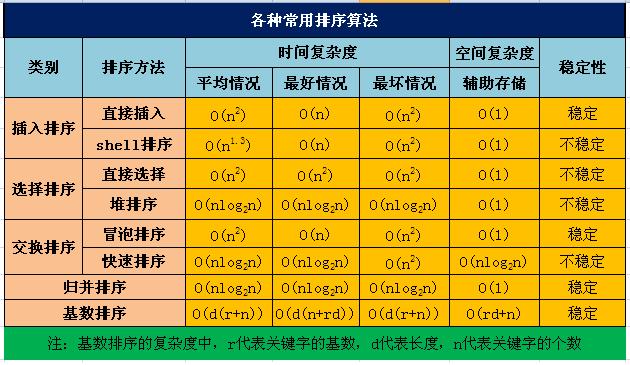
八大常用排序算法详细分析 包括复杂度,原理和实现如下:
本文转载自https://blog.csdn.net/yuxin6866/article/details/52771739
1. 冒泡排序
1.1 算法原理:
S1:从待排序序列的起始位置开始,从前往后依次比较各个位置和其后一位置的大小并执行S2。
S2:如果当前位置的值大于其后一位置的值,就把他俩的值交换(完成一次全序列比较后,序列最后位置的值即此序列最大值,所以其不需要再参与冒泡)。
S3:将序列的最后位置从待排序序列中移除。若移除后的待排序序列不为空则继续执行S1,否则冒泡结束。
1.2 算法实现(Java):
1.2.1 基础实现:
public static void bubbleSort(int[] array) {
int len = array.length;
for (int i = 0; i < len; i++) {
for (int j = 0; j < len - i - 1; j++) {
if (array[j] > array[j + 1]) {
int temp = array[j + 1];
array[j + 1] = array[j];
array[j] = temp;
}
}
}
}
1.2.2 算法优化:
若某一趟排序中未进行一次交换,则排序结束
public static void bubbleSort(int[] array) {
int len = array.length;
boolean flag = true;
while (flag) {
flag = false;
for (int i = 0; i < len - 1; i++) {
if (array[i] > array[i + 1]) {
int temp = array[i + 1];
array[i + 1] = array[j];
array[i] = temp;
flag = true;
}
}
len--;
}
}2. 快速排序
2.1 算法原理:
快速排序是对冒泡排序的一种改进。基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此实现整个数据变成有序序列。
2.2 算法实现(Java):
public static void quickSort(int[] array, int left, int right) {
if (left < right) {
int pivot = array[left];
int low = left;
int high = right;
while (low < high) {
while (low < high && array[high] >= pivot) {
high--;
}
array[low] = array[high];
while (low < high && array[low] <= pivot) {
low++;
}
array[high] = array[low];
}
array[low] = pivot;
quickSort(array, left, low - 1);
quickSort(array, low + 1, right);
}
}
3. 直接插入排序
3.1 算法原理:
插入排序的基本方法是:每步将一个待排序序列按数据大小插到前面已经排序的序列中的适当位置,直到全部数据插入完毕为止。
假设有一组无序序列 , , … , :
(1) 将这个序列的第一个元素R0视为一个有序序列;
(2) 依次把 , , … , 插入到这个有序序列中;
(3) 将插入到有序序列中时,前 i-1 个数是有序的,将和 ~ 从后往前进行比较,确定要插入的位置。
3.2 算法实现(Java):
public static void insertSort(int[] array) {
for (int i = 1, len = array.length; i < len; i++) {
if (array[i] < array[i - 1]) {
int temp = array[i];
int j;
for (j = i - 1; j >= 0 && temp < array[j]; j--) {
array[j + 1] = array[j];
}
array[j + 1] = temp;
}
}
}
4. Shell排序
4.1 算法原理:
希尔排序是一种插入排序算法,又称作缩小增量排序。是对直接插入排序算法的改进。其基本思想是:
先取一个小于n的整数作为第一个增量,把全部数据分成个组。所有距离为的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量重复上述的分组和排序,直至所取的增量,即所有记录放在同一组中进行直接插入排序为止。该方法实质上是一种分组插入方法。
4.2 算法实现(Java):
public static void shellSort(int[] array) {
int n = array.length;
int h;
for (h = n / 2; h > 0; h /= 2) {
for (int i = h; i < n; i++) {
for (int j = i - h; j >= 0; j -= h) {
if (array[j] > array[j + h]) {
int temp = array[j];
array[j] = array[j + h];
array[j + h] = temp;
}
}
}
}
}
5. 直接选择排序
5.1 算法原理:
直接选择排序是一种简单的排序方法,它的基本思想是:
