1.大型互联网应用的特点
- 高并大流量:面对的是高并发的用户以及大流量的访问。
- 高可用:系统7 * 24小时不断服务。
- 海量数据:需要存储并管理海量的数据,这会用到大量的服务器。
- 用户分布广泛,网络情况复杂:许多的大型互联网应用都是为全球用户服务的,但用户分布范围广,而且各地的网络情况千差万别。
- 安全环境恶劣:由于互联网的开放性,会使的网站很容易收到黑客的攻击。
- 需求快速变更,发布频繁:大型网站每周都会有新版本发布,而中小型网站可能一天发布几十次。
- 渐进式发展:几乎所有的大型互联网网站都是从小网站起步,然后渐进发展。
2.架构演化发展历程
因为庞大的用户,高并发的访问量以及海量的数据,所以任何简单的特务都要处理P(10的15次方,1000 T = 1 P)级的数据,以及面对数以数计的用户。架构就是为了解决这些问题。
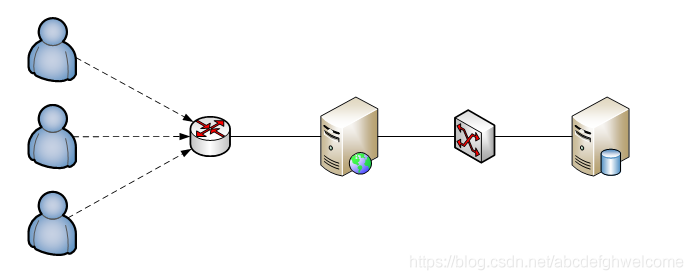
2.1初级阶段
小型网站没有太多人访问,所以只需要一台服务器就够了。
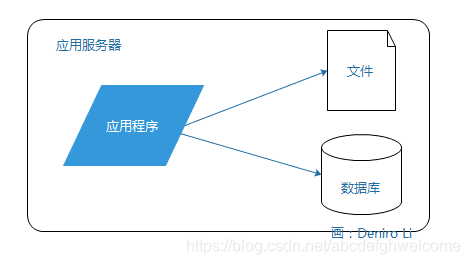
应用程序,文件,数据库都部署在一台服务器上,通常是使用LAMP(Linux Apache MYSQL PHP)。
2.2应用服务和数据服务分离
