案例来源:@AI科技评论
案例地址:https://mp.weixin.qq.com/s/621j43q_rTWYm3EupgsSGw
1. 目标:打造通用智能问答平台
2. 智能问答平台的三种类型:
1)任务驱动型:如查天气、查汇率等
2)信息获取型:目前业界落地最多的智能问答平台类型
3)通用闲聊型:如微软小冰、苹果siri,使对话系统更人性化,同时可以收集更多用户信息,包括用户情感表达等
3. 问答领域的三种问答数据:

1)结构化知识:如FAQ和KG
2)非结构化:如表格和文档
3)多模态、跨媒体的数据:如VQA(视觉问答),以及可能存在的音频、视频问答的语料库
4. 在结构化FAQ上如何打造智能问答:
1)问题预处理模块:问询改写、错词纠正、同义词替换
2)答案召回:要求首先是快,其次是召回率要高,对准确率要求不高
a. 词汇计数法:优点是简单,对长尾词效果好;缺点是不能理解相似词汇之间的关系
b. 语言模型:用概率的方法判断问题和知识库里的FAQ哪个在概率上更接近。优点是效果好,缺点是对语言模型的参数优化很敏感,要做很多的平滑实验,如Query词没有在FAQ中出现,如何处理
c. 基于向量的方法:把问题和FAQ都投射到向量空间中,根据向量空间中的距离计算问题和FAQ的相似性。 计算向量空间中的距离,提出了WMD算法,即两个句子之间先按照词距离将词一一匹配(如“奥巴马”匹配“总统”),然后加总得到句子间的相似性。优点是效果比计算所有词之间的距离均值效果好,缺点是计算量大,需要计算两两词汇之间的距离。
3)答案匹配:对准确率要求很高,只能返回一个回答
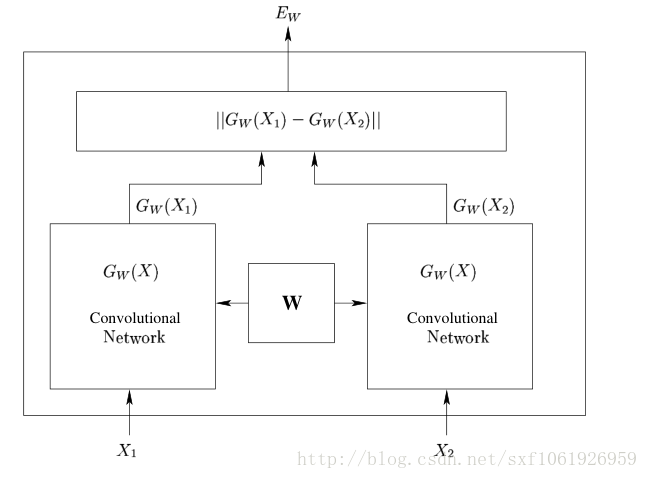
a. Siamese网络:两个网络共享相同的权重w,模型输入为两个句子,输出为两组句子是 匹配or不匹配。训练该模型,对于输入的query和召回的FAQ,能输出query与各回答的相似性,返回top1的结果。(参考:https://blog.csdn.net/sxf1061926959/article/details/54836696)
b. 基于交互矩阵(interaction-base network)的网络:(以下为原文)左边是刚才提到的结构,右边加入了交互。左边非常简单,Question 和 Answer 进入以后得到了表达的矩阵,然后再得到向量,最后求出得分,这是非常直观的流程。在 Attentive Pooling 网络里,会把交互放在求向量之前,想要在交互矩阵中得到行的取值和列的取值,就要得到它们重新的表达,再用最后的表达求扩散的分数。对于长文档,特别是如果 FAQ 很长,基于交互矩阵的网络会带来更多信息
5. 相近领域——机器阅读理解:
1)完型填空:从文章中挖去几个词,模型填空
2)多项选择:根据文章提出问题,有N个选项,模型选择最合适的一个选项回答
3)答案匹配:给定一个问题,从原文中找到句子回答
6. 演讲者心得:
1)尽快建立baseline,通过baseline理解数据和问题
2)尽快打通pipeline,从数据处理、模型训练到模型预测、模型评价。打通流程才能对模型进行评价,才能提升模型
3)没有免费午餐,没有解决一切问题的算法,只有领域适用的算法
4)领域相关数据,包括领域问答数据集、专家知识、领域词表等,这些对于优化模型的效果明显