第一次从R[0]~R[n-1]中选取最小值,与R[0]交换,
第二次从R[1]~R[n-1]中选取最小值,与R[1]交换,
….,
第i次从R[i-1]~R[n-1]中选取最小值,与R[i-1]交换,
…..,
第n-1次从R[n-2]~R[n-1]中选取最小值,与R[n-2]交换,
共通过n-1次,得到一个从小到大排列的有序序列。
5.2 算法实现(Java):
public static void selectSort(int[] array) {
int n = array.length;
for (int i = 0; i < n; i++) {
int minIndex = i;
for (int j = i + 1; j < n; j++) {
if (array[minIndex] > array[j]) {
minIndex = j;
}
}
if (i != minIndex) {
int temp = array[i];
array[i] = array[minIndex];
array[minIndex] = temp;
}
}
}
6. 堆排序
6.1 算法原理:
6.1.1 二叉堆定义:
二叉堆是完全二叉树或近似完全二叉树。二叉堆满足两个特性:
1)父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2)每个结点的左子树和右子树都是一个二叉堆。
当父结点的键值总是大于或等于任何一个子节点的键值时为大根堆。当父结点的键值总是小于或等于任何一个子节点的键值时为小根堆。下面展示一个小根堆: 
由于其它几种堆(二项式堆,斐波纳契堆等)用的较少,一般将二叉堆就简称为堆。
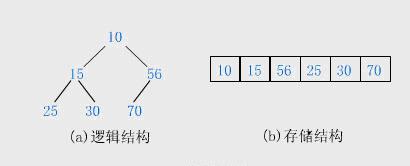
6.1.2 堆的存储:
一般都用数组来表示堆,i结点的父结点下标就为(i – 1) / 2。它的左右子结点下标分别为2 * i + 1和2 * i + 2。如第0个结点左右子结点下标分别为1和2。
6.1.3 堆的插入:
每次插入都是将新数据放在数组最后。可以发现从这个新数据的父结点到根结点必然为一个有序的数列,然后将这个新数据插入到这个有序数据中。
6.1.4 堆排序:
堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即A[PARENT[i]] >= A[i],小根堆则相反。
堆排序利用了大根堆(或小根堆)堆顶记录的关键字最大(或最小)这一特征,使得在当前无序区中选取最大(或最小)关键字的记录变得简单。
(1)用大根堆排序的基本思想
① 先将初始数组建成一个大根堆,此堆为初始的无序区
② 再将最大的元素(即堆顶)和无序区的最后一个记录交换,由此得到新的无序区和有序区,且满足的值<=的值。
③由于交换后新的根可能违反堆性质,故应将当前无序区调整为堆。然后再次将中最大的元素和该区间的最后一个记录交换,由此得到新的无序区和有序区,且仍满足关系的值<=的值,同样要将调整为堆。
……
直到无序区只有一个元素为止。
(2)大根堆排序算法的基本操作:
①建堆,建堆是不断调整堆的过程,从len/2处开始调整,一直到第一个节点,此处len是堆中元素的个数。建堆的过程是线性的过程,从len/2到0处一直调用调整堆的过程,相当于o(h1)+o(h2)…+o(hlen/2) 其中h表示节点的深度,len/2表示节点的个数,这是一个求和的过程,结果是线性的O(n)。
②调整堆:调整堆在构建堆的过程中会用到,而且在堆排序过程中也会用到。利用的思想是比较节点i和它的孩子节点left(i),right(i),选出三者最大(或者最小)者,如果最大(小)值不是节点i而是它的一个孩子节点,那边交互节点i和该节点,然后再调用调整堆过程,这是一个递归的过程。调整堆的过程时间复杂度与堆的深度有关系,是lgn的操作,因为是沿着深度方向进行调整的。
③堆排序:堆排序是利用上面的两个过程来进行的。首先是根据元素构建堆。然后将堆的根节点取出(一般是与最后一个节点进行交换),将前面len-1个节点继续进行堆调整的过程,然后再将根节点取出,这样一直到所有节点都取出。
6.2 算法实现(Java):
public static void heapSort(int[] array) {
// 1. 创建最大堆:从最后一个节点的父节点开始
int lastIndex = array.length - 1;
int startIndex = (lastIndex - 1) / 2;
for (int i = startIndex; i >= 0; i--) {
maxHeap(sort, sort.length, i);
}
// 2. 排序:末尾与头交换,逐一找出最大值,最终形成一个递增的有序序列
for (int i = array.length - 1; i > 0; i--) {
int temp = array[0];
array[0] = array[i];
array[i] = temp;
maxHeap(array, i, 0);
}
}
private static void maxHeap(int[] data, int heapSize, int index) {
// 左子节点
int leftChild = 2 * index + 1;
// 右子节点
int rightChild = 2 * index + 2;
// 最大元素下标
int largestIndex = index;
// 分别比较当前节点和左右子节点,找出最大值
if (leftChild < heapSize && data[leftChild] > data[largestIndex]) {
