1、GBDT简介
GBDT,英文全称是Gradient Boosting Decision Tree,梯度提升决策树,顾名思义,与梯度、boosting算法、决策树有关。是一种迭代的决策树算法,由多棵决策树组成,每一颗决策树也叫做基学习器,GBDT最后的结果就是将所有基学习器的结果相加。
2、集成算法
GBDT既然跟boosting算法有关,就先来讲讲boosting算法,boosting是集成算法的一种。如果不想看,直接跳到GBDT章节,再回过头来看也可以。
Boosting,是集成学习算法的一种。什么是集成学习算法?可参考决策树系列(一):集成学习(ensemble learning)->boosting与bagging的区别。下面来简单介绍一下。
集成算法,是一种提高弱分类算法准确度的方法,就是将多个弱分类算法(基学习器)以一定的方式集合在一起,然后再以一定的方式集结多个弱学习算法的结果,作为最终的结果。集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能。
根据集成基学习器方式的不同,会细分为不同的算法,大致分为以下2种:
(1)各个基学习器之间相互独立,不存在依赖关系,典型算法有bagging、随机森林;
(2)各个基学习器之间存在强依赖关系,每一个基学习器都是在前一个基学习器的基础上才能生成,典型算法有boosting。
集成算法的结果集合策略也有很多种:
(1) 平均法
(2)加权平均法
(3)投票法
(4)学习法
3、boosting算法
Boosting,是集成学习算法的一种,属于基学习器之间存在强依赖关系的那一种,并且将所有基分类器的结果相加作为算法的最后结果。
所以简单来说,boosting算法,是一个加法模型(将若干个基学习器加在一起,每一个基学习器都有一个系数。用所有基学习器结果的加权和,作为该算法的最终结果),并且每一个基分类器是在前一个基分类器的基础之上生成的。
那么boosting算法究竟是怎么学习,得到最终结果的呢?
怎么将boosting算法的原理数学化,变成可以求解的数学公式??
将【boosting算法,是将若干个基学习器加在一起,每一个基学习器都有一个系数,并且每一个基分类器是在前一个基分类器的基础之上生成的。】这句话,数学化就是:boosting算法,就是一个加法模型,利用前向分布算法作为优化方法,实现学习,得到最终结果。
什么是加法模型?
就是基学习器的线性组合。boosting算法不是将若干个基学习器集成在一起吗?怎么集成的?就是简单地将多个基学习器相加,每一个基学习器有一个系数。就是这么简单。用一个数学公式表示就是:

什么是算法模型的学习/优化?
用一个算法去预测样本的目标值,我们怎么知道这个算法模型好不好用呢?看该算法对样本的预测值与样本真实值之间的差异,差异越小,说明该模型算法越好用。
一个算法模型,在最初的参数下,不能保证是好用的,用此时的模型对样本进行预测,预测值与样本真实值之间的差异,不能保证是最小的。所以我们就需要让该算法进行学习,学习的目标就是让样本预测值与真实值之间的差异最小,学习的过程就是不断调整模型参数,以缩小这个差异,直到缩小到足够小。我们平时说的模型算法的学习过程,就指的是这个过程。
样本预测值与其真实值之间的差异,总得有一个数学公式来表示,这个数学公式就叫做损失函数,损失函数的值就是样本预测值与真实值之间的差异。损失函数有很多种定义方式,各有优缺点,这里先不展开。
在给定训练数据集
和损失函数
的情况下,以加法模型为例,学习加法模型
就是让损失函数极小化,可以用以下的数学公式表示:
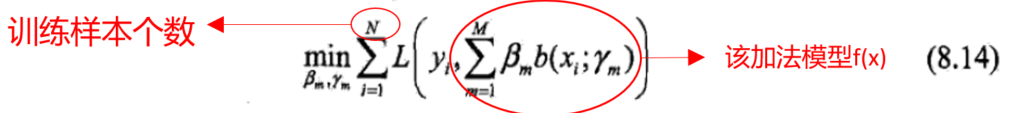
总结几种说法,以下几种说法代表的是同一种意思:
优化一个算法模型
= 学习一个算法模型
= 不断调整该算法模型的参数,使得该算法对样本的预测值与样本真实值之间的差异越来越小,直到达到足够小
= 不断调整该算法模型的参数,使得该算法朝着损失函数最小化的方向前进,直到满足条件
什么是前向分步算法?
是一种优化方法。
既然算法要进行学习,那么怎么来调整算法模型的参数,才能使得损失函数最小呢?总得有一个方法来指导,不能瞎调。这个方法就是我们说的优化方法。
加法模型朝着损失函数最小化的方向进行优化,所使用的优化方法就叫做前向分步算法。
优化问题一般都很复杂,加法模型算法涉及到若干个基学习器,每一个基学习器就是一个小算法,要优化若干个小算法,使其整体沿着整体损失函数最小化的方向前进,究竟该怎么做?基于加法模型的特点,发现如果能够从前向后,每一步只学习/优化一个基分类器及其系数,逐步逼近最终目标(8.14),就可以简化优化的复杂度。事情证明,此种方法确实可行,具体步骤如下:

那么损失函数应该使用什么?公式(8.16)怎么实现?往下看。
上面的过程就是boosting算法的学习/优化步骤的大体框架。
4、提升树:boosting+决策树
当boosting算法中的基学习器是决策树时,这个模型算法就叫做提升树。
提升树模型: 采用加法模型(基函数的线性组合),优化方法采用前向分步算法,同时基函数采用决策树,对待分类问题采用二叉分类树,对于回归问题采用二叉回归树。提升树模型整体结构如下:

