一. 什么是并查集
应用
1.网络中节点间的连接状态
- 网络是个抽象概念: 用户之间形成的网络
2.数学中集合的实现
对于一组数据, 主要支持两个动作
- 并:union(p,q)
- 查:isConnected(p,q)
接口
UF.java
public interface UF {
int getSize();
boolean isConnected(int p, int q);
void unionElements(int p, int q);
}
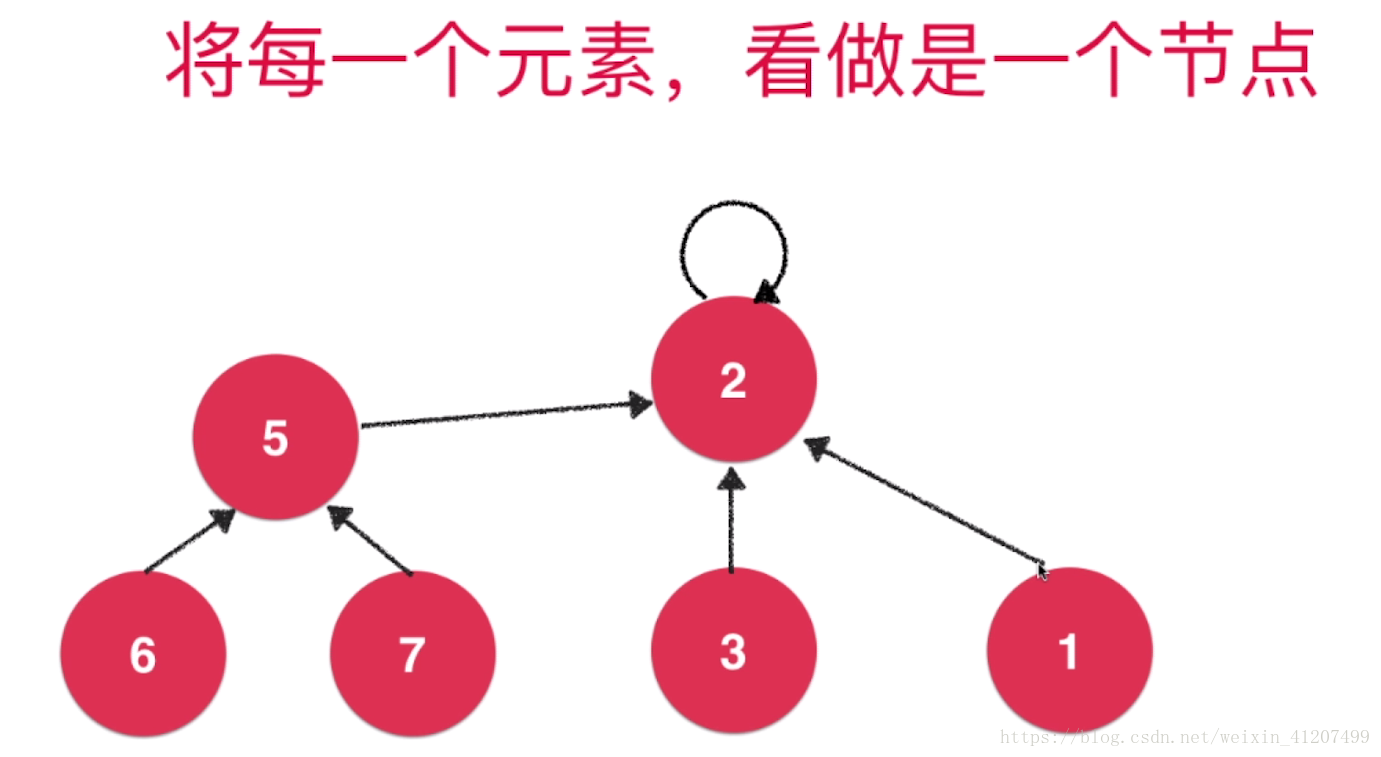
二. 实现思路:Quick Find
并查集的基本数据表示
集合id1: 0 1 2 3 4
集合id2: 5 6 7 8 9
Quick Find 是查找 数据对应的 集合id号
简单地用数组实现并查集
UnionFind1.java
public class UnionFind1 implements UF {
private int[] id;
public UnionFind1(int size){
id = new int[size];
for(int i = 0; i < id.length; i++){
id[i] = i; //每一个元素所属不同的集合
}
}
@Override
public int getSize(){
return id.length;
}
//查找元素p 的集合编号
private int find(int p){
if(p < 0 && p >= id.length){
throw new IllegalArgumentException("p is out of bound");
}
return id[p];
}
// 查看元素p和q是否为同一集合
@Override
public boolean isConnected(int p, int q){
return find(p) == find(q);
}
//合并元素p和元素q所属的集合
@Override
public void unionElements(int p, int q){
int pID = find(p);
int qID = find(q);
if(pID == qID){
return;
}
for(int i =0; i < id.length; i++){
if(id[i] == pID){
id[i] = qID;
}
}
}
}
三. 实现思路:Quick Union
过程理解
如下图:
节点7 和 节点3做union:
节点7的根节点指向节点3的根节点
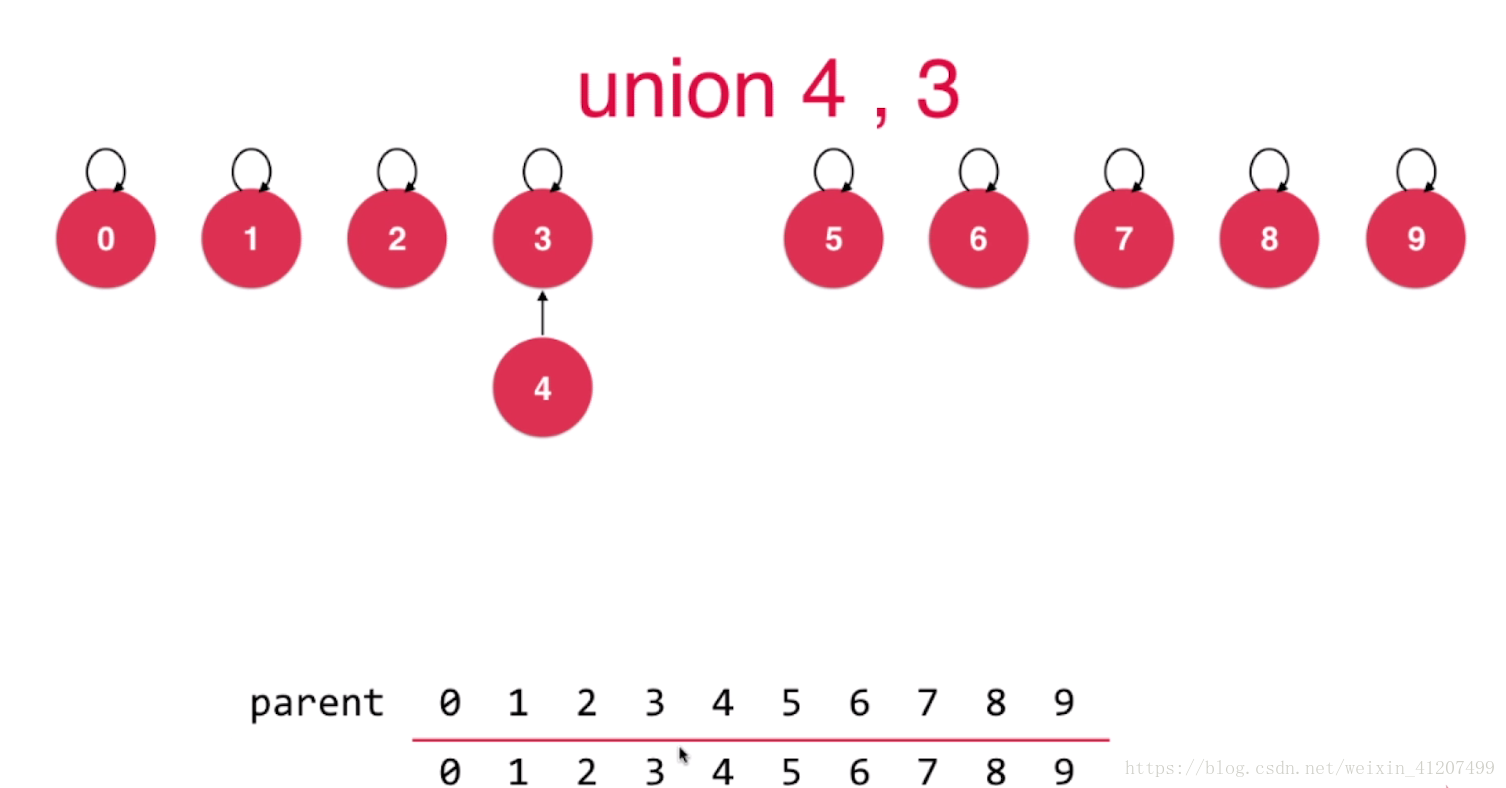
初始情况下, 每个节点都是一个树. 假设一开始有10个节点, 要实现union(4,3)。则如下图
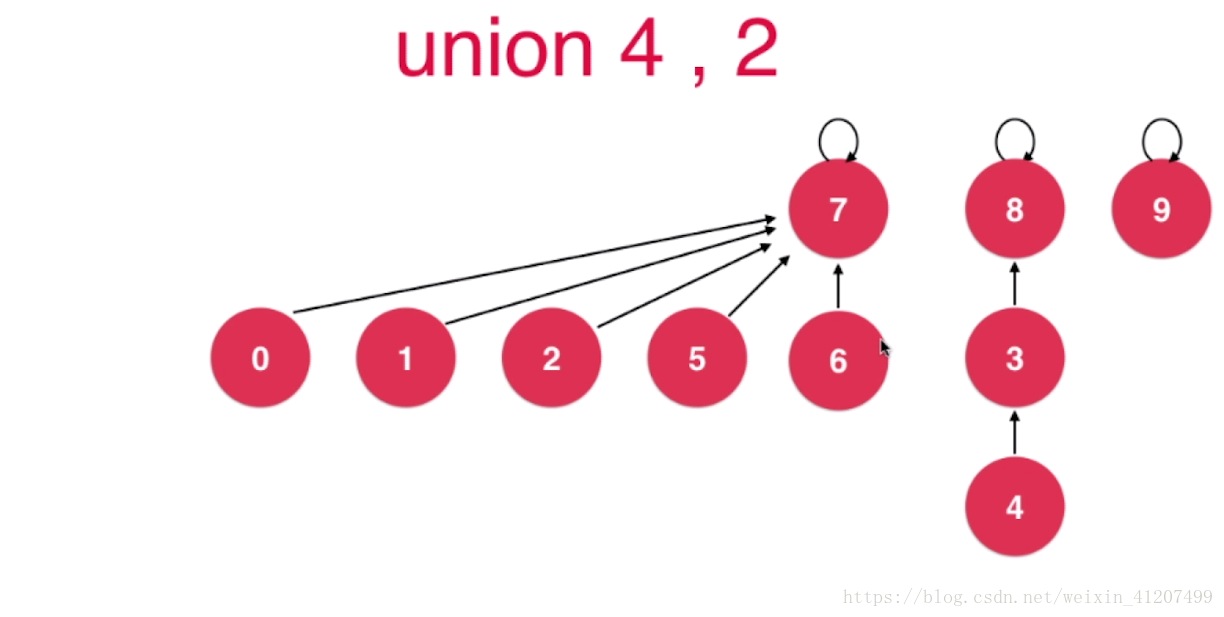
在 union(9,8) union(3,8) union(2,1) union(6,5) union(5,0) union(7,2) union(6,2) 之后, 得到如下结果

代码实现
基于上面的逻辑以及 由孩子指向父亲的特点编写代码
UnionFind2.java
public class UnionFind2 implements UF {
