1.什么是mmu
MMU是Memory Management Unit的缩写,中文名是内存管理单元,它是中央处理器(CPU)中用来管理虚拟存储器、物理存储器的控制线路,同时也负责虚拟地址映射为物理地址,以及提供硬件机制的内存访问授权,多用户多进程操作系统。
物理地址:(英语:physical address),也叫实地址(real address)、二进制地址(binary address),它是在地址总线上,以电子形式存在的,使得数据总线可以访问主存的某个特定存储单元的内存地址。
虚拟地址:虚拟地址是相对于物理地址来说的。虚拟地址的提出,主要是为了解决在操作系统中,多线程内存地址重复,大进程在小内存运行等问题 , 在32位系统中,虚拟地址空间中有4G,在操作系统中程序中使用的都是虚拟地址
2.mmu有什么作用
简单的说,mm的作用有两点,地址翻译和内存保护。
在处理器上我们会运行一个操作系统,如linux,windows等,用户编写的源程序,需要经过编译,链接,生成可执行程序,人后被操作系统加载执行。在链接的时候同chan常我们要指定一个链接脚本,链接脚本的作用有很多,其中一个的作用是控制可执行文件的section的符号的内存布局,也就是控制ke'z可执行程序将来要在内存中哪里放置。操作系统会按照可执行程序的要求将其加载到内存的对应地址执行。假如用户A编写的应用程序的链接地址范围是0x100-0x200,用户B编写的应用程序的链接地址范围是0x100-0x200,这是很有可能的。因为给操作系统提供应用程序的开发者很多,不可能为每个开发者限定使用那些内存。这样,执行程序A的时候就不能执行程序B,执行程序B的时候就不能执行程序A,因为它们执行时会覆盖对方内存中的程序。为了解决这个问题,必须引入虚拟地址,为此操作系统和处理器都做了处理,添加了mmu,让其进行地址翻译。在程序载入内存的时候,操作系统会为其建立地址翻译表,处理器执行不同应用程序的时候,使用不同的地址翻译表。如下图所示。
ProgramA被加载到物理地址地址0x500-0x600处,ProgramB被加载到物理地址0x700-0x800处,同时建立了各自的地址翻译表,当处理器要执行ProgramB时,会使用ProgramB对应的地址翻译表,比如读取ProgramB地址0x100处的指令,那么经过地址翻译表可知0x100对应实际内存的0x700处,所以实际读取的就是0x700处的指令。同样的,当处理器要执行ProgramA时,会使用ProgramA对应的地址翻译表,这样就避免了之前提到的内存冲突问题,有了MMU的支持,操作系统就可以轻松实现多任务了。
上图CPU给出的地址称之为虚拟地址,经过MMU翻译后的地址称之为物理地址。
MMU的地址翻译功能还可以为用户提供比实际大得多的内存空间。用户在编写程序的时候并不知道运行该程序的计算机内存大小,如果在链接的时候指定程序被加载到地址Addr处,而运行该程序的计算机内存小于Addr,那么程序就无法执行,有了MMU后,程序员就不用关心实际内存大小,可以认为内存大小就是“2^指令地址宽度”。MMU会将超过实际内存的虚拟地址翻译为物理地址进行访问。
地址翻译表存储在内存中,如果采用图10.1中的方式:地址翻译表的表项是一个虚拟地址对应一个物理地址,那么会占用太多的内存空间,为此,需要修改翻译方式,常用的有三种:页式、段式、段页式,这也是三种不同的内存管理方式。
页式内存管理将虚拟内存、物理内存空间划分为大小固定的块,每一块称之为一页,以页为单位来分配、管理、保护内存。此时MMU中的地址翻译表称为页表(Page Table),每个任务或进程对应一个页表,页表由若干个页表项(PTE:Page Table Entry)组成,每个页表项对应一个虚页,内含有关地址翻译的信息和一些控制信息。在页式内存管理方式中地址由页号和页内位移两部分组成,其地址翻译方式如图10.2所示。

