本文为博主原创文章,未经博主允许不得转载。
本文为专栏《Python从零开始进行AIGC大模型训练与推理》系列文章,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。
GPT2模型环境搭建与调试请参考博文《GPT系列训练与部署—GPT2环境配置与模型训练》和《ColossalAI GPT2分布式训练调试配置—GPT系列训练与部署》,地址分别为“https://blog.csdn.net/suiyingy/article/details/128711444”和“https://blog.csdn.net/suiyingy/article/details/128806531”。本节主要详细介绍GPT2模型结构原理及其训练调试过程。
另外,本专栏具体更新可关注文章下方公众号,也可关注本专栏。所有相关文章会在《Python从零开始进行AIGC大模型训练与推理》中进行更新,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。所有AIGC类模型部署的体验效果将在RdFast小程序中同步上线。
1 Transformer主要结构
Transformer模型是一种用于NLP的神经网络模型,由Google的研究人员在2017年提出并发表在论文《Attention is All you need》。该模型的核心是自注意力机制(self-attention),可以在处理长序列时避免RNN中的梯度消失问题,同时也可以更好地捕捉序列中元素之间的关系。Transformer模型是一种革命性的神经网络架构,它在自然语言处理领域取得了显著的成果,并且已成为该领域的重要基础。
Transformer模型总体结构如下图所示,属于典型的编码-解码结构,左侧为编码结构,右侧为解码结构。

图1 Transformer模型结构
1.1 自注意力机制(self-attention)
自注意力机制是指模型进行特征提取时会关注到自身数据之间的相关性。注意力表示关注数据的权重大小。假设有一组序列由A、B、C、D构成,那么A分别受到A、B、C、D影响的大小便相当于注意力大小,即A特征提取时注意到A、B、C、D的程度大小。
Transformer为了衡量这种注意力取值提出了一种QKV(Query,Key,Value)编码模型。Q、K、V相当于原始数据在新的空间下的表征方式。假设输入序列特征维度为(N_seq,C_embedding),N_seq为输入序列长度,C_embedding为序列中每个元素的特征维度,经过全连接层Linear(C_embedding, C_qkv)之后,输出特征维度为(N_seq,C_qkv)。Transformer分别使用三组这样的全连接操作将原始序列转换为Q、K、V,维度均为(N_seq,C_qkv)。


图2 QKV过程示意图
这可以理解为用Q、K、V空间来表示原始数据,Q相当于定义了一种原始数据的查询索引,可类比原序列中的元素位置。(K,V)表示数据取值,采用这种Key-Value的方式来表示数据的好处在于计算注意力大小时不影响取值,即取值与注意力大小进行了解耦。
注意力大小用Q和K之间的相关性来表示,相关性越大,则注意力权重越大。如下图所示,相关性用矩阵乘法(向量相乘)来进行计算,即Q x KT,那么相乘后输出维度为(N_seq, N_seq)。其每一行代表当前元素与所有全元素的相关性。为了保持输出数据的分布特性,相乘后数据需除以sqrt(dk),dk即为上述C_qkv。显然,除以sqrt(dk)并不会改变注意力的相对大小,而是对整体幅度进行了调整。

图3 注意力计算
我们希望注意力权重之和为1,各个权重取值相当于占比多少。那么输出的相乘后数据需要通过Softmax来完成这种权重转化。假设输入序列长度为3(x1, x2, x3),那么经过Softmax后的输出分别为exp(x1)/(exp(x1)+exp(x2)+exp(x3))、exp(x2)/(exp(x1)+exp(x2)+exp(x3))和exp(x1)/(exp(x3)+exp(x2)+exp(x3))。
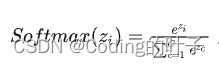
图4 Softmax
注意力权重与V相乘,即加权求和,可得到输出结果,维度为(N, C_qkv)。这将输入数据维度从(N_seq,C_embedding)转为(N, C_qkv),相当于用新的序列来表示原序列,并且新的序列考虑到元素之间的相关性。
1.2 自注意力机制与卷积神经网络(CNN)
一般卷积神经网络通过全连接进行特征提取时相当于得到V,网络模型训练完成时,全连接层所有参数是固定的。任何输入都将使用相同的全连接参数进行变换。注意力机制是通过QK来对V进行加权操作。不同输入情况下QK得到的注意力权重是不一样的,这相当于全连接层参数随输入不同而发生变化。因此,使用自注意力机制后,输入特征提取方式更加多样化,可提取更加丰富且有效的特征。当然,参数量也会相应增加。
在计算机视觉领域,研究人员也设计了很多受输入影响的卷积操作,例如PAConv和Deformable Conv等。
1.3 多头注意力机制(Multi-head Attention)