private int[] parent;
public UnionFind2(int size) {
parent = new int[size];
for(int i = 0; i < size; i++){
parent[i] = i; //每个元素都是一棵树,parent是它自己 每棵树的根结点相当于之前的 集合id号
}
}
@Override
public int getSize(){
return parent.length;
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
private int find(int p){
if(p < 0 && p >= parent.length){
throw new IllegalArgumentException("p is out of bound.");
}
while(p != parent[p]){ // 直到找到根结点
p = parent[p];
}
return p;
}
// 查看p和q 是否为 同一集合
// O(h)复杂度,h为树的高度
@Override
public boolean isConnected(int p, int q){
return find(p) == find(q);
}
// 合并元素p和q所属的集合
// O(h)的时间复杂度
@Override
public void unionElements(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot){
return;
}
parent[pRoot] = qRoot;
}
}
四. 基于size优化
UnionFind1 与 UnionFind2 速度对比
Main.java
import java.util.Random;
public class Main {
//执行m次 合并 和 查询操作
private static double testUF(UF uf, int m) {
int size = uf.getSize();
Random random = new Random();
long startTime = System.nanoTime();
for (int i = 0; i < m; i++) {
int a = random.nextInt(size);
int b = random.nextInt(size);
uf.unionElements(a, b);
}
for (int i = 0; i < m; i++) {
int a = random.nextInt(size);
int b = random.nextInt(size);
uf.isConnected(a, b);
}
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
public static void main(String[] args) {
// write your code here
int size = 100000;
int m = 10000;
UnionFind1 uf1 = new UnionFind1(size);
System.out.println("Unifind1: " + testUF(uf1, m) + " s");
