最近在看《tensorflow实战》中关于RNN一节,里面关于word2vec中涉及到了哈夫曼树,因此在查看了很多博客(文末)介绍后,按自己的理解对概念进行了整理(拼凑了下TXT..),最后自己用python实现Haffuman树的构建及编码。
哈夫曼(huffman)树
基本概念
- 路径和路径长度:树中一个结点到另一个结点之间的分支构成这两个结点之间的路径;路径上的分枝数目称作路径长度,它等于路径上的结点数减1.
- 结点的权和带权路径长度:在许多应用中,常常将树中的结点赋予一个有着某种意义的实数,我们称此实数为该结点的权;结点的带权路径长度规定为从树根结点到该结点之间的路径长度与该结点上权的乘积.
- 树的带权路径长度:为树中所有叶子结点的带权路径长度之和,公式为:
其中,n表示叶子结点的数目,
之间的路径长度。
如下图中树的带权路径长度 WPL = 9 x 2 + 12 x 2 + 15 x 2 + 6 x 3 + 3 x 4 + 5 x 4 = 122
- 哈夫曼树:哈夫曼树又称最优二叉树。它是 n 个带权叶子结点构成的所有二叉树中,带权路径长度 WPL 最小的二叉树。如下图为一哈夫曼树示意图。
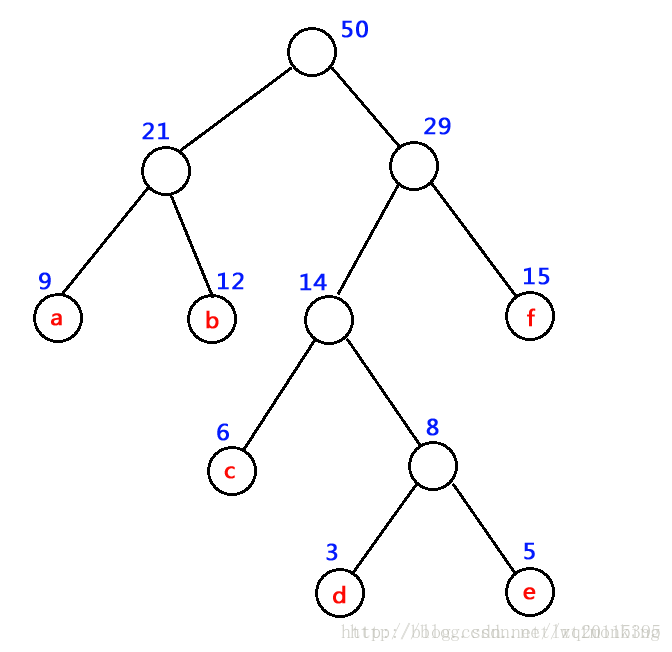
构建哈夫曼树
假设有n个权值,则构造出的哈夫曼树有n个叶子结点。 n个权值分别设为 w1、w2、…、wn,则哈夫曼树的构造规则为:
- 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);
- 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;
- 从森林中删除选取的两棵树,并将新树加入森林;
- 重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
如:对 下图中的六个带权叶子结点来构造一棵哈夫曼树,步骤如下:
