java集合整体分为Collection和Map两种。
java.util包中集合详解
Java中Collection与Map详解
Java基础——集合类 左Collection,右Map
总结一下Collection和Map,它们的父子关系为:
java.util
+Collection 这个接口extends自 --java.lang.Iterable接口
+List 接口
-ArrayList 类 #ArrayList实现了可变大小的数组。
#它允许所有元素,包括null。ArrayList没有同步
#线程不安全的
-LinkedList 类 #LinkedList没有同步方法。
#如果多个线程同时访问一个List,则必须自己实现访问同步
+Vector 类 #此类是实现同步的,线程安全
- Stack类:继承自Vector,实现一个后进先出的堆栈
+Queue 接口
+不常用,
+Set 接口 不包含重复的元素的Collection
+SortedSet 接口
-TreeSet 类
#TreeSet实现了SortedSet接口,能够对集合中的对象进行排序
-HashSet
#按照哈希算法来存取集合中的对象,存取速度比较快。
+Map 接口 #Map没有继承Collection接口,Map提供key到value的映射
-HashMap 类 (除了不同步和允许使用 null 键/值之外,与 Hashtable 大致相同.)
-Hashtable 类 此类是实现同步的,不允许使用 null 键值
+SortedMap 接口
-TreeMap 类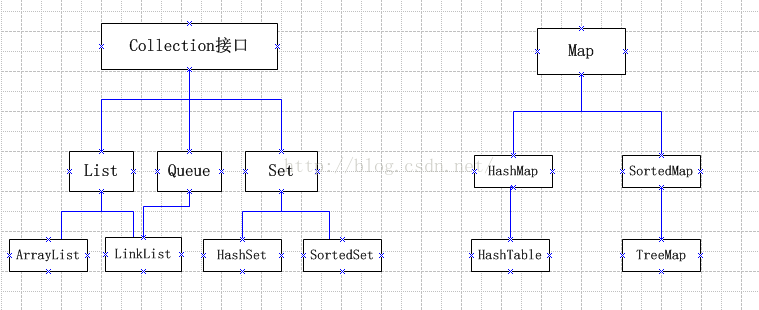
下面正式将HashMap和HashTable:
HashMap和Hashtable都实现了Map接口,但使用它们可以根据它们区别合理选择使用,主要的区别有:线程安全性,同步(synchronization),以及速度。
1.继承的接口和类不同
public class HashMap extends AbstractMap implements Map, Cloneable, Serializable{}
public class Hashtable extends Dictionary implements Map, Cloneable, java.io.Serializable{}
2.线程安全
HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,HashTable中的方法是同步的。故Hashtable是线程安全的,多个线程可以共享一个Hashtable;而如果没有正确的同步的话,多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。
可以查看HashTable中方法代码:(做了同步处理)
public synchronized V put(K key,V value) {
// Make sure the value is not null
if(value==null) {
throw newNullPointerException();
}3、null的处理:
HashMap 可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行),其中只有一个key可以为null,多个不同的key对应的value可以为null。判断是否存在某个key应该用containsKey(key)。
HashTable 的key和value都不能为null,否则抛出异常NullPointerException
4、遍历方式略有差异:
HahsMap,Hashtable都可使用Iterator遍历:
Collectioncollection=map.values();
Iteratorit=collection.iterator();
CollectioncollectionTable=table.values();
IteratoritTable=collectionTable.iterator();Hashtable还使用了Enumeration的方式:
public synchronized Enumeration elements() {
return this.getEnumeration(VALUES);
}两者也都可以通过 entrySet() 方法返回一个 Set , 然后进行遍历处理:

HashMap:
Set setMap=map.entrySet();
Iterator itMapSet=setMap.iterator();
while(itMapSet.hasNext()) {
Map.Entryentry= (Map.Entry)itMapSet.next();
System.out.println("entry.getKey() = "+entry.getKey() +", entry.getValue() = "+entry.getValue() );
}
HashTable:
Set setTable=table.entrySet();HashMap的迭代器(Iterator)是fail-fast迭代器(java.util 包中的集合类都返回fail-fast 迭代器,这意味着它们假设线程在集合内容中进行迭代时,集合不会更改它的内容。如果fail-fast 迭代器检测到在迭代过程中进行了更改操作,那么它会抛出ConcurrentModificationException ,这是不可控异常),而Hashtable的enumerator迭代器不是fail-fast的。所以当有其它线程改变了HashMap的结构(增加或者移除元素),将会抛出ConcurrentModificationException,但迭代器本身的remove()方法移除元素则不会抛出ConcurrentModificationException异常。但这并不是一个一定发生的行为,要看JVM。这条同样也是Enumeration和Iterator的区别。
5、哈希值的使用不同
Hashtable直接使用对象的hashCode:
int hash=key.hashCode();而HashMap重新计算hash值:
static final int hash(Objectkey) {
int h;
return(key==null) ?0: (h=key.hashCode()) ^ (h>>>16);
}6、Hashtable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
why? :
因为:在hashmap的源码中。put方法会调用indexFor(int h, int length)方法,这个方法主要是根据key的hash值找到这个entry在table中的位置,源码如下:/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : “length must be a non-zero power of 2”;
return h & (length-1);
}
注意最后return的是h&(length-1)。如果length不为2的幂,比如15。那么length-1的2进制就会变成1110。在h为随机数的情况下,和1110做&操作。尾数永远为0。那么0001、1001、1101等尾数为1的位置就永远不可能被entry占用。这样会造成浪费,不随机等问题。
注意:
1) sychronized意味着在一次仅有一个线程能够更改Hashtable。就是说任何线程要更新Hashtable时要首先获得同步锁,其它线程要等到同步锁被释放之后才能再次获得同步锁更新Hashtable。
2) Fail-safe和iterator迭代器相关。如果某个集合对象创建了Iterator或者ListIterator,然后其它的线程试图“结构上”更改集合对象,将会抛出ConcurrentModificationException异常。但其它线程可以通过set()方法更改集合对象是允许的,因为这并没有从“结构上”更改集合。但是假如已经从结构上进行了更改,再调用set()方法,将会抛出IllegalArgumentException异常。
3) 结构上的更改指的是删除或者插入一个元素,这样会影响到map的结构。