多头注意力机制相当于多次采用自注意力机制提取原始特征并进行拼接融合。我们也可以将上述自注意力过程类比成一次卷积过程,多头注意力机制相当于改变输出通道数量。假设单个自注意力机制模块的输出维度为(N, C_qkv),且注意力机制模块的数量为MA(即Head数量,Multi-head),那么输出维度为MA x N x C_qkv。输出特征进行拼接后的维度为N x (MA x C_qkv),这相当于进行了一次特征融合。在卷积神经网络中,对于拼接的特征,通常会进一步采用一层卷积或全连接来对拼接后的特征进行整体融合。Transformer也用到了这种结构,即Feed-Forward网络。除此之外,Transformer还多次用到残差结构来融合输入特征。
为了使注意力特征与输入特征保持一致,MA x C_qkv应与C_embedding保持一致。假设C_embedding为512,C_qkv为64,那么多头的数量MA应为8。假设C_embedding为768,C_qkv为64,那么多头的数量MA应为12。
1.4 多层堆叠
如果注意力模块输出维度和输入维度保持一致,那么该模块可进行多层堆叠,即前一个模块输出(N_seq,C_embedding)作为后一模块输入(N_seq,C_embedding),如下文即将介绍的GPT2模型结构。GPT2结构常见层数如下所示。
表1 GPT2层数与参数量
参数量 层数 词向量长度
117M 12 768
345M 24 1024
762M 36 1280
1542M 48 1600
2 GPT2模型结构
GPT系列模型仅使用了transformer的编码结构,并采用多层堆叠的方式进行。下图是12层GPT2结构示意图。每一层都是一个注意力机制模块。

图5 12层GPT2
3 GPT2训练程序
接下来所介绍的GPT2程序来源于Colossal-AI框架,地址为“https://github.com/hpcaitech/ColossalAI-Examples/tree/main/language/gpt”。其环境搭建与调试方法在本专栏之前文章中有详细介绍。
3.1 输入数据与分词
3.1.1 输入数据
测试所使用的数据为OpenWebText,其下载与预处理过程见《GPT系列训练与部署—GPT2环境配置与模型训练》,地址为“https://blog.csdn.net/suiyingy/article/details/128711444”。处理后原始数据保存于train.json,其数据结构为{'text': text, 'url': unique_url},示例如下所示。
{"text": "The space station looks like an airplane or a very bright star moving across the sky, except it doesn't have flashing lights or change direction. It will also be moving considerably faster than a typical airplane (airplanes generally fly at about 600 miles per hour; the space station flies at 17,500 miles per hour).\n\nBelow is a time-lapse photo of the space station moving across the sky.\n\nThe International Space Station is seen in this 30 second exposure as it flies over Elkton, VA early in the morning, Saturday, August 1, 2015. Photo Credit: NASA/Bill Ingalls\n\nVisit the NASA Johnson Flickr Photostream", "url": "http://spotthestation.nasa.gov/sightings/view.cfm?country=United_States®ion=Arizona&city=Phoenix#.UvPTWWSwLpM"}模型输入数据为text中的文本,这里将文本允许的最大分词长度设置为1024,即GPT2模型输入的序列长度N_seq为1024。
3.1.2 分词
自然语言处理中的分词是指将一段文本按照词语进行切分的过程。分词是自然语言处理领域中的重要基础任务,其主要目的是将连续的自然语言文本切分成具有一定语义意义的词汇序列,以便于进一步的语义分析。
在中文等语言中,词语之间没有像英文中用空格隔开的方式,而是需要通过分词来进行识别和提取。分词对于机器翻译、信息检索、情感分析等领域都非常重要,因为单个字符或字母并不能表达出完整的意思,只有将其组合成合适的词语才能更好地理解和处理自然语言文本。
