks=callbacks, verbose=2)
print("[INFO] evaluating MiniVGG..")
preds = model.predict(testX, batch_size=64)
print(classification_report(testY.argmax(axis=1), preds.argmax(axis=1),
target_names=labelNames))原理其实就是当loss或者acc朝着好的方向训练的时候,就覆盖掉原来的那个次的。
这里再多说一个可视化我们模型的小trick,也mark一下:
我在ubuntu16上需要先安装graphviz所依赖的库
sudo apt-get install graphviz
pip install graphviz
pip install pydotdemo.py
from lenet import LeNet
from miniVGG import MiniVGGNet
from keras.utils import plot_model
model1 = LeNet.build(28, 28, 1, 10)
plot_model(model1, to_file="lenet-5-mnist.png", show_shapes=True)
model12 = LeNet.build(32, 32, 3, 10)
plot_model(model12, to_file="lenet-5-cifar10.png", show_shapes=True)
model13 = LeNet.build(32, 32, 3, 100)
plot_model(model13, to_file="lenet-5-cifar100.png", show_shapes=True)
model2 = MiniVGGNet.build(28, 28, 1, 10)
plot_model(model2, to_file="miniVGGNet-mnist.png", show_shapes=True)
model21 = MiniVGGNet.build(32, 32, 3, 10)
plot_model(model21, to_file="miniVGGNet-cifar10.png", show_shapes=True)
model22 = MiniVGGNet.build(32, 32, 3, 100)
plot_model(model22, to_file="miniVGGNet-cifar100.png", show_shapes=True)
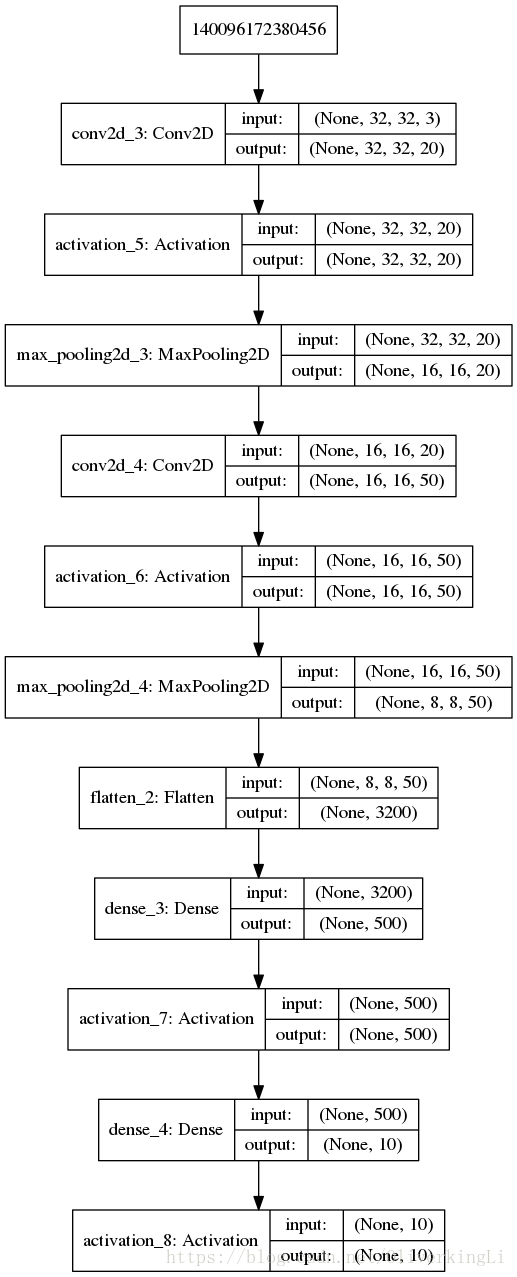
lenet-5-cifar10
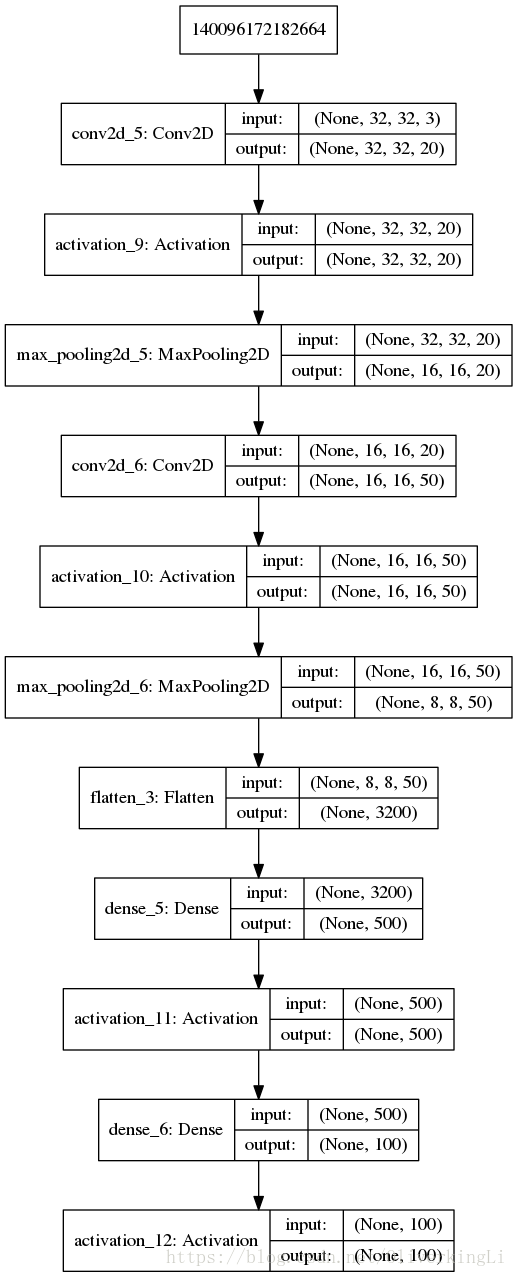
lenet-5-cifar100

lenet-cifar-mnist
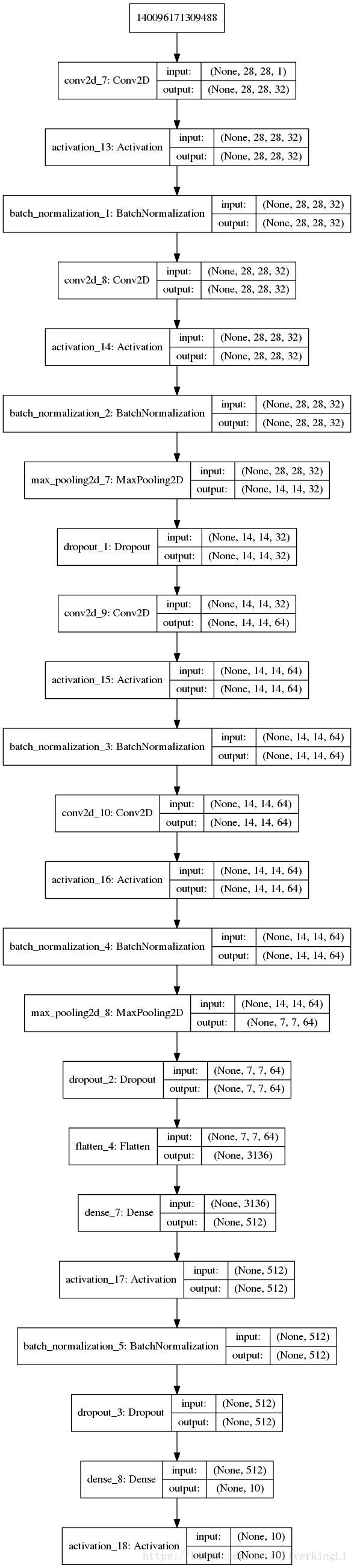
minivgg-mnist
这种奇技淫巧可以帮助我们可视化验证自己设计的网络结构是否在预期内合理。