随着业务的发展,越来越多用户的访问导致性能越来越差,而越来越多的数据也会耗尽存储空间,这就需要将应用与数据分离;
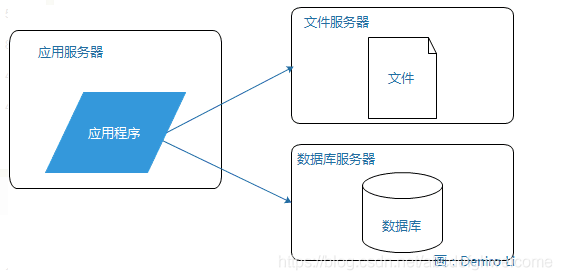
这里使用三台服务器:应用服务器,文件服务器和数据库服务器他们对硬件资源的要求不同。
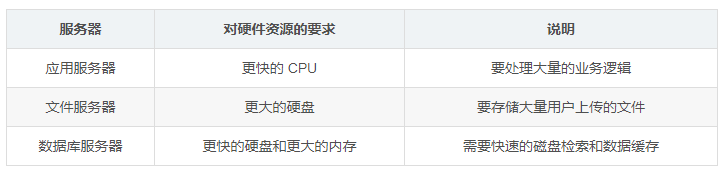
不同特性的服务器可以承担不同的服务角色,使得网站的并发处理能力和数据存储空间都有了很大的改善。
但随着用户数量的再次增长,发现数据库的压力太大而导致的网站访问延迟问题,所以需要再次优化。
2.3使用缓存改善性能
网站访问的特点遵循经典的二八定律:80%的业务访问集中在20%的数据上所有把这一小部分数据缓存在内存中就能减少数据库的访问压力。
缓存可分为两种。在应用服务器上的本地缓存和在分布式缓存服务器上的远程缓存。

远程分布式缓存使用集群,而且可以使用安装了大内存的服务器作为专门的缓存服务器。
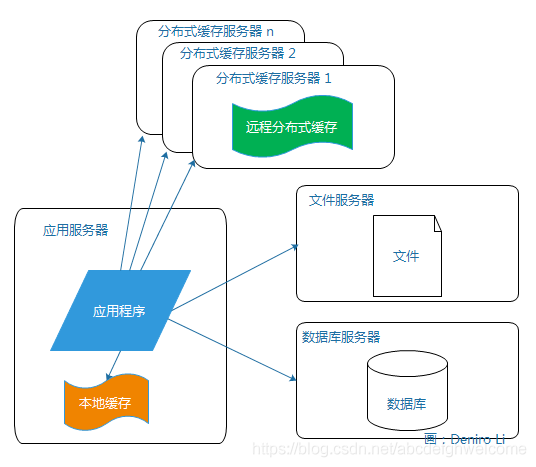
使用缓存后,数据库的访问压力得到缓解,但单一的应用服务器能够处理的请求连接有限,所以在网站访问的高峰期,有可能成为整个网站的瓶颈。
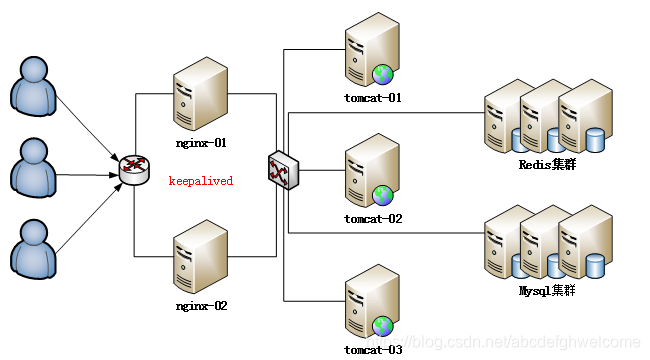