分词操作时我们会有一本字典,这个字典里记录了所有词语及其序号。例如,这里的字典是GPT2Tokenizer,共有50257个词。其中,“<|endoftext|>”是它的最后一个词,也是它的unk token。最后一个词的索引序号为50256。“tokenizer = GPT2Tokenizer.from_pretrained('gpt2')”加载了整个字典。根据词语查询序号的字典为tokenizer.encoder,如tokenizer.encoder['bot'];根据序号查询词语的字典为tokenizer.decoder,如tokenizer.decoder[13645]。需要注意,这个字典并不包含中文。因此,不同的自然语言处理任务所采用的分词字典也可能会出现差异。
分词最终是将一段文本转换为其相应索引序号组成的序列,即程序中的input_ids。由于将输入序列的最大长度N_seq设置为1024,那么当文本分词后序列实际长度大于1024时,将保留前1024个分词,并删除剩余分词。当文本分词后序列实际实际长度小于1024时,那么需要填充至1024个分词。程序中使用<|endoftext|>进行填充,因此input_ids长度不足1024时用50256进行填充。
程序中分词输出的另一个部分是attention_mask,这个主要是用于标识出有效分词。属于有效分词的位置取值为1,填充补齐的位置取值为0。
GPT2分词过程关键程序如下所示,程序位于ColossalAI-Examples/labguage/gpt/dataset/webtext.py。用户可在该文件相关位置设置断点进行程序调试。
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')#50257个词
tokenizer.pad_token = tokenizer.unk_token#'<|endoftext|>'
encoded_data = tokenizer(raw_data, padding=True, truncation=True, max_length=seq_len, return_tensors='pt')
self.data = encoded_data['input_ids']#长度大于1024时将保留前1024个分词,并删除剩余分词;长度不足1024时用50256进行填充。
self.attention_mask = encoded_data['attention_mask']#属于有效分词的位置取值为1,填充补齐的位置取值为0。
torch.save((seq_len, self.data, self.attention_mask), encoded_data_cache_path)#第一次运行时将结果保存,后续可直接加载。3.2 主体结构
下面GPT2模型训练程序介绍过程中已将训练的Batch Size设置为1。输入是长度为1024分词序列input_id及其attention_mask,维度均为1x1024。1表示Batch Size大小。程序位于“titans/layer/block/gpt_block.py”,可在相应位置设置断点进行调试
#计算输入有效程度
torch.where(input_ids!=50256)[0].size()
#计算attention_mask长度,与输入有效长度相等
attention_mask.sum()
x = self.embed(input_ids)
#attention_mask取值为1的地方转换为0,取值为0的地方转为-10000。较大的负数在通过Softmax求解自注意力权重时取值接近于0。
if attention_mask is not None:
batch_size = input_ids.shape[0]
attention_mask = attention_mask.view(batch_size, -1)
attention_mask = col_nn.partition_batch(attention_mask)
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
attention_mask = attention_mask.to(dtype=x.dtype) # fp16 compatibility
attention_mask = (1.0 - attention_mask) * -10000.0
for block in self.blocks:#最小配置 12层,隐藏变量维度为768
x, attention_mask = block(x, attention_mask)
x = self.head(self.norm(x))#1x1024x503043.2.1 词向量
上述数据处理过程已将输入文本转换为一个长度为1024的序列。词向量则是进一步用一个特征向量来表示每个词,特征向量的长度即为隐藏变量的长度(HIDDEN_SIZE)。词向量处理函数的入口为“x = self.embed(input_ids)”,输入序列维度为BATCH_SIZE x SEQ_LEN(1x1024),输出序列维度为BATCH_SIZE x SEQ_LEN x HIDDEN_SIZE。
词向量处理有较多方法,一些研究会专门致力于该方向。最简单的方法是准备一个词向量字典。程序中字典中词的数量为50304,每个词用768(HIDDEN_SIZE)维向量表示。这个字典可以采用随机生成的方式得到,并且每一个词向量都已归一化,归一化后的均值为0,方差为1。最后,根据1024个分词的索引序号来进行字典查询得到相应序号的词向量。
