八大排序介绍
1、插入排序:直接插入排序、希尔排序。
2、选择排序:直接选择排序、堆排序。
3、交换排序:冒泡排序、快速排序。
4、归并排序。
5、基数排序。
直接插入排序
一、思路:我们先对前两个数进行排序,即先确定第二个数的位置,然后确定第三个数的位置,以此类推,直至全部排完。我们把这个数放入c中保存,然后依次拿前面的数和c比较,若比c大,则后移,直到达到0位置或者找到比c小的数,我们再把c插入空位即可。这里我们要注意一下t=0时的处理,及时退出循环,防止数组越界。
二、算法分析:
1、最好的情况:已经有序,复杂度O(n)
2、最坏的情况:顺序相反,复杂度O(n^2)
3、平均时间复杂度:O(n^2)
4、空间复杂度:O(1)
5、稳定性:稳定
三、算法实现:
/**
* 直接插入排序
* @param a
* @return
*/
public int[] sort1(int a[]){
for(int i=1;i<a.length;i++){
int c = a[i];
int t;
for( t = i-1 ;a[t]>c&&t>=0 ;t--){
a[t+1]=a[t];
if(t==0)
{
t--;
break;
}
}
a[t+1]=c;
for(int k=0;k<=i;k++)
System.out.println(a[k]);
System.out.println("\r\n");
}
return a;
}
四、算法优缺点:在一个数组接近顺序的前提下排序会很快,但在逆序下,所花的时间较多。
希尔排序
一、思路:我们在直接插入排序中可以发现,如果在逆序这类情况下,会花费程序很大的时间,而在接近顺序时,时间复杂度可以接近O(n),因此,我们在直接插入排序的基础上做了一些改进。我们把数据分组,设立一个gap,刚开始为1/2,之后逐渐减小为原来的1/2,最终为1,它的作用便是把数据分割,控制排序的组数,我们来看一下示意图,便可以理解了。
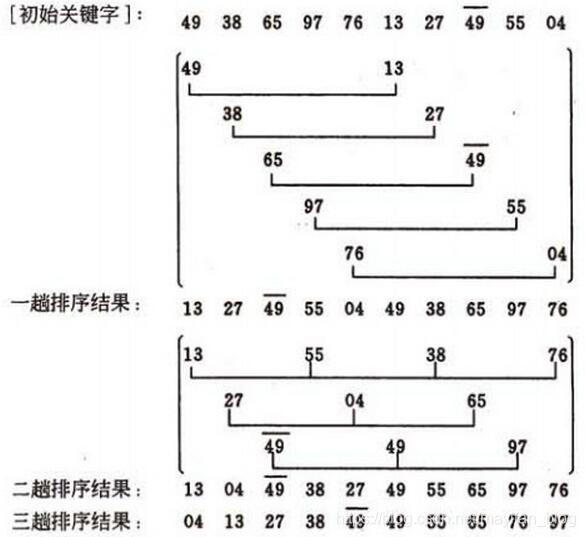
我们可以发现,最后一趟排序前数据已经基本上有序,我们可以得到一个总体上相对较少的时间完成排序,这避免了直接插入法的缺点。
二、算法分析:
1、最好的情况:O(nlog2 n)
2、最坏的情况:O(nlog2 n)
3、平均时间复杂度:O(nlog2 n)
4、空间复杂度:O(1)
5、稳定性:不稳定
三、算法实现:
/**
* 希尔排序
* @param a
* @return
*/
public int[] sort2(int a[]){
int gap;
for(gap = a.length/2; gap>=1; gap/=2)
{
for(int i=0;i<a.length;i++)
{
for(int k=i;k<=a.length-gap;k+=gap) //直接插入排序部分
{
int c=a[k];
int t;
for( t=k-gap;t>=0&&a[t]>c;t-=gap)
{
a[t+gap] = a[t];
if(t<gap)
{
t-=gap;
break;
}
}
a[t+gap]=c;
}
}
}
return a;
}
四、算法优缺点:相比直接插入排序,它的效率更高,避免了直接插入排序在乱序情况下的不足。但因为在不同的排序组内会有数的移动,因此希尔排序是不稳定的。
选择排序
一、思路:选择排序的思路很简单:第一次遍历整个数组找到最小的数,换到数组的第一个位置,然后从第二个数组开始寻找第二小的数,换到数组第二个位置,以此类推,全部排完。
二、算法分析:
1、最好的情况:O(n^2)
2、最坏的情况:O(n^2)
3、平均时间复杂度:O(n^2)
4、空间复杂度:O(1)
5、稳定性:不稳定(涉及到角标值的被后者覆盖问题)
三、算法实现:
/**
* 选择排序
* @param a
* @return
*/
public int[] sort3(int a[]){
for(int i=0;i<a.length-1;i++){
int c=i;
int min=a[i];
for(int j=i+1;j<a.length;j++){
if(a[j]<min){
c=j;
min=a[j];
}
}
int temp=a[i];
a[i]=a[c];
a[c]=temp;
}
return a;
}
四、算法优缺点:算法逻辑简单直观,但时间复杂度较高,算法不稳定。
堆排序
一、什么是堆:堆排序分为大根堆和小根堆两种形式,顾名思义,我们可以把它理解为一个堆(如果学过树的知识,我们可以把它理解为一个完全二叉树),大根堆就是堆顶的数为最大,在二叉树中我们可以定义双亲节点的值大于其子节点的值,从上往下以此类推;小根堆就是双亲节点小于其左右子节点。
二、堆排序的步骤:先建立一个初始堆,即按照数组的序号从上到下,从左到右,建立一个类似完全二叉树的结构,但节点之间没有指针关系,只是把数组摆成了堆的形式。接下来从下到上调整堆,分别拿双亲节点和子节点比较大小,如果双亲节点小于最大子节点,则交换位置,最后我们会得到一个初始的大根堆。接下来我们把堆顶元素(最大)和数组的最后一个元素交换位置,除此最后一个数外,我们继续调整堆,使其满足大根堆的条件,再把堆顶元素和数组倒数第二个元素交换,以此类推,最终整个数组有序(从小到大)。
