一,Strom的特点
1,架构:
1.1,Nimbus
1.2,Supervisor
1.3,Worker
2.2,编程模型:
2.1,DAG
2.2,Spout
2.3,Bolt
3,数据传输:
3.1,Zmq
Zmq也是开源的消息传递的框架,虽然叫mq,但它并不是一个message queue,而是一个封装的比较好的
3.2,Netty
netty是NIO的网络框架,效率比较高。之所以有netty是storm在apache之后呢,zmq的license和storm的license不兼容的,bolt处理完消息后会告诉Spout
4,高可用性:
4.1,异常处理
4.2,消息可靠性保证机制
5,可维护性:Storm有个UI可以看跑在上面的程序监控
二,Strom实时低延迟,主要有两个原因
1,Strom进程是常驻内存的,不像Hadoop里面是不断的启停的,就没有不断启停的开销。
2,Strom的数据是不经过磁盘的,都是在内存里面,处理完就没有了,处理完就没有了,数据的交换经过网络,这样就避免磁盘IO的开销,所以Strom可以很低的延迟。
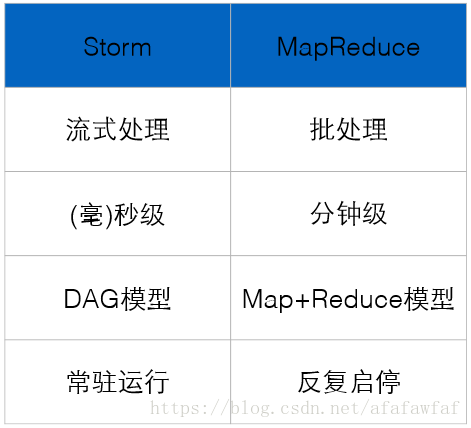
三,Strom和Hadoop的区别
1,数据来源:Hadoop是HDFS上某个文件夹下的可能是成TB的数据,Strom是实时新增的某一笔数据
2,处理过程:Hadoop是分MAP阶段到REDUCE阶段,Strom是由用户定义处理流程,流程中可以包含多个步骤,每个步骤可以是数据源(SPOUT)或处理逻辑(BOLT)
3,是否结束:Hadoop最后是要结束的,Strom是没有结束状态,到最后一步时,就停在那,直到有新数据进入时再从头开始
4,处理速度:Hadoop是以处理HDFS上大量数据为目的,速度慢,Strom是只要处理新增的某一笔数据即可以做到很快
5,适用场景:Hadoop是在要处理一批数据时用的,不讲究时效性,要处理就提交一个JOB,Strom是要处理某一新增数据时用的,要讲时效性
6,与MQ对比:Hadoop没有对比性,Strom可以看作是有N个步骤,每个步骤处理完就向下一个MQ发送消息,监听这个MQ的消费者继续处理

Storm:进程、线程常驻运行,数据不进入磁盘,网络传递。
MapReduce:TB、PB级别数据设计的,一次的批处理作业。
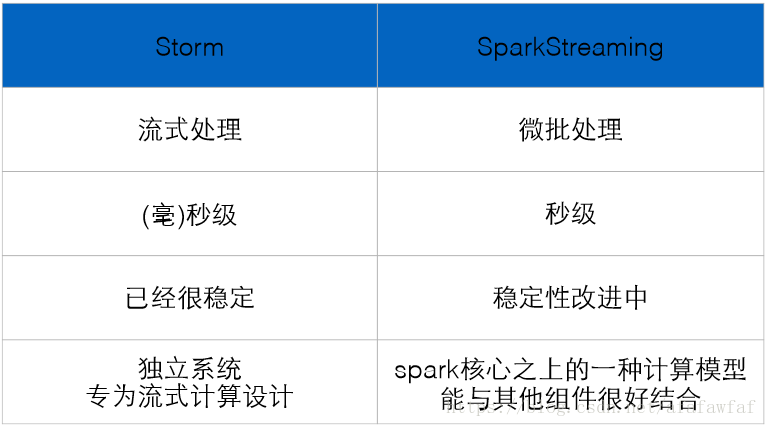
四,Storm与Spark Streaming的区别
1,Storm:纯流式处理,处理数据单元是一个个Tuple。另外Storm专门为流式处理设计,它的数据传输模式更为简单,很多地方也更为高效。并不是不能做批处理,它也可以来做微批处理,来提高吞吐
2,Spark Streaming:微批处理,一个批处理怎么做流式处理呢,它基于内存和DAG可以把处理任务做的很快,把RDD做的很小来用小的批处理来接近流式处理