由于序列存在先后顺序,其位置编码也可以用一个序号来表示,进而也可以用一组位置向量来表征这种先后顺序。由于序列最大长度已设置为1024,那么位置索引的向量字典维度为1024x768。词向量和位置向量相加得到总的词向量,维度为1024x768。
词向量处理的关键程序如下所示,程序位于“titans/layer/embedding/gpt_embedding.py”,可在相应位置设置断点进行调试,输出维度为1x1024x768。
seq_length = input_ids.size(1)
if position_ids is None:
bs = input_ids.size(0)
position_ids = torch.arange(seq_length, dtype=torch.long, device=get_current_device()).unsqueeze(0)
position_ids = position_ids.repeat(bs, 1)
# the size of input_ids is (BATCH_SIZE, SEQ_LEN)
# the size of x after word_embeddings is (BATCH_SIZE, SEQ_LEN, HIDDEN_SIZE)
x = self.word_embeddings(input_ids) + self.position_embeddings(position_ids)#词向量与位置向量,1x1024x768
if self.tokentype_embeddings is not None and tokentype_ids is not None:
x = x + self.tokentype_embeddings(tokentype_ids)
x = self.dropout(x)#增加轻微扰动
return x3.2.2 注意力模块
根据前文描述,该GPT2程序中采用了12层完全一样的注意力模块。每个模块由两个残差模块组成,分别是自注意力模块和Feed Forward前馈模块,并且输入会首先进行归一化。归一化后的均值为0,方差为1。12层注意力模块的最终输出均为1x1024x768。
(a)自注意力模块
第一个残差模块如下图所示,其特征提取采用了多头自注意力机制。其中,多头数量为12,QKV特征维度为64,因而最终输出特征维度经过拼接后仍然为768,即12x64。

图6 第一个残差模块
对应程序如下所示,程序位于“titans/layer/block/gpt_block.py”,可在相应位置设置断点进行调试,输出维度为1x1024x768。attention_mask取值为1的地方转换为0,取值为0的地方转为-10000。较大的负数在通过Softmax求解自注意力权重时取值接近于0。
if not self.apply_post_layernorm:
residual = x
x = self.norm1(x)#dropout操作之后数据不再是归一化的,需重新归一化,特征维度上均值为0,方差为1
residual = x #1x024x768
x = residual + self.attn(x, attention_mask)#1x1024x768程序中关键部分在与自注意力特征提取,即self.attn(x, attention_mask)。具体程序位于“titans/layer/attention/gpt_attention.py”,可在相应位置设置断点进行调试,输出维度为1x1024x768。主要步骤如下所示:
1)计算QKV,输入维度为1x1024x768。QKV是在768维度上进行变换,各自需要转换成64维度,共64*3个输出。由于多头的数量为12,因此转换后特征总维度为64*3*12,即2304。因此,通过全连接层VanillaLinear(768,2304)计算得到1x1024x2304维度输出。经过维度变换,程序分别提取Q、K、V分量,维度均为1x12x1024x64。
2)计算自注意力权重得分矩阵。Q与K相乘并除以sqrt(64)得到1x12x1024x1024初步权重矩阵。程序分别将当前词之后的权重设置为较大绝对值的负数,这是因为下一个词的预测结果仅与之前的内容有关。另一方面,权重矩阵与attention_mask相加同样将无效位置权重设置为较大绝对值的负数。经过Softmax操作后,每个词的注意力权重之和为1,并且之前绝对值较大的负数相应位置权重取值接近于0。输出维度为1x12x1024x1024。
3)加权求和。V经过加权求和后维度仍然为1x12x1024x64。
4)多头特征拼接。1x12x1024x64维度特征拼接后得到1x1024x768维新特征。
5)特征拼接融合。1x1024x768维特征拼接后通过全连接层VanillaLinear(768,768)进行再次融合,并加入dropout扰动。最终输出维度为1x1024x768。
自注意力特征提取的关键程序解析如下所示。
# the size of x is (BATCH_SIZE, SEQ_LEN, HIDDEN_SIZE)
# the size of qkv is (BATCH_SIZE, SEQ_LEN, HIDDEN_SIZE*3)
qkv = self.query_key_value(x)#计算QKV,1x1024x2304