进一步展开,具体步骤伪代码如下:
哪个地方体现了boosting算法中,各个基分类器之间存在强依赖关系?这个强依赖关系是怎样的?
步骤(a)(b)体现了这一点。基分类器是回归树,每一棵回归树是在前一棵回归树的基础之上生成的。强依赖关系就是:当损失函数是平方误差损失时,每一颗回归树拟合的是样本在前一棵回归树的残差。
为什么是拟合残差呢?
因为我们所用的损失函数是——平方误差损失函数。

当选用其他损失函数,如指数函数、负二项似然对数损失函数等一般损失函数的时候,每一棵回归树拟合的就不是残差了,而是残差的近似值——损失函数的负梯度值。GBDT章节会展开论述。
boosting算法中还有一步,步骤(8.25):最小化损失函数,可是看上面的伪代码,没有这一部分啊?最小化损失函数的操作体现在哪?
体现在步骤(b)。让每一棵树拟合前一棵树残差的过程,就是最小化损失函数的过程。因为,残差 实际上是平方误差损失函数的负梯度。这样的话,每一棵回归树,拟合的就是该损失函数的负梯度,然后以此类推,之后产生的每一棵回归树都是朝着损失函数的负梯度方向进行学习拟合。所以整体来看,整个算法就是朝着损失函数的负梯度方向进行学习的,这个不就是梯度下降算法么?梯度下降算法就是最小化损失函数的算法啊。
上面步骤中,每一棵回归树有了拟合目标值,但究竟是怎么进行拟合,整棵树的结构是怎么产生的?
可以参考决策树系列(一):CART-分类回归树-建模步骤以及代码,但是在这里我在详细地梳理一下,具体步骤如下:
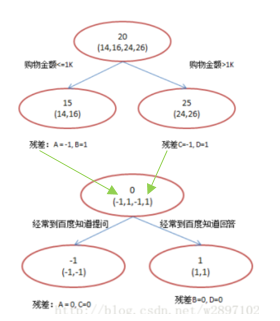

到这里,大家就应该明白了提升树究竟是什么,并且具体是怎么学习生成的。
但是有一个问题:当提升树的损失函数为均方误差、指数损失时,每一步优化(最小化损失函数)是简单的(后一棵树拟合前一棵树的残差),但对于一般损失函数而言,往往每一步的优化并不容易。Freidman提出了梯度提升(Gradient Boosting)算法,利用最速下降的近似方法,其关键是利用损失函数的负梯度在当前模型的值作为提升树算法中残差的近似值,拟合一个回归树。这就是GBDT。
5、GBDT算法
将上面的内容总结一下:
集成算法: 将多个弱分类算法(基学习器)以一定的方式集合在一起,然后再以一定的方式集结多个弱学习算法的结果,作为最终的结果。有2种基学习器集成方法:1、 各个基学习器之间相互独立;2、 各个基学习器之间存在强依赖关系。
boosting算法: 是一个加法模型(将若干个基学习器加在一起,每一个基学习器都有一个系数。用所有基学习器结果的加权和,作为该算法的最终结果),并且每一个基分类器是在前一个基分类器的基础之上生成的。
提升树算法: boosting+决策树 = 采用加法模型,优化方法采用前向分步算法,同时基函数采用决策树,对待分类问题采用二叉分类树,对于回归问题采用二叉回归树。
GBDT: 梯度提升决策树 = 梯度 + 提升树,是一种集成算法,以回归树为基学习器,每一颗回归树拟合是损失函数的负梯度在上一颗回归树时的值,整个算法也是根据前向优化算法进行学习优化。回归树是什么,可以看这个决策树系列(一):CART-分类回归树-建模步骤以及代码。
GBDT算法模型,具体步骤伪代码如下:

其中,回归树的生成过程同提升树的生成方法。
哪个地方体现了boosting算法中,各个分类器之间存在强依赖关系?
步骤(a)(b),基分类器是回归树,每一棵回归树是在前一棵回归树的基础之上生成的。强依赖关系就是:当损失函数是任何一般损失函数时,每一颗回归树拟合的是损失函数的负梯度在前一棵回归树时的值。
当每一棵回归树的损失函数是平方损失函数时,每一棵决策树(除了第一棵决策树)拟合的是上一棵树的残差;当每一颗回归树的损失函数是一般的损失函数时,每一棵决策树拟合的是上一棵树残差的近似值:损失函数的负梯度。
boosting算法中还有一步,步骤(8.25):最小化损失函数,可是看上面的伪代码,没有这一部分啊?最小化损失函数的操作体现在哪?
体现在步骤(b)。让每一棵树拟合损失函数的负梯度在前一棵回归树时的值的过程,就是最小化损失函数的过程。每一棵回归树,都是朝着该损失函数的负梯度方向进行学习拟合。整体来看,整个算法就是朝着损失函数的负梯度方向进行学习,这个不就是梯度下降算法么?梯度下降算法就是最小化损失函数的算法。
GBDT更详细的代码层级的步骤如下:

还有一个问题,怎么初始化最一开始的加法模型?
在GBDT中,最一开始的加法模型被初始化成了
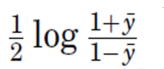
为什么?

参考文献
【1】Boosting(Adboost、GBDT、Xgboost)
【2】李航《统计学习》
【3】https://github.com/zhaoxingfeng/GBDT