使用虚拟地址中的虚页号查询页表得到对应的物理页号,然后与虚拟地址中的页内位移组成物理地址。比如:页大小是256字节,虚拟地址是0x104,可知对应的虚页号是0x1,页内位移是0x4,假如通过页表翻译得到的对应物理页号是0x7,那么0x104对应的物理地址就是0x704。使用页表方式进行地址翻译可以有效减少地址翻译表占用的内存空间,还是以图10.1为例,页大小是256字节,此时每个程序对应的页表就只有两项,如图10.3所示。
段式内存管理将虚拟内存、物理内存空间划分为段进行管理,段的大小取决于程序的逻辑结构,可长可短,一般将一个具有共同属性的程序代码和数据定义在一个段中。每个任务和进程对应一个段表(Section Table),段表由若干个段表项(STE:Section Table Entry)组成,内含地址映像信息(段基址和段长度)等内容。在段式虚拟存储器中,地址分为段号、段内位移两部分,使用段表进行地址翻译的过程与使用页表进行地址翻译的过程是相似的。
段页式内存管理是在内存分段的基础上再分页,即每段分成若干个固定大小的页。每个任务或进程对应有一个段表,每段对应有自己的页表。在访问存储器时,由CPU经页表对段内存储单元进行寻址。
2、内存保护
内存保护也叫权限管理,除了具有地址翻译的功能外,还提供了内存保护功能。采用页式内存管理时可以提供页粒度级别的保护,允许对单一内存页设置某一类用户的读、写、执行权限,比如:一个页中存储代码,并且该代码不允许在用户模式下执行,那么可以设置该页的保护属性,这样当处理器在用户模式下要求执行该页的代码时,MMU会检测到并触发异常,从而实现对代码的保护。特别是在处理应用程序时,如果一个应用程序写的比较烂,出现了指针越界或栈溢出,程序跑飞等情况,因为不能访问别的程序的地址,所以不会影响到别的应用程序的运行。比如在操作系统下,应用程序不能访问寄存器,而操作系统可以。比如应用程序的只读数据段不能被写,否则会发生段错误。
3、大容量app在小资源系统运行
在嵌入式系统中,假如内存容量只有256M大,而应用程序却有1G大时,通常一个程序中,程序执行的比较多的是顺序指令,所以在运行1G的程序时,操作系统会先加载一小部分到内存中,当执行完这一部分或发生跳转发现内存中没有要跳转地址的指令时,操作系统再加载需要跳转部分的程序到其链接地址(虚拟地址),加载完后再继续执行。内次加载程序,都需要建立一个动态的地址映射表。当物理内存加载满后,操作系统会选择性的将最早之前加载入物理内存的程序置换到外部flash等存储器中,再加载需要用到的一块程序。因为置换需要时间,所以当使用存储容量较小内存的嵌入式系统后,让其运行大程序,使用可能会有一定的卡顿现象。
3.arm的mmu
下图中是arm支持的几种页表大小一级每种页表可以管理的内存单元数量。

通常使用段式页表作为一级页表,使用页式式页表作为二级页表。
在关闭了子页(subpages)功能后可以使用下面三种作为一级页表。
下图分别是超级段,和段以及粗页表的描述。
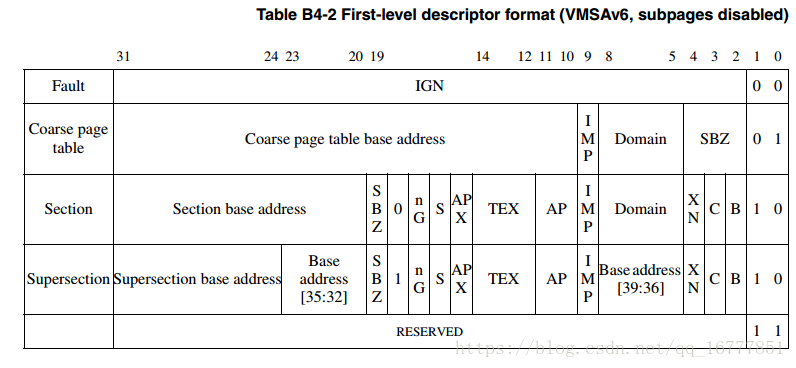
粗页以1k为单位管理页表,段以1M为单位管理页表,超级短以16M为单位管理页表。
上面三者都可以作为一级页表使用。
从上图我们可以看到,超级页表可以管理40位数据宽度也就是1T容量的内存。主要是为64位系统而发明的。
结合上下图的描述我们可以看到,supersection和section是通过bit18来区分的。
段和页的区分是有bit【0,1】来区分的。
1.下面是超级段和段的区别。

