最近快过五一了,对于部分人来说可定是旅游出去吃吃喝喝咯,那就来个爬取美食的吧,主要还是半个多月没写与工作无关的代码了,快生疏了,再不写写估计又还回去了
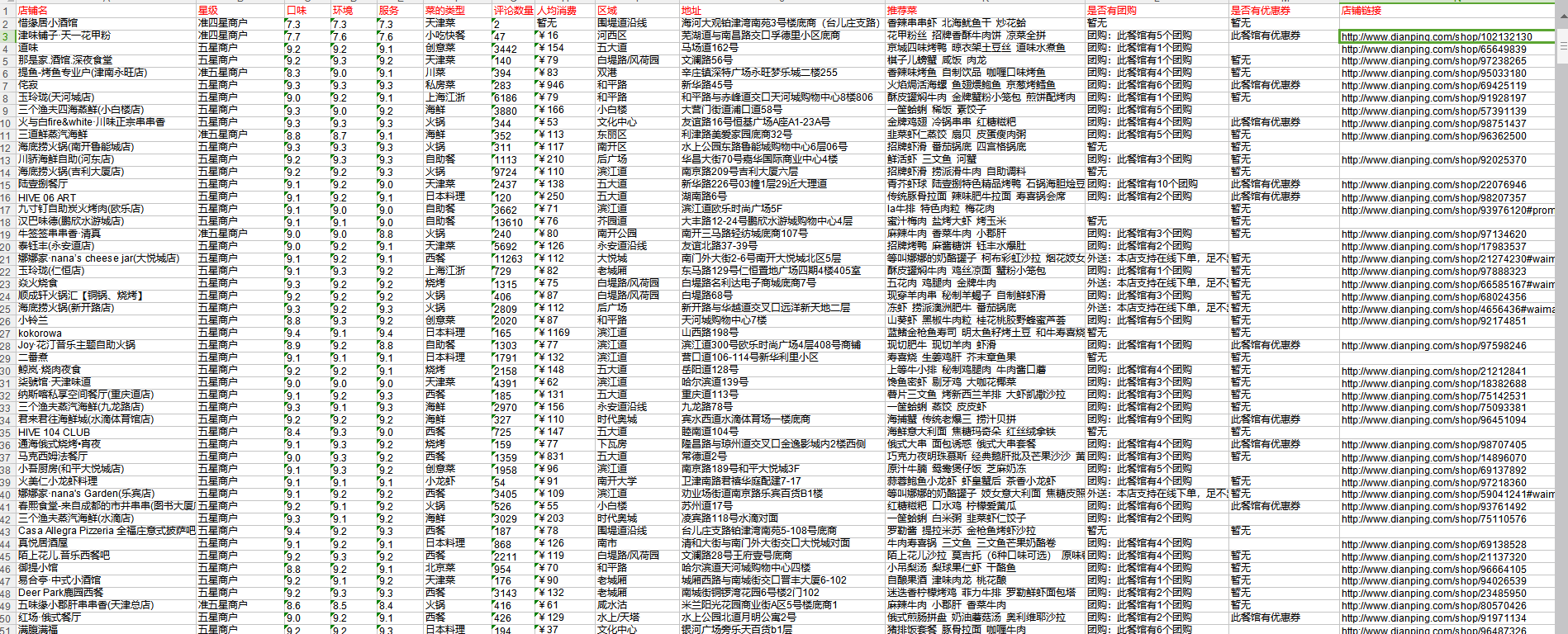
效果图
总共十四列数据,包括环境、人均消费等等
接下来就得开始敲代码了,使用Scrapy+Selenium方式爬取,每次爬取先打开网页,爬取完后发送信号关闭网页,为什么用网页呢,因为笔者刚开始直接用Scrapy方式爬取,设置好了IP代理池和User_Agent代理池,发现还是有404情况,也就是可能会有目标计算机积极拒绝等警告吧,然后最好的方式当然就用网页模拟咯,可以在爬虫类中设置custom_settings,里面可以写一些Cookies,当然偷个懒的话,直接网页模拟,什么都解决了
看了我上篇Scrapy总结的话就知道,User_Agent代理直接用fake_useragent,代理的话,免费的话就直接爬取西刺等高匿名ip代理,然后验证一下,通过就设置,不通过直接在process_response中重新设置一下,见代码中的RandomProxyMiddlesare中间件
在过程中,笔者使用了scrapy.loader下的ItemLoader和scrapy.loader.processors下的TakeFirst取第一个元素,因为使用ItemLoader的话,item_loader = PublicspiderItem(item=PubliccommentItem(), response=response),最后爬取的有些数据是None,从ItemLoader的源码可以看出,内部进行了判断,如果是None,将没有设置的字段的Key值,会报错,没办法,然后就取消了ItemLoader的使用。
还需要注意的是,Selenium打开的浏览器,需要在爬虫结束时后关闭,因此就需要用到信号链了,需要使用到scrapy下的signals和scrapy.xlib.pydispatch下的dispatcher,如dispatcher.connect(self.spider_closed, signals.spider_closed),运行中会提示使用其他方法替代,这是因为高版本换了方法
使用fake_useragnet设置代理池如下
class CustomUserAgentMiddleware(object): def __init__(self, crawler): super().__init__() self.ua = UserAgent() self.ua_type = crawler.settings.get("RANDOM_UA_TYPE", "random") @classmethod def from_crawler(cls, crawler): return cls(crawler) def process_request(self, request, spider): def get_ua(): return getattr(self.ua, self.ua_type) request.headers.setdefault("User_Agent", get_ua())
集成browser到scrapy
class SeleniumScrapyMiddleware(object): def process_request(self, request, spider): if spider.name == "dazong": import time spider.browser.get(request.url) time.sleep(2) return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source, encoding="utf-8", request=request)其中setting.py中的设置
DOWNLOADER_MIDDLEWARES = { 'PublicComment.middlewares.CustomUserAgentMiddleware': 542, 'PublicComment.middlewares.SeleniumScrapyMiddleware': 112, # 'PublicComment.middlewares.RandomProxyMiddlesare': 125, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': None, 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None }最后爬虫类代码为
# -*- coding: utf-8 -*- import scrapy from PublicComment.items import PublicspiderItem, PubliccommentItem from selenium import webdriver from scrapy import signals from scrapy.xlib.pydispatch import dispatcher class DazongSpider(scrapy.Spider): name = 'dazong' allowed_domains = ['dianping.com'] start_urls = ["http://www.dianping.com/tianjin/ch10"] for i in range(2, 51): start_urls.append("http://www.dianping.com/tianjin/ch10/p{}".format(i)) def __init__(self): # self.browser = webdriver.PhantomJS(executable_path="D://Program Files//Phantomjs//phantomjs-2.1.1-windows//bin\phantomjs.exe") # executable_path="" self.browser = webdriver.Firefox() super().