2.4应用服务器集群
使用集群是解决高并发,海量数据问题的常用手段。当一台服务器的处理能力,存储空间不足时,最恰当的做法是正价新的服务器,让它来分担原有服务器的访问和存储压力。
我们可以通过持续的增加服务器,来不断改善系统的性能,从而实现系统的可伸缩性。
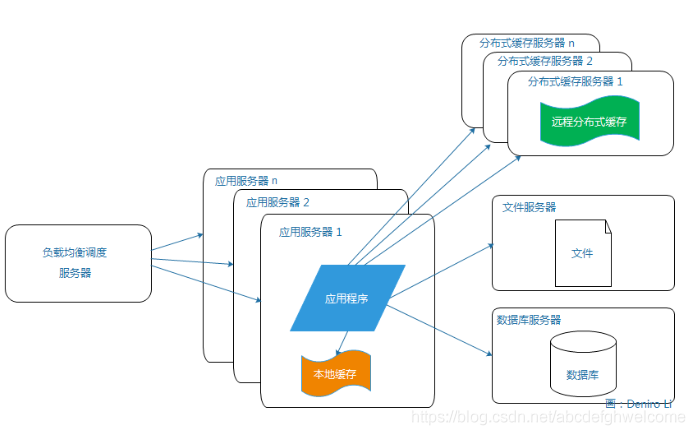
通过负载均衡调度服务器,可以将用户的访问请求分发到应用服务器集群中的任何一台服务器上。如果有更多的用户,我们就可以在集群中加入更多的应用服务器。
2.5数据库读写分离
使用了缓存后,使得绝大对数数据的读操作可以不通过数据库就能完成。但仍然有部分的读操作(因为缓存访问没有命中或缓存过期)和全部的写操作需要访问数据库,所以在用户量达到一定规模时,数据库还是会因为负载过高而成为瓶颈。
目前的主流数据库度提供了主从热备功能,可以通过配置两台数据库的主从关系,把一台数据库服务器的数据同步到另一台服务器上。我们可以利用这个功能,实现数据库的读写分离,进一步提高数据库的负载能力。
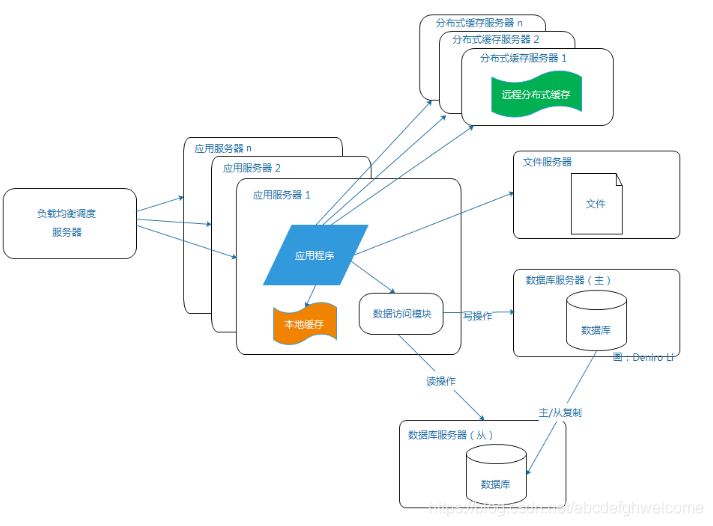
为了便于应用程序访问读写分离的数据库,一般会在服务器端使用专门的数据访问模块,让数据库的读写分离机制对应用程序透明,这样做不仅降低了代码编写的复杂性,还提高了可维护性,可谓两全其美
