本节所述的内容为与支持向量机(SVM)相关的数学基础知识。总的来说,我先介绍了凸优化问题求最优解的思路,介绍了拉格朗日乘子法和KKT条件,随后根据KKT条件给出了求解有不等式约束的凸优化问题的一种解法,即拉格朗日对偶。
我的学习体会是,如果不理解上面说的这些数学基础知识,学习SVM会寸步难行。所以我把基础知识部分当做学习SVM的第一站。当然,如果你已经了解这些,也可以直接跳到我的下一篇博客 SVM解释:三、线性可分的情况 去,或者你打算先看问题,再求数学解答,也可以先看后面的,不明白了再回过头看数学基础。
1. 凸优化问题
通常,我们要求解的函数优化问题,大致可分为以下3类:
- 无约束条件的优化问题: ;
- 只有等式约束的优化问题:
; - 含不等式约束的优化问题:
;
其中大写的 表示所有自变量的集合, 表示等式约束条件, 表示不等式约束条件。我这里用 表示求取最优值的目标函数,其实不一定是求取最小值,求最大值也是可以的,我只是用这种方式表示而已。
为了讲述方便,本节中,默认所要解决的最优问题都是凸优化问题(即求取凸函数的最优解)。凸函数的解释如下:凸函数指的是那些开口朝一个方向(向上或向下)的函数。我们可以通过令其导数等于0的方法求取该函数的全局最优解(极值)。显而易见,对于非凸函数来讲,导数为0这种方法只是可以求得局部最优解(极值),而不一定是全局最优解。
上面只是我给出的一个方便理解的说明,关于凸函数的准确定义还请参考专业的数学教材。需要强调的是,后面要说的拉格朗日乘子法一定是适用于凸优化问题的,而不一定适用于其他非凸问题。
回到最上面的3类优化问题,解决方法是明确的,参考如下(注意,我默认都是针对凸优化问题):
- 对于无约束条件的优化问题,直接对其各个自变量求导,令导数为0,得全局最优解。这是我们高中就会的东西,不多说了;
- 对于只有等式约束的优化问题,利用拉格朗日乘子法,得全局最优解。具体步骤下面详细说;
- 对于含不等式约束的优化问题,利用KKT条件,得全局最优解。具体步骤下面详细说;
后两类问题(尤其是对含不等式约束的优化问题),是本节(也是SVM)所重点关注的问题。我们先从拉格朗日乘子法说起。
2. 拉格朗日乘子法
2.1 基本思路
举个例子来描述拉格朗日乘子法的基本思路:
注1:本文中的例子取自博客:解密SVM系列(一):关于拉格朗日乘子法和KKT条件,这篇博客的博主讲解这个问题非常细致,推荐大家阅读。
这个例子正是我在上面说的3类情况的第二种,只有等式约束条件的优化问题。求解思路如下:
首先想到直接对3个自变量分别求偏导,令其偏导数都为0,则此时 都是0,看函数也是这样,当3个自变量都是0时,函数取得最小值0。但是这显然是不符合约束条件的。怎么把约束条件考虑进去呢?用拉格朗日乘子法,把改写后的约束条件乘以一个系数,然后以加的形式带入目标函数,该函数我称之为拉格朗日函数。先看看改写后的约束条件:
左右移项,实际上没发生任何变化。其后,将改写后的约束条件带入目标函数,构造拉格朗日函数:
可见,当求得的最优解满足约束条件时, 与原始的目标函数并没有差别(后面都是0)。这样,我们再对这个拉格朗日函数求关于各个自变量的偏导,并令这些偏导数为0。
现在,将用系数 表示的3个自变量带入约束条件,可得如下方程:
两个未知数,两个方程,可以求解得到 ,再带入自变量的表达式,即求得最优解。
2.2 拉格朗日乘子法的形式化描述
用拉格朗日乘子法解决只有等式约束条件的优化问题,可以被如下形式化的描述:
