Scala进阶之路-Spark本地模式搭建
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.Spark简介
二.部署Spark本地模式
1>.下载Spark软件
官网下载地址:http://spark.apache.org/downloads.html
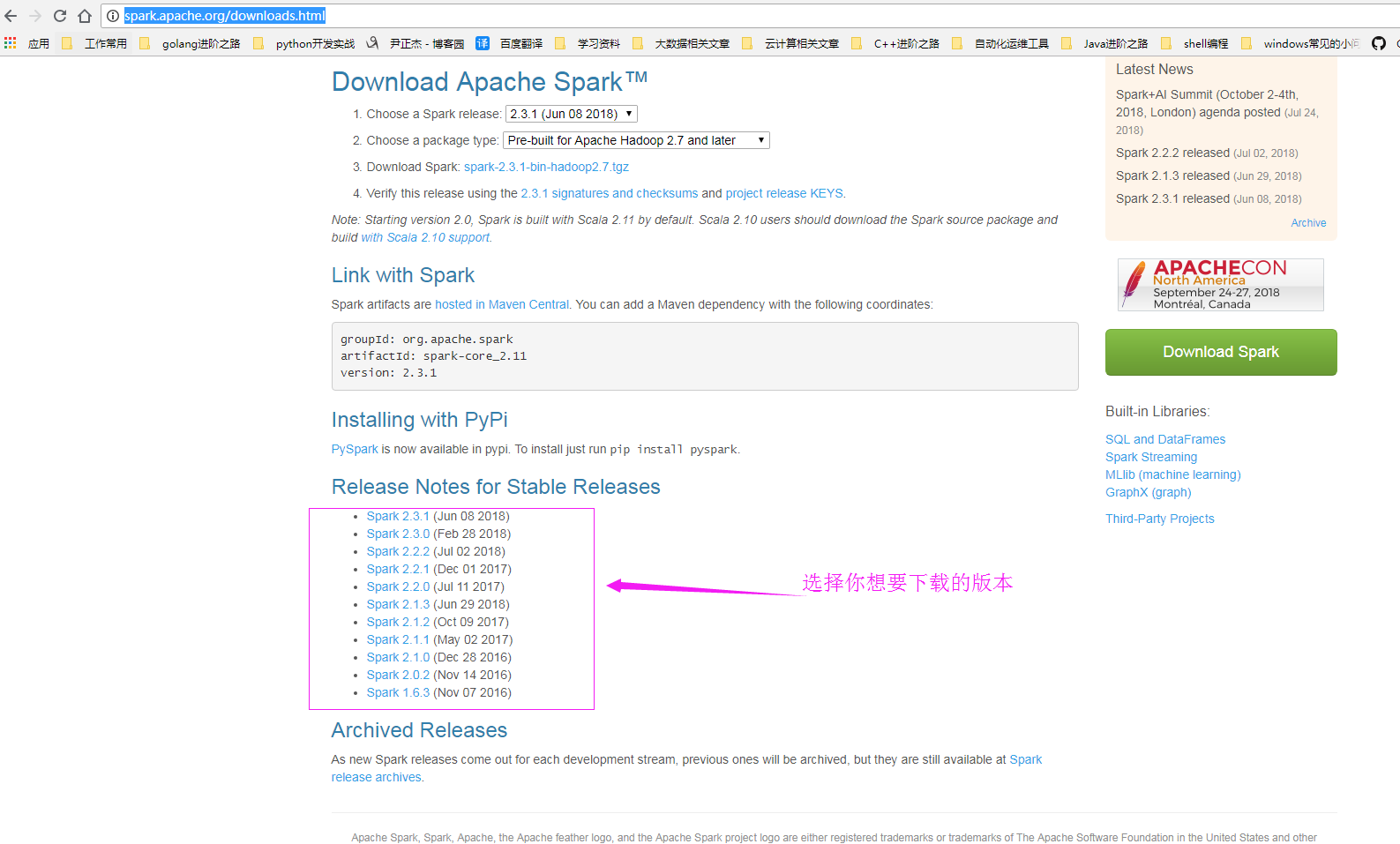
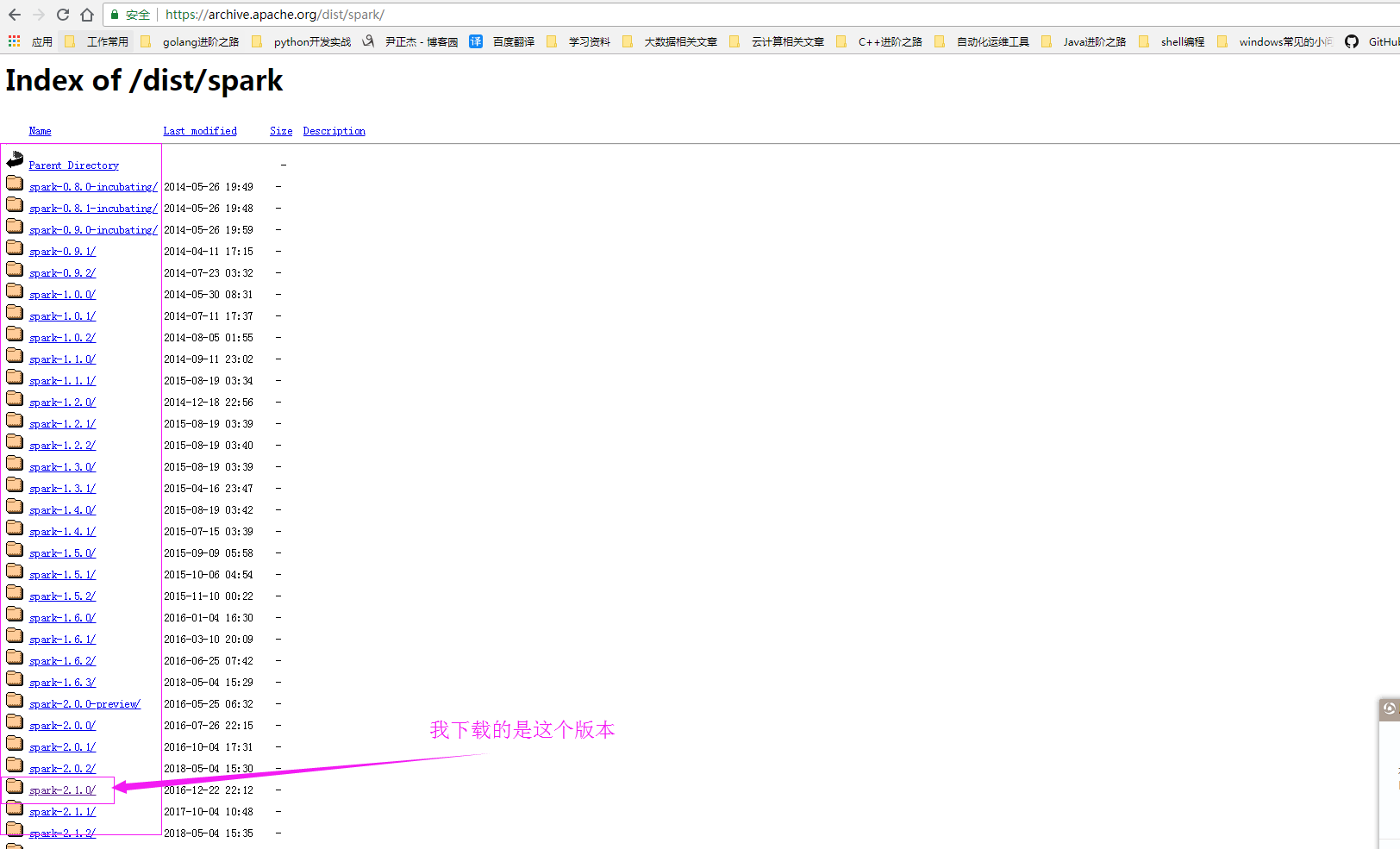
当然点上面的网页只是对该版本的支持,允许我调戏你一下,哈哈,实际上下载位置应该在这里:https://archive.apache.org/dist/spark/ 。
2>.解压下载的Spark并创建软连接
[yinzhengjie@s101 download]$ wget https://archive.apache.org/dist/spark/spark-2.1.0/spark-2.1.0-bin-hadoop2.7.tgz [yinzhengjie@s101 download]$ ll total 191052 -rw-r--r-- 1 yinzhengjie yinzhengjie 195636829 Jan 18 2017 spark-2.1.0-bin-hadoop2.7.tgz [yinzhengjie@s101 download]$ [yinzhengjie@s101 download]$ tar -zxf spark-2.1.0-bin-hadoop2.7.tgz -C /soft/ [yinzhengjie@s101 download]$ [yinzhengjie@s101 download]$ ln -s /soft/spark-2.1.0-bin-hadoop2.7/ /soft/spark [yinzhengjie@s101 download]$ [yinzhengjie@s101 download]$ ll /soft/ | grep spark lrwxrwxrwx 1 yinzhengjie yinzhengjie 32 Jul 26 20:44 spark -> /soft/spark-2.1.0-bin-hadoop2.7/ drwxr-xr-x 12 yinzhengjie yinzhengjie 4096 Dec 15 2016 spark-2.1.0-bin-hadoop2.7 [yinzhengjie@s101 download]$