UnionFind2 uf2 = new UnionFind2(size);
System.out.println("Unifind2: " + testUF(uf2, m) + " s");
}
}
结果(size=100000, m=10000)
Unifind1: 0.315987283 s
Unifind2: 0.014769037 s
将size不变, m=100000, 结果 :
Unifind1: 4.980790593 s
Unifind2: 10.85276505 s
Unionfind2 变慢了, 原因
1. Unionfind2 的find函数,在查询过程中会访问碎片化的地址空间。
而UnionFind2的find函数 是基于数组的,java语言有优化
2. UnionFind2 的isConnected 复杂度 高于UnionFind1的isConnected, m的增大会使更多的元素组织在一个集合中。深度h会很高
基于size优化
原理:
在Union(4,3)时,本来时4->3, 但如果 如果4的树深度大于3的树深度, 改为3->4
UnionFind3.java(UnionFind2的基础上 加入了sz 并优化了unionElements)
public class UnionFind3 implements UF {
private int[] parent;
private int[] sz; //sz[i]表示以i为根的集合元素个数
public UnionFind3(int size) {
parent = new int[size];
sz = new int[size];
for(int i = 0; i < size; i++){
parent[i] = i;
sz[i] = 1;
}
}
@Override
public int getSize(){
return parent.length;
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
private int find(int p){
if(p < 0 && p >= parent.length){
throw new IllegalArgumentException("p is out of bound.");
}
while(p != parent[p]){ // 直到找到根结点
p = parent[p];
}
return p;
}
// 查看p和q 是否为 同一集合
// O(h)复杂度,h为树的高度
@Override
public boolean isConnected(int p, int q){
return find(p) == find(q);
}
// 合并元素p和q所属的集合
// O(h)的时间复杂度
@Override
public void unionElements(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot){
return;
}
if(sz[pRoot] < sz[qRoot]){
parent[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
}
else{