现有优化问题:
则需要先得到拉格朗日函数 ,对该函数的各个自变量求偏导,令偏导数为0,则可以求出各个自变量的含系数 的代数式,再带入约束条件,解得 后,可最终得到最优解。这种做法的理论依据可以参照博客:深入理解拉格朗日乘子法(Lagrange Multiplier) 和KKT条件
3. KKT条件
上面说的拉格朗日乘子法,解决的是只有等式约束条件的优化问题,而现实中更普遍的情况是求解含不等式约束条件的问题。也就是最开始说的第3类情况。
还是通过一个例子讲解。优化问题如下:
第一步,把约束条件改写如下:
改写的目的是方便后面的计算,且这种改写没有改变约束条件本身,所以不影响。
第二步,与拉格朗日乘子法相同,给约束条件乘以系数后加入目标函数,构成拉格朗日函数 :
第三步,对拉格朗日函数的各个自变量求偏导:
做完以上3步,先不往下进行了。我先给出KKT条件的形式化描述如下。
现有优化问题:
根据这个优化问题可以得到拉格朗日函数:
那么KKT条件就是函数的最优值必定满足下面3个条件(这3个条件是重点中的重点):
- 对各个自变量求导为零;
- ;
- 其中
3个条件中,前两个很好理解,不多说了。关键在于第3个条件。这也是最难理解的部分。我尝试解释一下这个条件的原理。如果没有说清楚,欢迎留言讨论。
首先,我们已知 ,而 (这样设计的目的是要求目标函数的梯度和约束条件的梯度必须反向)。也就是说,想要条件3成立,则每一项 都等于0,再换个说法,对于每一项来说,要么 ,要么 ,这是条件3的含义。下面我要解释为什么这样的条件可以用来寻找最优解。
假设 由2个自变量 组成,那么我们很容易想象出目标函数 的图像,它就是一个三维空间中的曲面;再假设此时优化问题有3个不等式约束条件 。那我现在可以把优化问题的图像画出来,如下图所示。我画的是该问题在 平面上的投影,虚线为 的等高线,那现在就有三种不同情况了:
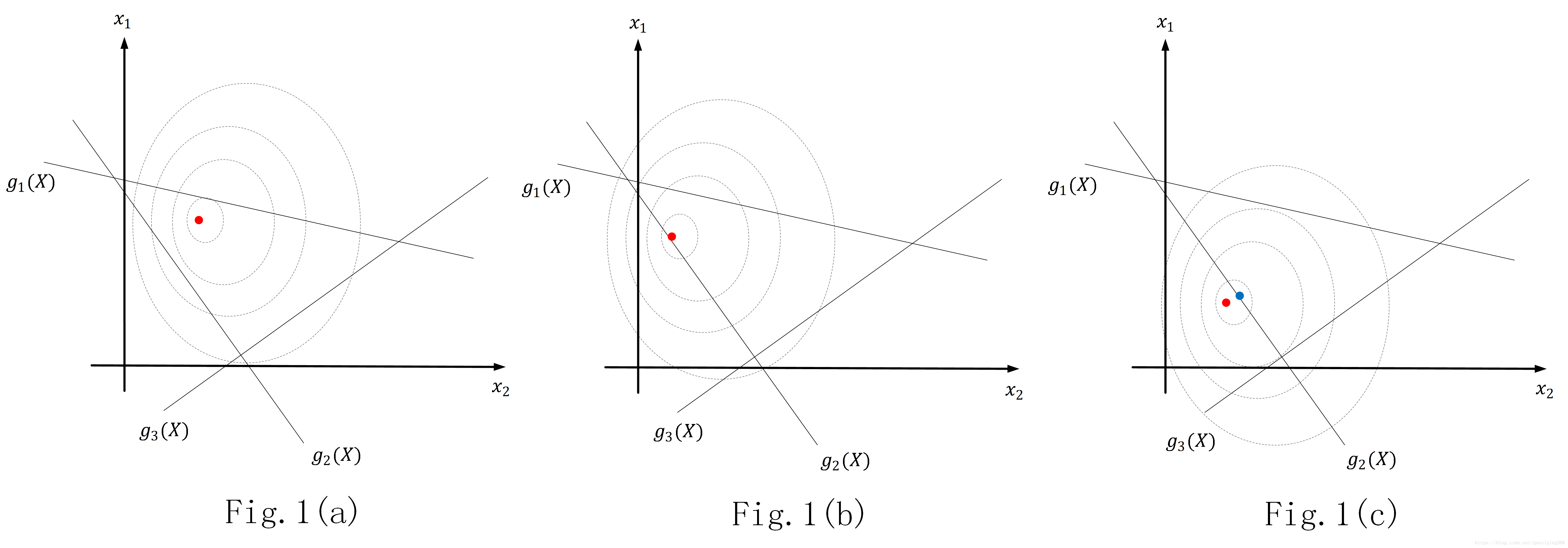
函数f(X)的极小值点在约束范围内,如Fig.1(a)所示。这时, 的最优解与不等式的约束没关系了,我们令 ,此时的情况与只含有等式约束的优化问题是等价的。综上,满足条件1,2,3;
函数f(X)的极小值点在约束面上,如Fig.1(b)所示。这时, 的要达到最优解,则需要某一个或某几个 。就拿Fig.1(b)的这种情况来说,此时,实际上可以把约束条件写成如下形式。我们发现, 条件变成了等式约束,使得现在的约束条件与左图所示的本质上是一样的了。综上,满足条件1,2,3;
函数f(X)的极小值点在约束外,如Fig.1(c)所示。这时,最优解一定在约束面上,比如Fig.1(c)中的蓝点,而且最优解不是函数 的极值点。此时的最优解满足 与 的不等式条件,同时因为在 的图像上,所以本质上等价于Fig.1(b)所示的情况。综上,满足条件1,2,3;
从以上三种情况分析,我们发现带不等式约束的凸优化问题的最优解一定是满足KKT条件的。而KKT条件本质上是拉格朗日乘子法的一种扩展。
那么好,了解了KKT条件是什么,就可以回到上面的例子了。刚才说到第三步是对生成的拉格朗日函数求偏导。现在继续第四步:
第四步,计算满足KKT条件的值。三个条件,三个步骤:令各偏导数为0;这里没有等式约束条件,条件2不管了;对于条件3,因为要令 成立,所以一共有4种情况:
具体的计算结果我省略了。最后发现最后一个条件是最优解,这也说明最优解正好在约束条件的边界上。