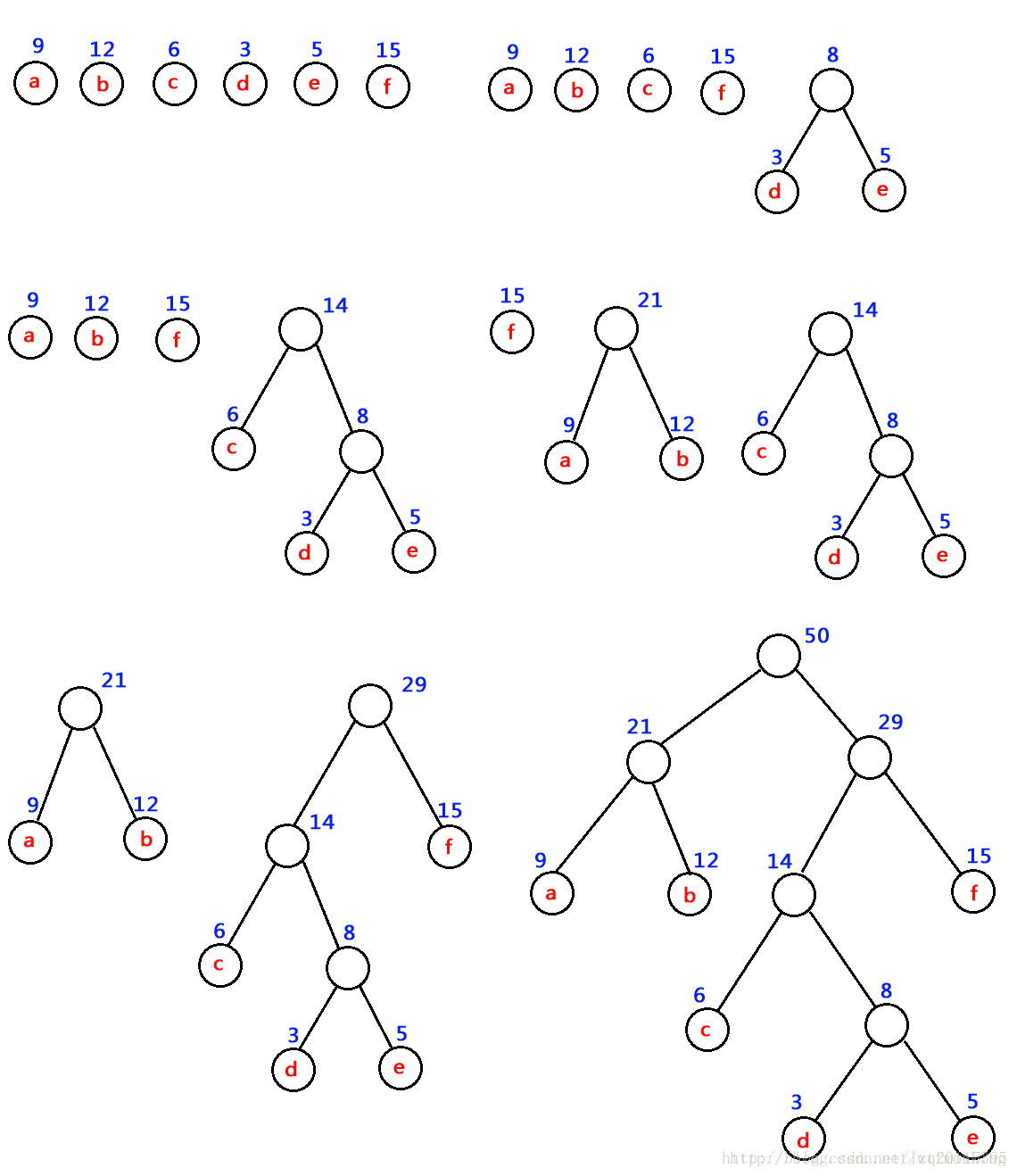
注意:
- 为了使得到的哈夫曼树的结构尽量唯一,通常规定生成的哈夫曼树中每个结点的左子树根结点的权小于等于右子树根结点的权。
如果还是不清楚过程,可以参考
https://jingyan.baidu.com/article/a501d80c16dfa0ec620f5e70.html,过程介绍的更清晰。哈夫曼编码
等长编码:这种编码方式的特点是每个字符的编码长度相同(编码长度就是每个编码所含的二进制位数)。假设字符集只含有4个字符A,B,C,D,用二进制两位表示的编码分别为00,01,10,11。若现在有一段电文为:ABACCDA,则应发送二进制序列:00010010101100,总长度为14位。当接收方接收到这段电文后,将按两位一段进行译码。这种编码的特点是译码简单且具有唯一性,但编码长度并不是最短的。
- 不等长编码:在传送电文时,为了使其二进制位数尽可能地少,可以将每个字符的编码设计为不等长的,使用频度较高的字符分配一个相对比较短的编码,使用频度较低的字符分配一个比较长的编码。例如,可以为A,B,C,D四个字符分别分配0,00,1,01,并可将上述电文用二进制序列:000011010发送,其长度只有9个二进制位,但随之带来了一个问题,接收方接到这段电文后无法进行译码,因为无法断定前面4个0是4个A,1个B、2个A,还是2个B,即译码不唯一,因此这种编码方法不可使用。
因此,为了设计长短不等的编码,以便减少电文的总长,还必须考虑编码的唯一性,即在建立不等长编码时必须使任何一个字符的编码都不是另一个字符的前缀,这宗编码称为前缀编码(prefix code)。
1. 利用字符集中每个字符的使用频率作为权值构造一个哈夫曼树;
2. 从根结点开始,为到每个叶子结点路径上的左分支赋予0,右分支赋予1,并从根到叶子方向形成该叶子结点的编码.
