Scrapy框架
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中。
其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
1. Scrapy整体架构
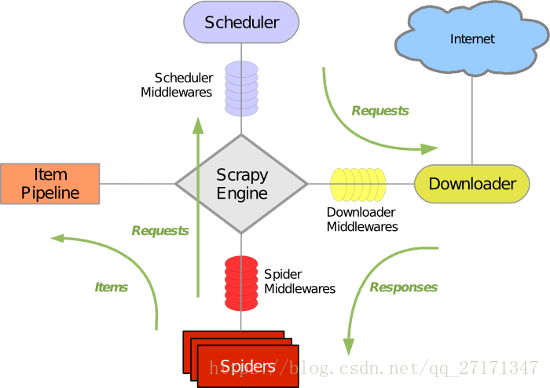
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
2. Scrapy运行流程
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
3. 安装
conda install scrapy
#windows平台需要依赖pywin32,下载地址 https://sourceforge.net/projects/pywin32/4. 基本使用
4.1 创建项目
scrapy startprojrct your_project_name此后可自动生成目录:
project_name/
scrapy.cfg #项目的配置信息,主要为Scrapy命令行工具提供一个基础的配置信息。(真正爬虫相关的配置信息在settings.py文件中)
project_name/
__init__.py
items.py #设置数据存储模板,用于结构化数据,如:Django的Model
pipelines.py #数据处理行为,如:一般结构化的数据持久化
settings.py #配置文件,如:递归的层数、并发数,延迟下载等
spiders/ # 爬虫目录,如:创建文件,编写爬虫规则
__init__.py4.2 编写爬虫
# -*- coding: utf-8 -*-
#爬取抽屉网为例
import scrapy
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['chouti.com']
start_urls = ['http://dig.chouti.com/']
def parse(self, response):
print(response.text)4.3 运行爬虫
#进入进入project_name目录,运行命令
scrapy crawl spider_name --nolog#不再输出日志5. HtmlXPathSelector 选择器
# 选择器:
'''
// 表示子孙中
.// 当前对象的子孙中
/ 儿子
/div 儿子中的div标签
/div[@id="i1"] 儿子中的div标签且id=i1
obj.extract() # 列表中的每一个对象转换字符串 =》 []
obj.extract_first() # 列表中的每一个对象转换字符串 => 列表第一个元素
//div/text() 获取某个标签的文本
'''
#函数
#包含
hxs = Selector(response=response).xpath('//a[contains(@href, "link")]')
#以什么字段开始
hxs = Selector(response=response).xpath('//a[starts-with(@href, "link")]')
#正则
hxs = Selector(response=response).xpath('//a[re:test(@id, "i\d+")]')
- Xpath语法总结
| 表达式 | 说明 |
|---|---|
| article | 获取article元素的所用子节点 |
| /article | 选取根元素article |
| article/a | 选取所有属于article的子元素a元素 |
| //div | 选取所有div子元素(文档任何位置的div元素均选取) |
| article//div | 选取属于article的所有子代div元素 |
| //@class | 选取所有名为class的属性 |
| /article/div[1] | 选取属于article子元素的第一个div元素 |
| /article/div[last()] | 选取属于article子元素的最后一个div元素 |
| /article/div[last()-1] | 选取属于article子元素的倒数第二个div元素 |
| //div[@lang] | 选取所有拥有lang属性的div元素 |
| //div[@lang=’eng’] | 选取所有拥有lang属性为eng的div元素 |
| /div/* | 选取属于div元素的所有子节点 |
| //* | 选取所有元素 |
| //div[@*] | 选取所有带属性的title元素 |
| /div/a l //div/p | 选取所有div元素的a和p元素 |
| //span l //ul | 选取文档中的span和ul元素 |
| article/div/p l span] | 选取所有属于article元素的div元素的p元素以及文档里所有的span元素 |
6. 递归访问爬取网页
import scrapy
import scrapy
from ..items import BoleItem
from scrapy.selector import Selector,HtmlXPathSelector
from scrapy.http import Request
class ExcerptSpider(scrapy.Spider):
name = 'excerpt'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
#按链接中所有其余页面链接来全部爬取
visited_urls = set()#去重处理
def parse(self, response):
hxs2 = Selector(response=response).xpath('//div[@class="navigation margin-20"]//a/@href').extract()
for url in hxs2:
# print(item)
if url in self.visited_urls:
print('已经访问过此链接')
else:
print('网址:',url)
self.visited_urls.add(url)
#将要新访问的url添加到调度器
yield Request(url=url ,callback=self.parse)
#按下一页链接来全部爬取
nextLink = Selector(response=response).xpath('//div[@class="navigation margin-20"]//a[@class="next page-numbers" ]/@href').extract()