2.6使用反向代理和CPU加速相应
网站的访问延迟与用户的流失率正相关。因为网站访问的越慢,用户就越容易失去耐心而离去
反向代理和CPU都是依赖缓存。区别是,CDN是部署在网络供应商的机房,用户请求读取时,会从距离他最近的网络供应商机房
获取数据;而反向代理部署在网站的中心机房,所以用户请求服务式,会先访问反向代理服务器,如果它缓存着用户所请求的资源,就会直接把资源返回给用户。
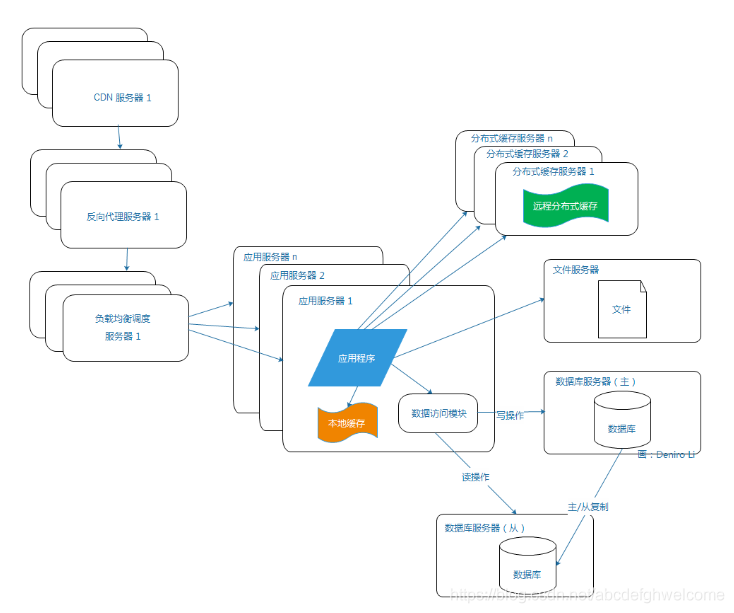
使用反向代理和CDN的目的都是为尽早地把数据返回用户,这样不仅加快用户的访问数据,而且也减轻了后端服务器的负载压力。
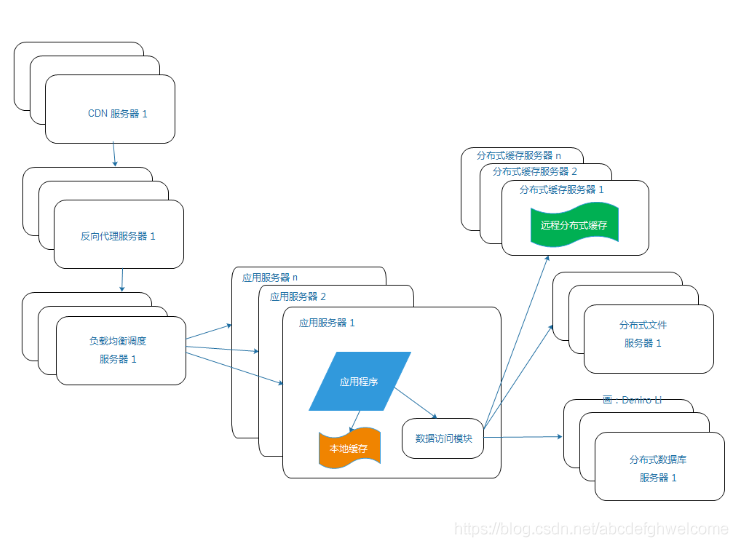
2.7使用分布式文件系统和分布式数据库系统
如果之前的架构仍然不能满足需求,那么就要使用分布式的文件系统和数据库系统。
注意:一般情况下是对业务数据进行分库,即将不同业务的数据库部署到不同的物理服务器上只用在单表的数据规模非常庞大,才使用分布式数据库。
2.8使用NoSQL和搜索引擎
随着业务变得越来越复杂,对数据存储和检索的需求也会变得复杂起来。就会用到NOSQL和搜索引擎啦