假设一个文本文件TFile中只包含7个字符{a,b,c,d,e,f},这7个字符在文本中出现的次数为{9,12,6,3,5,15}
通过哈夫曼树来构造的编码称为哈弗曼编码(huffman code)
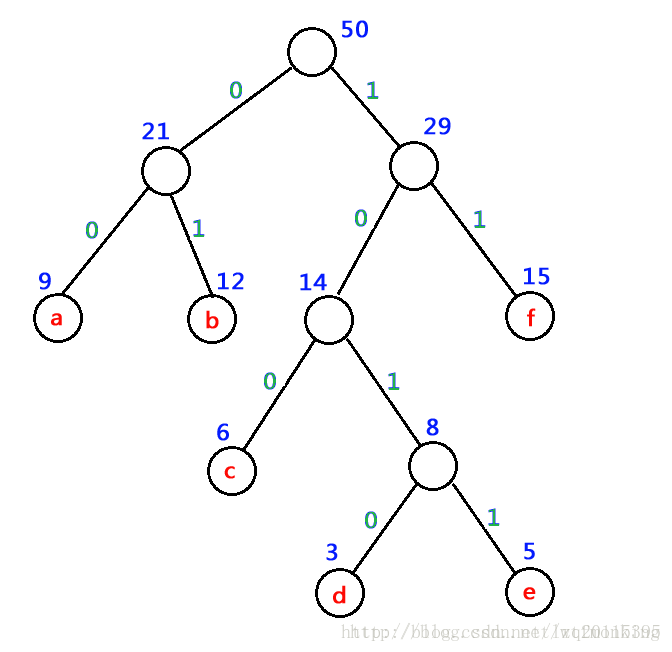
a 的编码为:00
b 的编码为:01
c 的编码为:100
d 的编码为:1010
e 的编码为:1011
f 的编码为:11
Python实现
- 若带编码字符的个数,即树中叶结点的最大个数为n时,哈夫曼树的总节点数为2n-1
#节点类
class Node(object):
def __init__(self,name=None,value=None):
self._name=name
self._value=value
self._left=None
self._right=None
#哈夫曼树类
class HuffmanTree(object):
#根据Huffman树的思想:以叶子节点为基础,反向建立Huffman树
def __init__(self,char_weights):
self.a=[Node(part[0],part[1]) for part in char_weights] #根据输入的字符及其频数生成叶子节点
while len(self.a)!=1:
self.a.sort(key=lambda node:node._value,reverse=True)
c=Node(value=(self.a[-1]._value+self.a[-2]._value))
c._left=self.a.pop(-1)
c._right=self.a.pop(-1)
self.a.append(c)
self.root=self.a[0]
self.b=range(10) #self.b用于保存每个叶子节点的Haffuman编码,range的值只需要不小于树的深度就行
#用递归的思想生成编码
def pre(self,tree,length):
node=tree
if (not node):
return
elif node._name:
print node._name + '的编码为:',
for i in range(length):
print self.b[i],
print '\n'
return
self.b[length]=0
self.pre(node._left,length+1)
self.b[length]=1
self.pre(node._right,length+1)
#生成哈夫曼编码
def get_code(self):
self.pre(self.root,0)
if __name__=='__main__':
#输入的是字符及其频数
char_weights=[('a',5),('b',4),('c',10),('d',8),('f',15),('g',2)]
tree=HuffmanTree(char_weights)
tree.get_code()运行结果为:

参考
http://blog.csdn.net/wtfmonking/article/details/17150499#
http://blog.csdn.net/shuangde800/article/details/7341289