yield Request(url=nextLink ,callback=self.parse)7. 获取Cookies
def parse(self, response):
from scrapy.http.cookies import CookieJar
cookieJar = CookieJar()
cookieJar.extract_cookies(response, response.request)
print(cookieJar._cookies)8. Items格式化处理
import scrapy
class BoleItem(scrapy.Item):
title = scrapy.Field()
context = scrapy.Field()此时在Spider项目中需加如下操作
- 将获取的数据封装在了Item对象中
- yield Item对象 (一旦parse中执行yield Item对象,则自动将该对象交个pipelines的类来处理)
from ..items import BoleItem
item_obj = BoleItem(title=title,context=context)
#将item_obj对象传递给pipeline
yield item_obj注:当pipeline中有多个类时,需在settings里定义Scrapy执行顺序的优先级
ITEM_PIPELINES = {
'beauty.pipelines.DBPipeline': 300,
'beauty.pipelines.JsonPipeline': 100,
}
# 每行后面的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。实例之爬取伯乐在线所有文章
#sprider
# -*- coding: utf-8 -*-
import scrapy
from ..items import InfosItem
from scrapy.selector import Selector,HtmlXPathSelector
from scrapy.http import Request
from urllib import parse
class InfospSpider(scrapy.Spider):
name = 'infosp'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/all-posts/']
def parse(self, response):
post_urls = Selector(response=response).xpath('//div[@class="post floated-thumb"]/div[@class="post-thumb"]/a/@href').extract()
for post_url in post_urls:
# print(post_url)
yield Request(url=parse.urljoin(response.url, post_url), callback=self.parse_detail)
next_url = Selector(response=response).xpath('//div[@class="navigation margin-20"]//a[@class="next page-numbers" ]/@href').extract_first()
if next_url:
# print(next_url)
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse)
def parse_detail(self, response):
title = response.css(".entry-header h1::text").extract()[0]
print(title)
articles = Selector(response=response).xpath('//div[@class="entry"]//p/text()').extract()
# print(articles)
hxs = Selector(response=response).xpath('//div[@class="post-adds"]')
for obj in hxs:
praise_numbers = obj.xpath('//h10[@id]/text()').extract_first()
# print(praise_numbers)
collect_numbers = obj.xpath('//span[@class=" btn-bluet-bigger href-style bookmark-btn register-user-only "]/text()').extract_first()
# print(collect_numbers)
item = InfosItem()
item["title"] = title
item["articles"] = articles
item["praise_numbers"] = praise_numbers
item["collect_numbers"] = collect_numbers
yield item#items
import scrapy
class InfosItem(scrapy.Item):
title = scrapy.Field()
articles = scrapy.Field()
praise_numbers = scrapy.Field()
collect_numbers = scrapy.Field()#pipelines
import pymysql
connect = pymysql.connect(host="localhost", user="root", password="******", db="bole2", charset="utf8")
cursor = connect.cursor()
def process_item(self, item, spider):
sql = 'INSERT INTO article VALUES ("%s","%s")'
datasql = sql % (item["title"], item["context"])
self.cursor.execute(datasql)
self.connect.commit()
return item