3>.配置环境变量并使环境变量生效
[yinzhengjie@s101 download]$ tail -3 /etc/profile #ADD spark Path export SPARK_HOME=/soft/spark PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin [yinzhengjie@s101 download]$ [yinzhengjie@s101 download]$ source /etc/profile [yinzhengjie@s101 download]$
4>.启动Spark

5>.查看WebUI界面

三.Spark初体验-使用Spark实现单词统计
1>.创建测试文件
[yinzhengjie@s101 download]$ cat /home/yinzhengjie/1.txt hello world yinzhengjie hello word hello scala hello java hello python hello shell hello yinzhengjie hello golang [yinzhengjie@s101 download]$
2>.实现单词统计
体验Spark ---------------------- 1.登录spark spark-shell 2.编写scala代码 //1.加载文本 val rdd1 = sc.textFile("/home/yinzhengjie/1.txt") //2.压扁 val rdd2 = rdd1.flatMap(line=>{line.split(" ")}) //3.变换,标1成对 val rdd3 = rdd2.map(word=>{(word , 1)}) //4.按照key进行化简 val rdd4 = rdd3.reduceByKey((a,b)=> a + b).sortBy(t=> -t._2 ) //5.输出结果 rdd4.collect() 3.一行完成 sc.textFile("/home/yinzhengjie/1.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(t=> -t._2 ).collect()