在使能子页(subpages)功能后,可以使用下面二种作为一级页表。

在说明一级页表转换之前我们先引入一个概念。
首先,我们要分清ARM CPU上的三个地址:虚拟地址(VA,Virtual Address)、变换后的虚拟地址(MVA,Modified Virtual Address)、物理地址(PA,Physical Address)
启动MMU后,CPU核对外发出虚拟地址VA,VA被转换为MVA供MMU使用,在这里MVA被转换为PA;最后通过PA读写实际设备
MMU的作用就是负责虚拟地址(virtual address)转化成物理地址(physical address)。 32位的CPU的虚拟地址空间达到4GB,在一级页表中使用4096个描述符来表示这4GB的空间,每个描述符代表1M的虚拟地址,要么存储了它的对应物理地址的起始地址,要么存储了下一级页表的地址。使用MVA[31:20]来索引一级页表(4096个描述符)(因为用MVA的高12位来索引,因此大小为 2^12 = 4096)
由协处理器CP15中的寄存器C2(高18位,即[31:14]为转换表基地址,低14位为0)用来存放一级转换表基地址,指向2^14=16KB整除的存储器即16K对齐,这个存储区称为一级转换表;MVA的高12位,即位[31:20]作为一级转换表的地址索引,因此一级转换表具有2^12=4096项,每一项的地址为32位,最高的18位[31:14]为寄存器C2的高18位,中间12位为MVA的高12位[31:20],最低2位为0b00。每一项的内容称为一个描述符,在段(Section)下,一级描述符的高12位为大小为1MB的段基地址,段内地址(偏移地址)为MVA的低20位,即段内每个存储器的地址是这样组成:高12位为一级描述符的高12位,低20位MVA的低20位。这样,借助于寄存器C2和一级描述符,将一个MVA转换成一个PA。(在这里一定要注意:MVA的高12位是用来索引4096个项的,然后使用项的内容(即描述符)的高12位为段的高12位,类似于指针里面存放地址,4096项类似指针,描述符类似指针里面的内容)
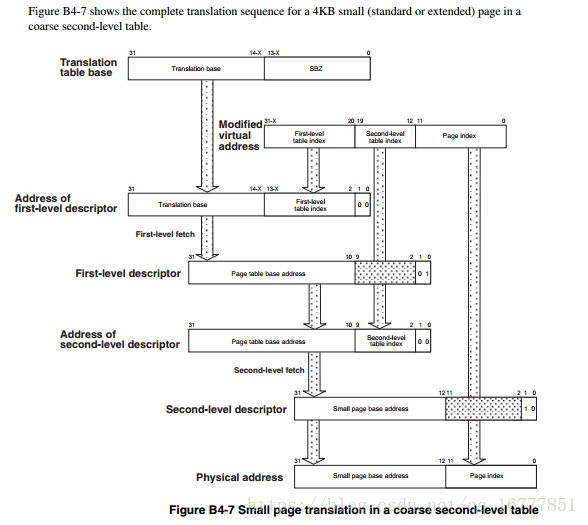
下图是使用一级页表后,地址的转换过程图。(以段式页表为例)
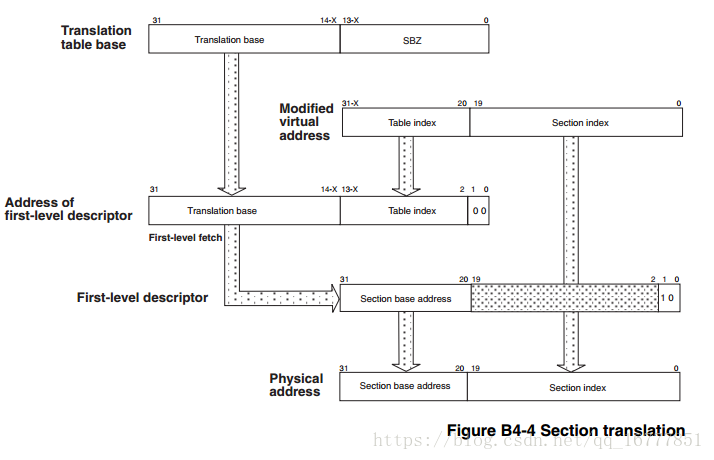
从上往下看:
translation tabe base:简称ttb,称为转换表基址,存放在cp15的c2寄存器的高18位,低12位为0。所以将来我们写程序存放ttb的基地址一定要以16kb对齐。
modified virtual address:简称mva,称为转换后的虚拟地址(即在32bit系统中具有4G访问空间的虚拟地址),它的高12bit总共4096个项,用来作为该虚拟地址在ttb中的索引。它的低20位,是作为将来找到对应的物理内存的偏移。其本省也是在虚拟内存中的偏移。
address of first-level descriptor:一级地址描述符,它是结合ttb,以及偏移量mva,找到的具体的页表。即具体段(section)在那个位置。
first-level descriptor:以及页表描述符,上一步既然知道了是存放在一级页表的哪个位置了,直接取出其中的高12位,即找到了物理地址所在的段。
physcical address:既然上一步已经找到了物理地址所在的段,那么只需要加上低20位的段内偏移即找到了具体的那个物理地址了。(偏移在物理地址和虚拟地址中是一样的,区别只是在段地址)
2.粗页表