三、算法分析:
1、最好的情况:O(nlog2 n)
2、最坏的情况:O(nlog2 n)
3、平均时间复杂度:O(nlog2 n)
4、空间复杂度:O(1)
5、稳定性:不稳定(有大量元素的交换)
四、算法实现:
/**
* 堆排序
* @param a
* @return
*/
public void heapSort(int a[]){
for(int i=a.length/2;i>=0;i--){ //建初始堆
HeapAdjust(a,i,a.length-1); //长度恒为数组长度,修改角标逐渐全部排完
}
for(int i=a.length-1;i>0;i--)
{
int temp=a[0]; //交换堆顶和数组末尾,实现有序区
a[0]=a[i];
a[i]=temp;
HeapAdjust(a, 0, i); //调整堆,使其满足大根堆
}
}
/**
*堆排序(堆调整)
* @param a
* @param parent
* @param length
*/
private void HeapAdjust(int[] a, int parent, int length) {
int temp = a[parent]; //暂存该节点值
int child = 2*parent+1;//获得左孩子节点角标
while(child<length){ //length取不到,那个点不能修改
if(a[child+1]>a[child]&&child+1<length){ //若右孩子节点大于左孩子节点,则取右孩子节点
child++;
}
if(temp>=a[child]){ //若父节点大于最大子节点,则满足大根堆条件
break;
}
a[parent]=a[child]; //向上赋值
parent=child; //把子节点变为父节点,继续循环查找
child = 2*child +1; //确定新的子节点
}
a[parent]=temp; //插入那个调整前的堆顶元素
}
四、算法的优缺点:堆排的效率比较高,但是算法不稳定。另外,初始化堆的过程中比较的次数较多,它不适用于小序列。
冒泡排序
一、思路:从第一个和第二个开始,依次比较数组中的相邻数,若第一个数大于第二个数,则交换位置,再比较第二个数和第三个数,若第二个数大于第三个数,则交换,以此类推,最终最大的数会出现在数组的末尾,就像“冒泡”一样。第二趟排序出现第二大的数,放在数组的倒数第二个位置,最终,整个数组有序。
二、算法分析:
1、最好的情况:O(n^2)
2、最坏的情况:O(n^2)
3、平均时间复杂度:O(n^2)
4、空间复杂度:O(1)
5、稳定性:稳定(相同大小的元素不会交换位置)
三、算法实现:
/**
* 冒泡排序
* @param a
*/
public void sort4(int[] a){
for(int i=a.length;i>1;i--)
{
for(int j=0;j<i-1;j++)
if(a[j]>a[j+1])
{
int temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
}
}
四、算法优缺点:算法比较稳定,但效率低。
快速排序
一、思路:通过的递归的思想也可以实现高效的排序。我们选取一个基准,假设我们取数组中的第一个数为基准数,取出并保存在变量中,然后分别设立左指针和右指针指向数组的两端,右指针左移直到找到第一个比基数小的数,赋值给基数所在的位置,然后左指针向右寻找大于基数的第一个值,赋给右指针;直到两指针相遇,把基数赋给指针指向的位置,数组被指针分为两部分,分别再进行快排,递归直至有序。
二、算法分析:
1、最好的情况:O(nlog₂n)
2、最坏的情况:O(n^2)
3、平均时间复杂度:O(nlog₂n)
4、空间复杂度:O(1)
5、稳定性:不稳定
三、算法实现:
/**
* 快速排序
* @param a
*/
public void quickSort(int[] a , int low ,int high){
if(low>=high)
return;
if(a.length<=0)
return;
int left=low;
int right=high;
int value = a[left];
while(left<right){
while(a[right]>=value&&left<right)
right--;
a[left]=a[right];
while(a[left]<=value&&left<right)
left++;
a[right]=a[left];
}
a[left]=value;
quickSort(a, low , left-1);
quickSort(a, left+1, high);
}
四、算法的优缺点:快速排序在数组乱序的情况下有相比其他排序很高的效率,但它在排序中涉及到了数的交换,也是一种不稳定的算法,但它的高效性使得这种算法应用广泛。