parent[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
}
}
五. 基于rank的优化
原理
如下图所示情况:
如果让8->7, 会使合并后的树的深度增加。更合理的情况是7->8。 这样就是基于rank的优化
代码实现
在UnionFind3的基础上, sz改为rank 并修改unionElements函数
UnionFind4.java
public class UnionFind4 implements UF {
private int[] parent;
private int[] rank; //rank[i]表示以i为根的树 的 层数(深度)
public UnionFind4(int size) {
parent = new int[size];
rank = new int[size];
for(int i = 0; i < size; i++){
parent[i] = i;
rank[i] = 1;
}
}
@Override
public int getSize(){
return parent.length;
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
private int find(int p){
if(p < 0 && p >= parent.length){
throw new IllegalArgumentException("p is out of bound.");
}
while(p != parent[p]){ // 直到找到根结点
p = parent[p];
}
return p;
}
// 查看p和q 是否为 同一集合
// O(h)复杂度,h为树的高度
@Override
public boolean isConnected(int p, int q){
return find(p) == find(q);
}
// 合并元素p和q所属的集合
// O(h)的时间复杂度
@Override
public void unionElements(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot){
return;
}
//根据两个元素所在树的rank的不同判断合并的方向
//将rank低的集合合并到rank高的集合上
if(rank[pRoot] < rank[qRoot]){
parent[pRoot] = qRoot;
}
else if(rank[pRoot] < rank[qRoot]){
parent[qRoot] = pRoot;
}
else{
parent[qRoot] = pRoot;
rank[pRoot] += 1;
}
}
}
在Main.java中测试,得到结果如下
Unionfind1: 5.040893966 s
Unionfind2: 10.61027382 s
Unionfind3: 0.015299379 s
Unionfind4: 0.012385086 s
六.基于路径压缩的优化
优化原理
如下图中的三种路径其实是等价的, 我们可以根据图中思路来压缩深度h

我们将压缩路径的代码放在find函数中
在寻找根节点的过程中, 执行:
parent[p] = parent[parent[p]]
即在向上寻找时 本来指向父节点的 改为指向爷爷节点