__init__() dispatcher.connect(self.spider_closed, signals.spider_closed) self.browser.get("http://www.dianping.com/tianjin") import time time.sleep(2) self.browser.find_element_by_css_selector( "#cata-hot > div.cata-hot-detail.cata-hot-info > div > a").click() self.browser.find_element_by_css_selector("#logo-input > div > a.city.J-city > i").click() time.sleep(10) def spider_closed(self): self.browser.quit() self.browser.close() def parse(self, response): print(response.text) lis = response.css("#shop-all-list ul li") # print(len(lis)) for node in lis: name = node.css("div.tit a h4::text").extract_first() start = node.css("div.comment > span::attr(title)").extract_first() taste = node.css("div.txt span.comment-list span:nth-child(1) b::text").extract_first() environment = node.css("div.txt span.comment-list span:nth-child(2) b::text").extract_first() service = node.css("div.txt span.comment-list span:nth-child(3) b::text").extract_first() tag = node.css("div.tag-addr a:nth-child(1) span::text").extract_first() comments = node.css("div.comment a.review-num > b::text").extract_first() price = node.css("div.comment a.mean-price > b::text").extract_first() area = node.css("div.tag-addr a:nth-child(3) span::text").extract_first() address = node.css("div.tag-addr > span::text").extract_first() recommend_food = node.css("div.recommend a::text").extract() has_bulk = node.css("div.svr-info a:nth-child(1)::attr(title)").extract_first() preferential = node.css("div.svr-info a.tuan.privilege::text").extract_first() link = node.css("div.tit > div a:nth-child(1)::attr(href)").extract_first() item = PubliccommentItem() item['name'] = name if name is not None else "" item['start'] = start if start is not None else "" item['taste'] = taste if taste is not None else "" item['environment'] = environment if environment is not None else "" item['service'] = service if service is not None else "" item['tag'] = tag if tag is not None else "" item['comments'] = comments if comments is not None else "" item['price'] = price if price is not None else "暂无" item['area'] = area if area is not None else "" item['address'] = address if address is not None else "" item['recommend_food'] = " ".join(recommend_food) if recommend_food is not None else "暂无" item['has_bulk'] = has_bulk if has_bulk is not None else "暂无" item['preferential'] = preferential if preferential is not None else "暂无" item['link'] = link if link is not None else "" yield item
最后是代码地址:传送门