归并排序
一、思路:归并排序和快排都用到了递归的思想,但和快排有所不同,快排是先把数组以一个基准划分为两部分,再在两个部分中分别递归,即排序和递归交替进行。归并的思路是先把数组不断划分并递归为最小单位,最小单位实现有序,然后向上回溯,把两个单位合并为一个长度是两单位之和的有序的数组,然后再在这个有序数组的层面上继续归并,直至回到第一次调用的位置,归并为一个有序的数组。总之,思路就是自上而下划分为最小单位,再自下而上恢复为有序数组。
二、算法分析:
1、最好的情况:O(nlog₂n)
2、最坏的情况:O(nlog₂n))
3、平均时间复杂度:O(nlog₂n)
4、空间复杂度:O(n)
5、稳定性:不稳定
为什么是O(nlog₂n))?我们在划分为最小子单位的时候,类似于不断二分,时间复杂度为O(log₂n)),此过程中我们把长为n的数组划分为n个单位,我们需要O(n)的空间复杂度来保存子数组。还原数组的过程中时间复杂度为O(n),所以综合来说我们的时间复杂度为O(nlog₂n))。
三、算法实现:
代码分为两部分,一部分是划分最小子数组的方法,一部分是二路归并的方法。在理解这段代码的时候我们可以先从理解二路归并入手,了解它是如何把两个有序数组合并为一个有序数组的,然后只需再走合并的代码流程就可以得到有序数组。
/**
* 归并排序
*/
public void mergeSort(int[] a, int low , int high){
if(low<high) {
int mid = (low+high)/2; //划分为两个子表
mergeSort(a,low,mid); //使得左半部分有序
mergeSort(a, mid+1, high); //使得右半部分有序
merge(a,low,mid,high); //二路归并方法
}
}
/**
* 二路归并方法
*/
private void merge(int[] a, int low, int mid, int high) {
int[] temp = new int[a.length];
for(int i=low;i<=high;i++){ //把数组相应段复制一份
temp[i]=a[i];
}
int i=low;
int j=mid+1;
int k=low;
while(i<=mid&&j<=high){ //优先存小的值,实现二路归并
if(temp[i]<temp[j]){
a[k++]=temp[i++];
}else{
a[k++]=temp[j++];
}
}
while(i<=mid) //若有剩余,则插入补齐数组
{
a[k++]=temp[i++];
}
while(j<=high)
{
a[k++]=temp[j++];
}
}
四、算法的优缺点:归并排序速度较快,也比较稳定,但在数据量大的时候,可能会花费相对较多的时间。
基数排序(桶排序)
一、思路:基数排序其实非传统意义上的排序,它是一种关键字排序,我们先对个位数排序,定义一个二维数组,把原数组的数字取个位数存入二维数组(二维数组的纵坐标表示0~9的个位数分类,然后横坐标就是数据存放的累加,二维数组就像是10个桶,桶的深度即可存的最大数据数目,我们通过桶来辅助排序),设一个数组来计数,在存入完毕后,再从个位数为0开始逐个取出重新存入原数组。接下来,我们取原数组各元素的十位数,重新存入清空后的二维数组,即按照十位数排序,再次取出即为有序的数组(假设这里数据都小于100)。
二、算法分析:
1、最好的情况:O(d(n+r))
2、最坏的情况:O(d(n+r))
3、平均时间复杂度:O(d(n+r))
4、空间复杂度:O(n+r)
5、稳定性:稳定
三、算法实现:
/**
* 基数排序(桶排序)
* @param a
*/
public void radixSort(int[] a , int n){
int divisor=1; //定义每一轮的除数
int[][] bucket = new int[10][10]; //定义10*10二维数组
int[] count = new int[10]; //用来表示每一位的指针位置,防止数据覆盖
while(divisor<100) //确定循环重数
{
for(int i=0; i<n;i++)
{
int temp =(a[i]/divisor)%10; //取个位数
bucket[temp][count[temp]++]=a[i]; //把数据存入二维数组
}
int k=0;
for(int i=0;i<10;i++) //把桶中的数据取出到数组
{
for(int j=0; j<count[i] ; j++)
{
a[k++]=bucket[i][j];
bucket[i][j]=0; //每次赋值结束,数组相应位置清零
}
count[i]=0; //计数器清空
}
divisor*=10;
}
}
四、算法优缺点:桶排序速度快,而且在数据范围分布确定时,易于筛选;它的局限性也明显,如果数据有负数,会影响排序,而且它浪费了大量的空间复杂度。