代码实现
UnionFind5.java 基于UnionFind4 只要在find中增加一行代码
...
private int find(int p){
if(p < 0 && p >= parent.length){
throw new IllegalArgumentException("p is out of bound.");
}
while(p != parent[p]){
parent[p] = parent[parent[p]]; //本来指向父节点的 改为指向爷爷节点
p = parent[p];
}
return p;
}
...
Main中进行速度测试
Main.java
...
public static void main(String[] args) {
// write your code here
int size = 10000000;
int m = 10000000;
// UnionFind1 uf1 = new UnionFind1(size);
//
// System.out.println("Unionfind1: " + testUF(uf1, m) + " s");
//
//
// UnionFind2 uf2 = new UnionFind2(size);
// System.out.println("Unionfind2: " + testUF(uf2, m) + " s");
UnionFind3 uf3 = new UnionFind3(size);
System.out.println("Unionfind3: " + testUF(uf3, m) + " s");
UnionFind4 uf4 = new UnionFind4(size);
System.out.println("Unionfind4: " + testUF(uf4, m) + " s");
UnionFind5 uf5 = new UnionFind5(size);
System.out.println("Unionfind5: " + testUF(uf5, m) + " s");
}
}
结果
Unionfind3: 5.252558689 s
Unionfind4: 5.062379705 s
Unionfind5: 3.984109604 s
最优的压缩
如果我们想让每棵树都路径压缩到 深度只有2, 我们需要使用递归
UnionFind6基于UnionFind5, 只修改find函数
...
private int find(int p){
if(p < 0 && p >= parent.length){
throw new IllegalArgumentException("p is out of bound.");
}
if(p != parent[p]){
parent[p] = find(parent[p]); //使用递归, 直接取到根节点
}
return parent[p];
}
...
速度测试结果:
Unionfind3: 5.240926873 s
Unionfind4: 4.854475902 s
Unionfind5: 3.90928111 s
Unionfind5: 4.298501956 s 因为递归的消耗,UnionFind5优于UnionFind6