一级页表做粗页表用的比较少,这里就不分析了
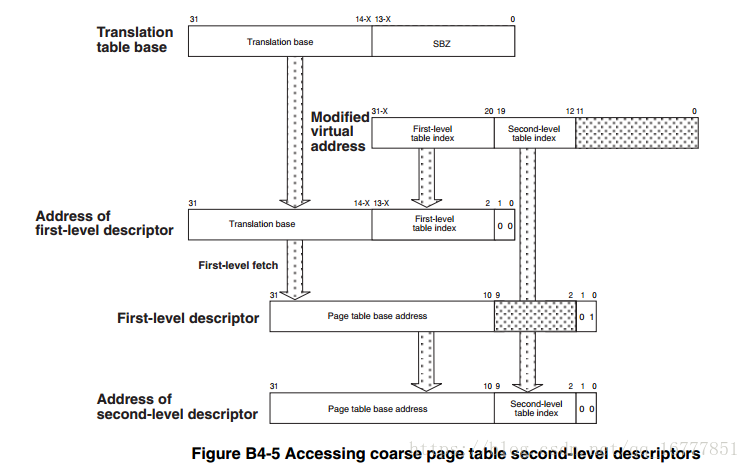
3.二级页表
二级页表主要有两种
大页表,每页管理64k
小页表,每页管理4k

和一级页表一样,使能或不使能subpages分为两种情况
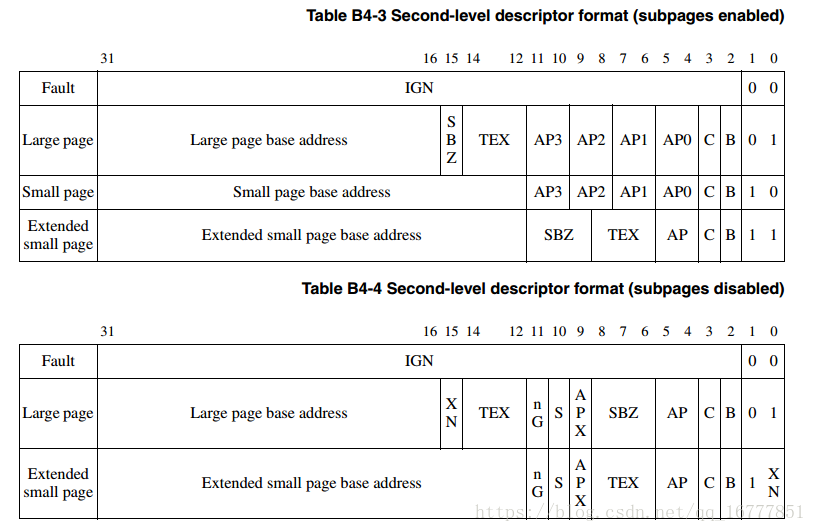
前面包括一级页表都没有说,页表没一项的内容,这里统一说明一下。