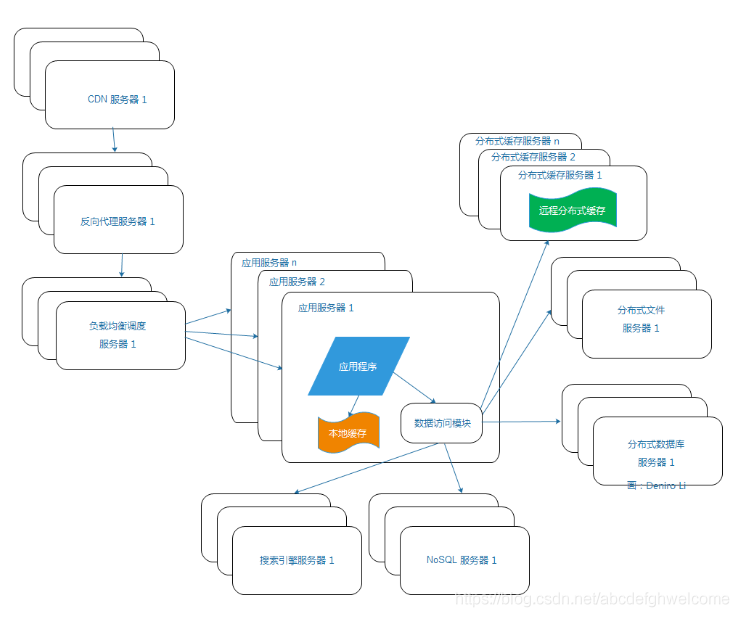
应用程序通过数据库访问模式来访问搜索引擎与NOSQL服务器,这样就可以减轻应用程序管理多数据源的麻烦
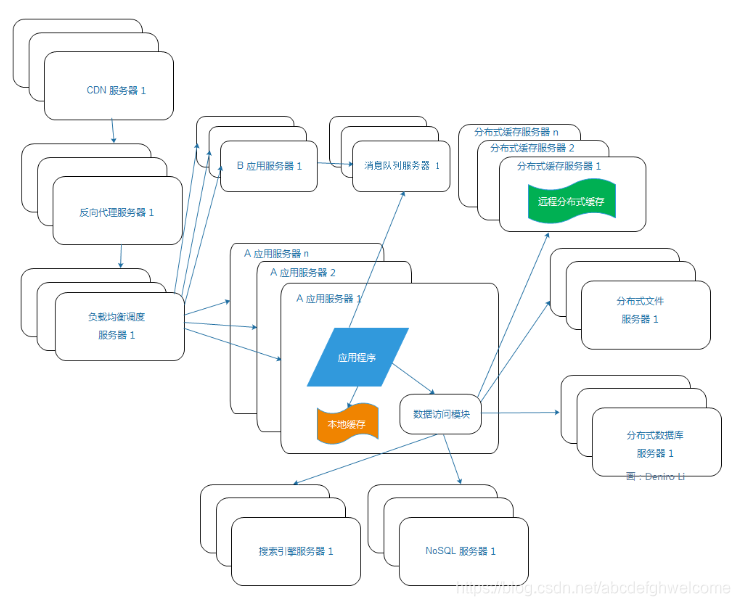
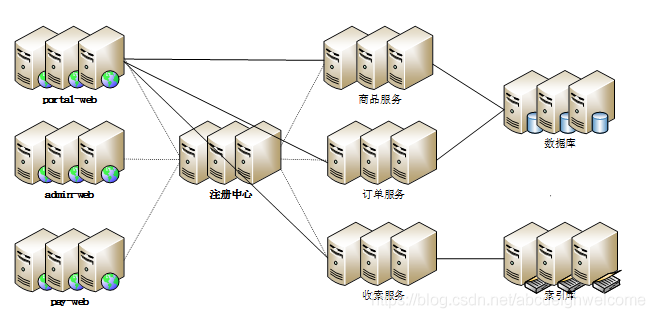
2.9业务拆分
为了应对日益复杂的业务场景,通常使用分而治之的手段,把业务划分为不同的产品线。
每个应对堵路部署维护,应用之间通过超链接建立关系,也可以通过消息队列进行数据分发,更通常的做法是通过访问同一个数据村塾系统来构建一个完整的关联关系。
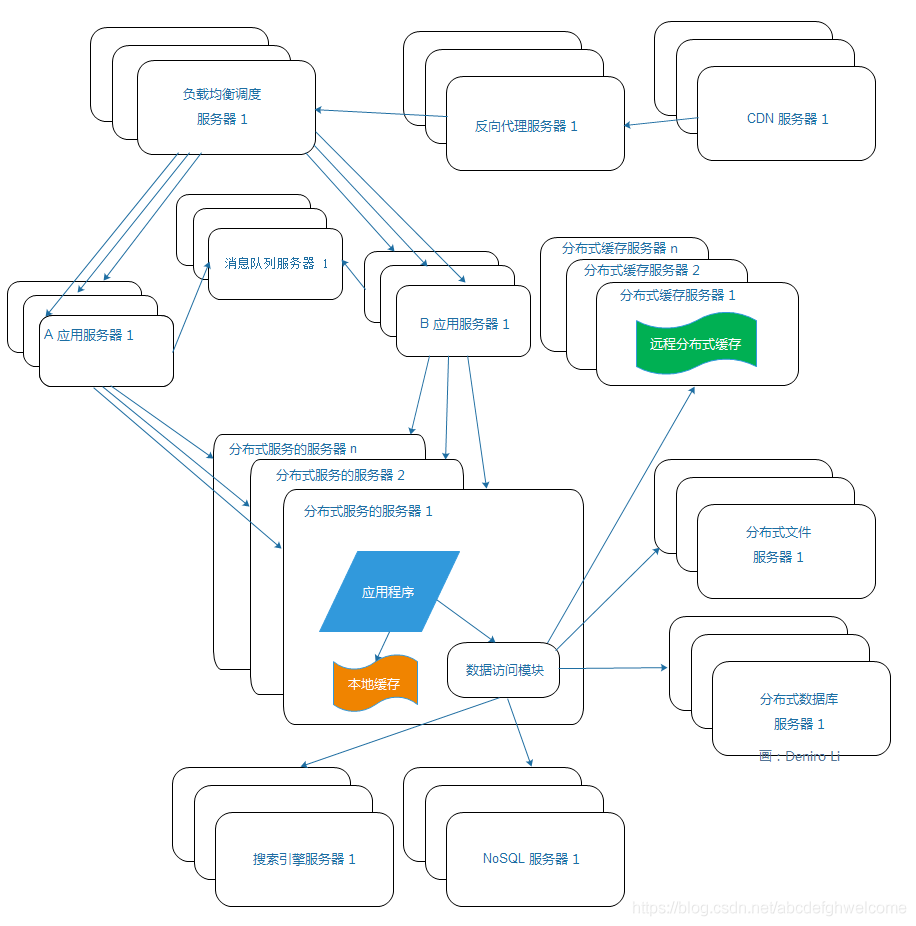
2.10分布式服务
随着业务被拆分的越来越小,存储系统变得越来越小,应用系统的整体复杂度成指数级增长,部署和维护变得越来越困难。
可以把一些公用的服务提取出来,独立部署而应用系统只需要管理用户界面,然后通过分布式服务调度公用的服务,来3完成业务操作。:
1.单节点架构(初级阶段)
2.集群架构
3.集群+分布式架构
转载作者:https://www.cnblogs.com/starzy/archive/2018/08/16/9485947.html