all_head_size = qkv.shape[-1] // 3#多头隐藏变量维度,768
num_attention_heads = divide(all_head_size, self.attention_head_size)#计算头的数量,每个头的基本隐藏变量数量为64,那么768/64=12
new_qkv_shape = qkv.shape[:-1] + (num_attention_heads, 3 * self.attention_head_size)#1x1024x12x192,q、k、v的特征维度各为64
qkv = qkv.view(new_qkv_shape)#1x1024x12x192
qkv = qkv.permute((0, 2, 1, 3))#1x12x1024x192
# the size of q is (BATCH_SZIE, NUM_HEADS, SEQ_LEN, HIDDEN_SIZE//NUM_HEADS)
q, k, v = torch.chunk(qkv, 3, dim=-1)#q、k、v分量,1x12x1024x64, 1x12x1024x64, 1x12x1024x64
# the size of x after matmul is (BATCH_SIZE, NUM_HEADS, SEQ_LEN, SEQ_LEN)
x = torch.matmul(q, k.transpose(-1, -2))#自注意力机制权重得分矩阵,1x12x1024x1024
x = x / math.sqrt(self.attention_head_size)# x / sqrt(64),1x12x1024x1024
q_len, k_len = q.size(-2), k.size(-2)#1024, 1024
causal_mask = torch.tril(torch.ones((q_len, k_len), dtype=torch.uint8, device=get_current_device())).view(1, 1, q_len, k_len).bool()#下三角矩阵,当前词仅与之前词相关,每一行代表一组权重,1x1x1024x1024
x = torch.where(causal_mask, x, torch.tensor(-1e4, dtype=x.dtype, device=get_current_device()))#True为x,False为-1e4,1x12x1024x1024
x = x + attention_mask#无效处全部置为较大负值,从而在softmax操作后权重得分基本为0,1x12x1024x1024。
x = self.softmax(x)#转换为权重概率得分,1x12x1024x1024
x = self.attention_dropout(x)#对数据增加扰动,1x12x1024x1024
# the size of x after matmul is (BATCH_SZIE, NUM_HEADS, SEQ_LEN, HIDDEN_SIZE//NUM_HEADS)
x = torch.matmul(x, v)#对v进行加权求和,1x12x1024x64
x = x.transpose(1, 2)#1x1024x12x64
new_context_layer_shape = x.size()[:-2] + (all_head_size,)#1x1024x768
# the size of x after reshape is (BATCH_SZIE, SEQ_LEN, HIDDEN_SIZE)
x = x.reshape(new_context_layer_shape)#多头拼接,1x1024x768
# the size of x after dense is (BATCH_SZIE, SEQ_LEN, HIDDEN_SIZE)
x = self.dense(x)#Linear(768, 768),相当于再次进行一次特征融合,1x1024x768
x = self.dropout(x)#对数据增加扰动,1x1024x768
return x#1x1024x768(b)Feed ForWard前馈模块
第二个残差模块如下图所示。

图7 第二个残差模块
对应程序如下所示,程序位于“titans/layer/block/gpt_block.py”,可在相应位置设置断点进行调试,输出维度为1x1024x768。前馈过程主要由两层全连接层VanillaLinear(768, 3072)和VanillaLinear(3072, 768)来完成,最终输出维度仍然为1x1024x768。
residual = x
x = self.norm2(x)#dropout操作之后数据不再是归一化的,需重新归一化,特征维度上均值为0,方差为1
x = residual + self.mlp(x)#VanillaLinear(768, 3072)、VanillaLinear(3072, 768)、dropout,再次特征融合注意力模块的最终输出均为1x1024x768。
(2)Head
