目前3.7版本的python不是很稳定,有些库还不支持,不太建议下载。
首先,登陆python官网 点击打开链接,选择对应的系统,如下图;
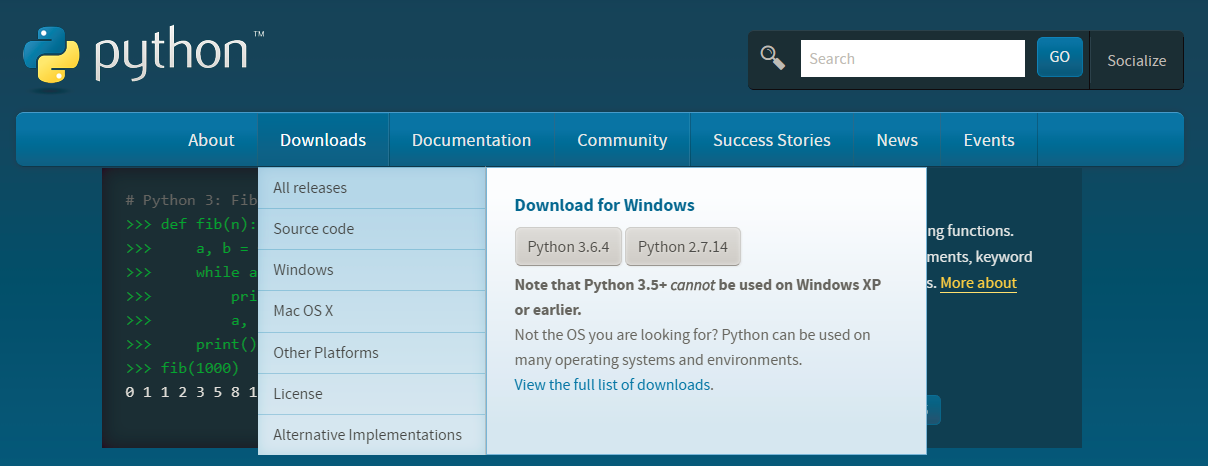
博主的系统为windows,选择windows。

根据自己的系统选择对应的安装包,这里解释一下不同安装包的区别:
x86是32位,x86-64是64位。
web-based installer 是需要通过联网完成安装的
executable installer 是可执行文件(*.exe)方式安装
embeddable zip file 嵌入式版本,可以集成到其它应用中。
下载完毕后点击运行,由于博主事先已经安装好,在这里以3.7版本的python作为例子。

注意勾选Add Python 3.7 to PATH,勾选后安装程序会自动添加环境变量。
安装好后,打开命令行,输入python,若出现下图,说明环境变量设置成功。

环境变量是否设置成功关系到我们能不能通过pip指令进行数据挖掘与机器学习库的安装。
这里解释一下数据挖掘与机器学习相关库的作用:
numpy:支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
gensim:自然语言处理库,可以自动的从文档中提取特征,语义信息等等。
matplotlib:用于数据可视化。
pandas:包含高级的数据结构。
scikit_learn(sklearn):用于机器学习和数据挖掘。
keras:用于深度学习。
scipy:包括统计,优化,整合,线性代数模块,傅里叶变换,信号和图像处理,常微分方程求解器等等。
安装上述库:1、可以在命令行下使用pip install+库名进行安装。2、可以登陆 点击打开链接 进行下载(注意系统号与python版本号),指令为pip install+下载存放的位置\库的全称。
方式一:

方式二:以numpy为例
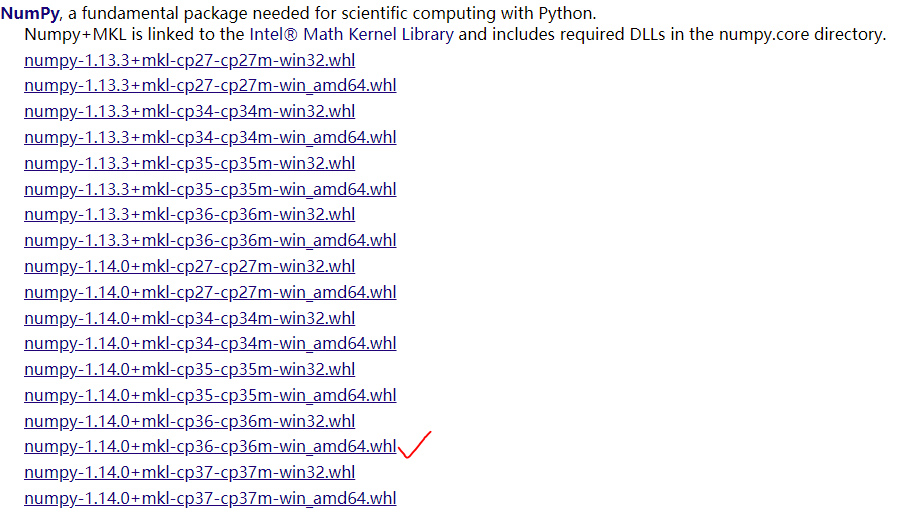
选择对应的版本,博主python为3.6版,系统为64位,故选择打勾的库。
编写python可以使用python自带的编译器