[0-1]用来识别页表类型,比如段式,大页,小页等
[2-3]用来识别是否使能cache和write buffer

TEX是扩展的类型字段。

[4-5]是用来做权限管理的
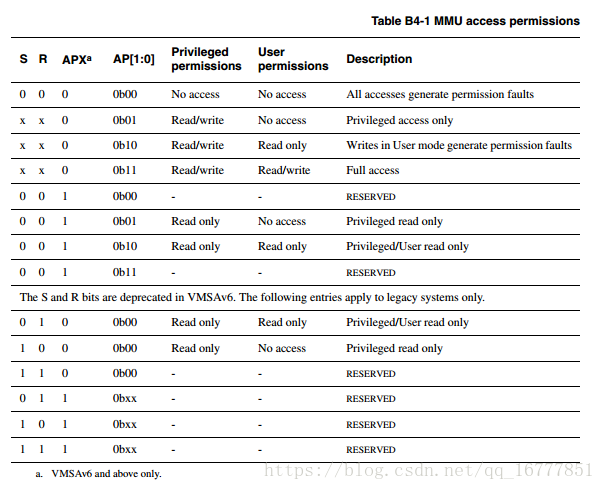
其中S R是在cp15的c1协处理器中,用来做系统保护和rom保护的。

nG S XN

其余的就是不同大小的页的基地址。
以64KB管理的二级粗页表的映射形式。

以4KB管理的二级粗页表的映射形式。
4.编程实践
下面使用上面讲的最详细的段页表为例,在裸机的情况下开启MMU,实现虚拟地址映射。
在现代处理器中,为了使内存的速度跟得上CPU的速度,通常在芯片内部做了缓存(cache)。在启动了cache后,程序的运行效率会极大的提高。
arm中又把cache分为指令cache,又称(icache),和数据cache,又称(dcache)。
其中icache可以随时开启,随时关闭,但dcache必须在开启了MMU后,才能启动。
在启动cache后,arm其实才可以称为哈佛结构(数据指令分开)
否则,在不开启的情况下,其实还是冯洛伊曼结构。
我的ddr的地址范围是0x3000000~0x4fffffff
为了验证我的MMU确实开启了,所以把程序的链接地址改为了0xB0000000,同时把0xB0000000起始的1M空间(我的裸机程序很小,远小于1M)映射到了0x30000000
首先看一下我的链接脚本
SECTIONS
{
. = 0xb0000000;
__code_start = .;
. = ALIGN(4);
.text :
{
start.o
*(.text)
}
. = ALIGN(4);
.rodata :
{
*(.rodata)
}
. = ALIGN(4);
.data :
{
data_load_add = LOADADDR(.data);
data_start = .;
*(.data)
data_end = .;
}
. = ALIGN(4);
.bss :
{
bss_start = .;
*(.bss) *(.COMMON)
bss_end = .;
}
}
接下来是页表的建立。
因为我在裸机中并没有使用很多东西,所以映射的不是所有4G空间,只映射了我用到的。
#define MMU_SECTION_AP (0x3<<10)
#define MMU_SECTION_DOMAIN (0<<5)
#define MMU_SECTION_NCNB (0<<2)
#define MMU_SECTION_ECEB (0x3<<2)
#define MMU_SECTION_TYPE ((1<<4)|(1<<1))
#define MMU_SECTION_IO (MMU_SECTION_AP|MMU_SECTION_DOMAIN|MMU_SECTION_NCNB|MMU_SECTION_TYPE)
#define MMU_SECTION_MEM (MMU_SECTION_AP|MMU_SECTION_DOMAIN|MMU_SECTION_ECEB|MMU_SECTION_TYPE)
#define MMU_IO 1
#define MMU_MEM 0
/* 虚拟地址向物理地址映射 */
static void create_tlb(unsigned int *ttb,unsigned int va,unsigned int pa, int io)
{
int index;
index = va / 0x100000;
if(io)
ttb[index] = (pa & 0xfff00000) | MMU_SECTION_IO;
else
ttb[index] = (pa & 0xfff00000) | MMU_SECTION_MEM;
}
/* 创建一级页表
* VA PA CB
* 0 0 11
*
* 512M
* 0x30000000 0x30000000 11
* ......
* 0x4ff00000 0x4ff00000 11
*
* 0xd0000000 0xd0000000 11
*
* SFR
* 0xe0000000 0xe0000000 00
* ......
* 0xfff00000 0xfff00000 00
*
* framebuffer
* 0x40000000 0x40000000 00
*
* link address
* 0xb0000000 0x30000000 11
*/
/* 创建一个一级的段页表 */
void create_page_table(void)
{
/* 页表在哪 0x4f000000 16k对齐 */
unsigned int *ttb = (unsigned int *)0x4f000000;
unsigned int va,pa;
/* 1.irom */
create_tlb(ttb,0,0,MMU_MEM);
/* 2.sdram 512M*/
va = 0x30000000;
pa = 0x30000000;