Head的作用是将特征映射回带解决问题对应的空间,函数入口为“x = self.head(self.norm(x))”。经过注意力模块后程序所提取的特征维度为1x1024x768。我们需要根据每个768维度特征计算出其属于哪个分词,即对特征进行分类。词向量字典共有50304个类别。
GPT2 Head由一层LayerNorm归一化层和一个全连接层(768,50304)组成,输出维度为1x1024x50304。
3.3 损失函数
GPT2模型训练采用的是一种无监督方式,逐一采用当前序列预测下一个分词。因此,其标签也为输入分词索引序号。第N个分词提取到的特征与1~N个分词均相关联,并采用该特征预测第N+1个分词索引序号。根据输入分词序列,第N+1个分词序号是已知。
对应程序如下所示,程序位于“tians/loss/lm_loss/gpt_lmloss.py”,可在相应位置设置断点进行调试,输出维度为1x1024x768。损失函数为交叉损失商函数(CrossEntropyLoss),这也是最常使用的分类损失函数。损失函数的预测输入特征维度为1023x50304,标签维度为1023。
class GPTLMLoss(nn.Module):
def __init__(self):
super().__init__()
self.loss = col_nn.CrossEntropyLoss()
def forward(self, logits, labels):
shift_logits = logits[..., :-1, :].contiguous()#预测结果
shift_labels = labels[..., 1:].contiguous()#下一个取值为预测值对应的标签
# Flatten the tokens
# shift_logits.view(-1, shift_logits.size(-1)).shape,1023x50304
# shift_labels.view(-1).shape,1023
return self.loss(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))4 训练命令与结果
GPT2模型环境搭建与调试请参考博文《GPT系列训练与部署—GPT2环境配置与模型训练》和《ColossalAI GPT2分布式训练调试配置—GPT系列训练与部署》,地址分别为“https://blog.csdn.net/suiyingy/article/details/128711444”和“https://blog.csdn.net/suiyingy/article/details/128806531”。
ColosssalAI-Examples的GPT训练命令为“colossalai run --nproc_per_node=2 train_gpt.py --config=gpt2_configs/gpt2_vanilla.py --from_torch”。运行结果如下图所示。

图8 训练结果示意图
5 模型保存与加载
5.1 模型保存
在ColossalAI-Examples/language/gpt/train_gpt.py文件中,将hook_list中的hooks.SaveCheckpointHook(checkpoint_dir='./ckpt')取消注释后即可保存训练模型。默认设置下,训练模型会保存在当前目录下的ckpt之中。如果采用调试的方式运行,训练模型可能会被保存到用户的home目录下,可以用命令“find ~ -name ckpt”来进行搜索。
5.2 模型训练加载
ColossalAI-Examples/language/gpt/train_gpt.py文件中默认是没有加载预训练模型的接口,我们需要自己写一个入口程序,如下所示。新的程序添加到114行“logger.info('Build optimizer', ranks=[0])”之后,即第115行。
if os.path.exists('ckpt'):
logger.info('Loading pretrained model from ckpt', ranks=[0])
from collections import OrderedDict
new_state_dict = OrderedDict()
state_dict = torch.load('ckpt')
for k, v in state_dict['model'].items():
name = k[6:] # remove `module.`
new_state_dict[name] = v
model.load_state_dict(new_state_dict)本文为博主原创文章,未经博主允许不得转载。
本文为专栏《Python从零开始进行AIGC大模型训练与推理》系列文章,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。
另外,本专栏具体更新可关注文章下方公众号,也可关注本专栏。所有相关文章会在《Python从零开始进行AIGC大模型训练与推理》中进行更新,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。所有AIGC类模型部署的体验效果将在RdFast小程序中同步上线。