这里面还有一个很重要的问题,那就是当有多个 的时候,对于条件3,我们应该如何用KKT中的条件3呢?一般的做法是两两配对,比如说有3个,我们就两两配对形成3组,每组和上面一样,4种情况讨论即可。
如果你看了我的下一篇博客 SVM解释:三、线性可分的情况,你就知道,SVM的基本数学模型就是一个带不等式约束的凸优化问题。但是,为了方便理解在数据线性不可分的情况下SVM是如何使用核函数的(这是我第4篇博客要讲到的内容),我们一般不直接用KKT条件求解,而是将带不等式约束的凸优化问题转换成拉格朗日对偶问题。因此,作为数学基础,我在本篇博文中把拉格朗日对偶一并介绍了。
4. 拉格朗日对偶
4.1 基本概念
我们知道对偶是求解优化问题的一种手段,它将一个优化问题转换为另一个更容易求解的问题,而这两个问题是等价的。常见的对偶有拉格朗日对偶,Fenchel对偶等等。SVM中用到的是拉格朗日对偶。具体的做法如下,现在有带约束的优化问题:
我们可以先写出它的拉格朗日函数:
接下来,定义下式:
这个式子的意思是将 看作是常数,将 看做变量,求 的最大值。
根据这个 ,我们可以将公式(1)中有不等式约束的优化问题转换成没有约束的优化问题,记为 ,也称之为原问题,具体如下:
这个式子的含义是:先固定 ,把它当做一个常量,然后求在变量 的影响下拉格朗日函数的最大值,再把 当做变量,求这个函数的最小值。
注2:这里面有一点非常关键,那就是为什么 的最优解就是要求解的 的最优解?根据上面关于KKT条件的讲解,我们知道,求解有不等式约束的凸优化问题可以利用KKT条件。那你看看前面KKT的3个条件,通过条件2和3可知,在满足KKT条件时, 其实是等价于 。而要满足条件2和3,自然需要先在 固定时(你可以想象,所谓固定 ,其实就是假设 已经是最优解了),最大化 ,当 是最优解时,最大化的结果就是0.
但是这样的原问题在我今天讨论的SVM中是不太容易求解的,所以还需要将原问题转换为其对偶问题,再求解。至于为什么原问题不易求解,原因我会在后一篇博客中看具体问题时解释。这里,你值需要知道什么是刚才那个原问题的对偶问题就行了。
对偶问题记为 ,可以如下表示:
其中,
4.2 强对偶和弱对偶
为什么可以做这样的对偶转换?我们发现,其实所谓对偶转换,就是变了求最大最小值的操作顺序,那如果这种操作顺序的变化不影响最终的最优解,当然是可以变换的,所以关键问题在于什么情况下,对偶问题不改变最优解?这里面就有一个强对偶和弱对偶的问题。
- 弱对偶:如果原问题和对偶问题都存在最优解,且对偶问题的最优解不大于原问题的最优解;
- 强对偶:如果原问题和对偶问题都存在最优解,且对偶问题的最优解等于原问题的最优解;
强对偶存在的前提是Slater条件,Slater条件指出,一个凸优化问题如果存在一个候选 使得所有不等式约束都严格满足,即带入所有的 ,都是小于0的(不存在等于的情况),则存在 同时是原问题与对偶问题的最优解。后面你会发现SVM解决的问题中,Slater条件是成立的。所以,我们可以直接用它的对偶问题求解。当然这一点我会在后面的讲解中体现出来。
总结一下:带不等式的优化问题可以采用KKT条件求解,为了更容易理解对于线性不可分数据采用的核函数的工作原理,我在讲解SVM时,会做两次转换:
- 把求解带不等式约束的优化问题转换成求解拉格朗日对偶问题;
- 把对偶问题中的原问题转换成其对偶问题,依据是SVM中需要解决的优化问题恰好满足Slater条件;