for( va = 0x30000000; va < 0x4fffffff; va += 0x100000 )
{
create_tlb(ttb,va,pa, MMU_MEM);
pa += 0x100000;
}
/* 3.irom/iram */
create_tlb(ttb,0xd0000000,0xd0000000, MMU_MEM);
/* 4.sfr */
va = 0xe0000000;
pa = 0xe0000000;
for( va = 0xe0000000; va < 0xfff00000; va += 0x100000)
{
create_tlb(ttb,va,pa, MMU_IO);
pa += 0x100000;
}
/* 5.framebuffer */
create_tlb(ttb, 0x40000000,0x40000000, MMU_IO);
/* 6. link address */
create_tlb(ttb,0xb0000000,0x30000000, MMU_MEM);
}
下面是初始化部分(bootloader)
__reset_exception:
/* 开发板制锁*/
ldr r0, = 0xe010e81c
ldr r1, = 0x301
str r1, [r0]
/* 关闭看门狗 */
ldr r0, = 0xe2700000
mov r1, #0
str r1, [r0]
/* 下面有调用c函数设置SVC栈地址 */
ldr sp, = 0xd0037d80
/* 启动icache */
bl enable_icache
/* 设置时钟 */
bl init_clock
/* 初始化DDR */
bl sdram_init
/* 创建页表 */
bl create_page_table
/* 使能mmu */
bl enable_mmu
/* 代码重定位 */
bl copy2sdram
/* 清bss段 */
bl clear_bss
/* 从iram跳转到ddr */
ldr pc, = sdram
sdram:
bl uart0_init
/* 开irq中断 */
mrs r0, cpsr
bic r0, r0, #1<<7
msr cpsr, r0
ldr sp, = 0x45000000
/* 调用main函数 */
bl main
b .
enable_icache:
mrc p15, 0, r1, c1, c0, 0 @Read Control Regist
orr r1, r1,#(1<<12) @enable instructon cache
//bic r1, r1,#(1<<12)
mcr p15, 0, r1, c1, c0, 0
mov pc, lr
enable_mmu:
/* translation table base write cp5 */
ldr r1, = 0x4f000000
mrc p15, 0, r2, c2, c0, 0 @ Read Translation Table Base Register
orr r2, r2, r1
mcr p15, 0, r2, c2, c0, 0 @ Write Translation Table Base Register
/* set domain 0xffffffff */
ldr r0, = 0xffffffff
mcr p15, 0, r0, c3, c0, 0 @ Read Domain Access Control Register
/* enable i/d canche */
mrc p15, 0, r1, c1, c0, 0 @Read Control Regist
orr r1, r1,#(1<<12) @enable instructon cache
orr r1, r1,#(1<<2) @enable data cache
orr r1, r1,#(1<<0) @enable mmu
mcr p15, 0, r1, c1, c0, 0 @write Control Regist
mov pc, lr
初始化要注意的点:
1.sdram标号之前的代码都应该是位置无关码(不能使用全局变量,静态变量,字符串,初始化过的局部数组等)。
2.因为页表放置在ddr中,所以创建页表必须在ddr初始化之后。
3.因为我的链接地址在0xB0000000,所以代码重定位时必须要能使用0xB0000000的空间。所以我把启动mmu放在了,重定位前面。同时开启MMU时要使用页表基地址,所以页表也必须在开启MMUq前先建立。
5.效果
启动了MMU前,我的刷屏速度大概在每秒几帧。
开启了MMU和cache后,我的刷屏速度差不多可以达到每秒二十对帧。
有一点要说明的是,我把framebuffer的显存映射成MEM即可以使用cache和buffer后,刷新速度感觉比映射成IO速度快了一倍。
主要原因是因为我是一整屏的刷颜色,所以dcache很快就满了,然后硬件自动把整个dcache刷回内存。所以速度比直接访问的IO要快,当
每次只刷一小块部分,速度反而会比IO方式慢。