largestIndex = leftChild;
}
if (rightChild < heapSize && data[rightChild] > data[largestIndex]) {
largestIndex = rightChild;
}
// 如果最大值是子节点,则进行交换
if (largestIndex != index) {
int temp = data[index];
data[index] = data[largestIndex];
data[largestIndex] = temp;
// 交换后,其子节点可能就不是最大堆了,需要对交换的子节点重新调整
maxHeap(data, heapSize, largestIndex);
}
}
7. 归并排序
7.1 算法原理:
归并排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并过程为:
比较a[i]和a[j]的大小,若a[i]≤a[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1;否则将第二个有序表中的元素a[j]复制到r[k]中,并令j和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到r中从下标k到下标t的单元。
归并排序的算法我们通常用递归实现,先把待排序区间[s,t]以中点二分,接着把左边子区间排序,再把右边子区间排序,最后把左区间和右区间用一次归并操作合并成有序的区间[s,t]。
归并操作的工作原理如下:
S1: 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
S2: 设定两个指针,最初位置分别为两个已经排序序列的起始位置
S3: 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
S4: 重复S3,直到某一指针超出序列尾
S5: 将另一序列剩下的所有元素直接复制到合并序列尾
7.2 算法实现(Java):
public static void mergeSort(int[] array, int low, int high) {
int middle = (low + high) / 2;
if (low < high) {
mergeSort(array, low, middle);
mergeSort(array, middle + 1, high);
merge(array, low, middle, high);
}
}
public static void merge(int[] array, int low, int middle, int high) {
int[] temp = new int[high - low + 1];
int i = low;
int j = middle + 1;
int k = 0;
while (i <= middle && j <= high) {
if (array[i] < array[j]) {
temp[k++] = array[i++];
} else {
temp[k++] = array[j++];
}
}
while (i <= middle) {
temp[k++] = array[i++];
}
while (j <= high) {
temp[k++] = array[j++];
}
for (int m = 0; m < temp.length; m++) {
array[m + low] = temp[m];
}
}
8. 基数排序
8.1 算法原理:
基数排序的原理如下:将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序的方式有以下两种:
最高位优先(Most Significant Digit first)法,简称MSD法:先按排序分组,同一组中记录,关键码相等,再对各组按排序分成子组,之后,对后面的关键码继续这样的排序分组,直到按最次位关键码对各子组排序后。再将各组连接起来,便得到一个有序序列。
最低位优先(Least Significant Digit first)法,简称LSD法:先从开始排序,再对进行排序,依次重复,直到对排序后便得到一个有序序列。
8.2 算法实现(Java):
/**
* 基数排序(LSD)
*
* @param array 待排序数组
* @param d 表示最大的元素的位数
*/
public static void radixSort(int[] array, int d) {
int n = 1;
int times = 1; // 排序次数,由位数最多的元素决定
int[][] temp = new int[10][array.length]; //数组的第一维表示可能的余数0-9
int[] order = new int[10]; //数组order用来表示该位是i的元素个数
while (times <= d) {
for (int i = 0; i < array.length; i++) {
int lsd = ((array[i] / n) % 10);
temp[lsd][order[lsd]] = array[i];
order[lsd]++;
}
int k = 0;
for (int i = 0; i < 10; i++) {
if (order[i] != 0) {
for (int j = 0; j < order[i]; j++) {
array[k] = temp[i][j];
k++;
}
order[i] = 0;
}
}
n *= 10;
times++;
}
}