-首先打个标记等我把要抓的数据抓完之后再一 一 分享,先上几个截图。
1.已抓取到按条件的数据。这是躺过一周的坑,得到的结果
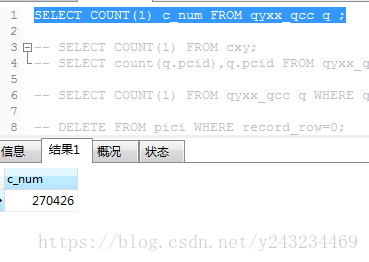
2.根据某些条件可能会得到重复的数据,例如:销售关键字与贸易关键字可能会得到一些重复的数据,则不存数据库。
=========== 等老弟我把数据爬完就跟大家一一分享代码,以及我爬数据时候遇到的关键坑。
现在分享主要怕查查大哥发现,把这种途径封掉,就麻烦了!
-------------------- 2018-03-30 日志 --------------------
/**
* 数据清理by 企业 name
* 梳理:
* 已开始用url+id作为详细信息查询,发现没过不了20条就要输入验证码,说明这一块控制的比较严格
* 然后过了一天之后发现直接使用名字查询即使是时间很短0.8-1 s 也没被拦截
* 半小时后发现使用名字查询也出现需要验证码的情况,立马改用天眼查进行查询,刚开始用名字查询也没有问题,以为这样就大功告成坐等收货了
* 过了一会发现出现了跟企查查一样的效果,现在在出现需要验证码后,重新请求一下首页,另外在进行正常操作发现不需要输入验证码也可以。
* 然后继续干我其他的事情并断点观察着;
* 实践证明天眼查也管的很严格了,现在准备试一下m.tianyancha.com;等待效果
* 2018年3月30日 15:42:00:又挂彩了,继续还一种方式,将cookie修改后,将查询间隔时间变大到4秒一次查询
* 2018-3-30 16:14:57 :事实证明,我被天眼查封ip了。告一段落回到企查查吧!
*/