(1)时间频度
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为T(n)。
(2)时间复杂度
在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。
但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。 一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示。
若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
T (n) = Ο(f (n)) 表示存在一个常数C,使得在当n趋于正无穷时总有 T (n) ≤ C * f(n)。简单来说,就是T(n)在n趋于正无穷时最大也就跟f(n)差不多大。也就是说当n趋于正无穷时T (n)的上界是C * f(n)。其虽然对f(n)没有规定,但是一般都是取尽可能简单的函数。例如,O(2n2+n +1) = O (3n2+n+3) = O (7n2 + n) = O ( n2 ) ,一般都只用O(n2)表示就可以了。注意到大O符号里隐藏着一个常数C,所以f(n)里一般不加系数。如果把T(n)当做一棵树,那么O(f(n))所表达的就是树干,只关心其中的主干,其他的细枝末节全都抛弃不管。
在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为O(1),另外,在时间频度不相同时,时间复杂度有可能相同,如T(n)=n2+3n+4与T(n)=4n2+2n+1它们的频度不同,但时间复杂度相同,都为O(n2)。 按数量级递增排列,常见的时间复杂度有:常数阶O(1),对数阶O(log2n),线性阶O(n), 线性对数阶O(nlog2n),平方阶O(n2),立方阶O(n3),..., k次方阶O(nk),指数阶O(2n)。随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低。
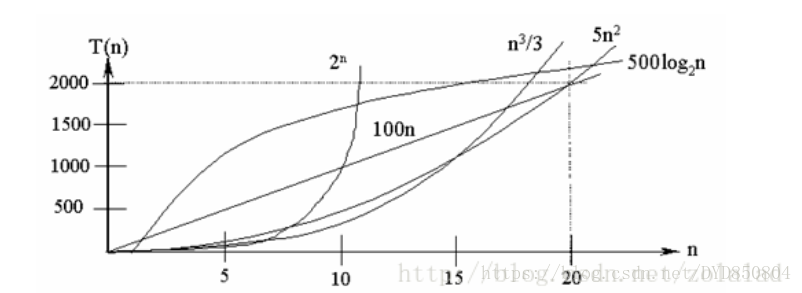
从图中可见,我们应该尽可能选用多项式阶O(nk)的算法,而不希望用指数阶的算法。
常见的算法时间复杂度由小到大依次为:Ο(1)<Ο(log2n)<Ο(n)<Ο(nlog2n)<Ο(n2)<Ο(n3)<…<Ο(2n)<Ο(n!)
(3)求解算法的时间复杂度的具体步骤是:
⑴ 找出算法中的基本语句;
算法中执行次数最多的那条语句就是基本语句,通常是最内层循环的循环体。
⑵ 计算基本语句的执行次数的数量级;
只需计算基本语句执行次数的数量级,这就意味着只要保证基本语句执行次数的函数中的最高次幂正确即可,可以忽略所有低次幂和最高次幂的系数。这样能够简化算法分析,并且使注意力集中在最重要的一点上:增长率。
⑶ 用大Ο记号表示算法的时间性能。
将基本语句执行次数的数量级放入大Ο记号中。
如果算法中包含嵌套的循环,则基本语句通常是最内层的循环体,如果算法中包含并列的循环,则将并列循环的时间复杂度相加。例如:
for (i=1; i<=n; i++)
x++;
for (i=1; i<=n; i++)
for (j=1; j<=n; j++)
x++;
第一个for循环的时间复杂度为Ο(n),第二个for循环的时间复杂度为Ο(n2),则整个算法的时间复杂度为Ο(n+n2)=Ο(n2)。
Ο(1)表示基本语句的执行次数是一个常数,一般来说,只要算法中不存在循环语句,其时间复杂度就是Ο(1)。其中Ο(log2n)、Ο(n)、 Ο(nlog2n)、Ο(n2)和Ο(n3)称为多项式时间,而Ο(2n)和Ο(n!)称为指数时间。计算机科学家普遍认为前者(即多项式时间复杂度的算法)是有效算法,把这类问题称为P(Polynomial,多项式)类问题,而把后者(即指数时间复杂度的算法)称为NP(Non-Deterministic Polynomial, 非确定多项式)问题。
(5)下面分别对几个常见的时间复杂度进行示例说明:
(1)、O(1)
Temp=i; i=j; j=temp;
以上三条单个语句的频度均为1,该程序段的执行时间是一个与问题规模n无关的常数。算法的时间复杂度为常数阶,记作T(n)=O(1)。注意:如果算法的执行时间不随着问题规模n的增加而增长,即使算法中有上千条语句,其执行时间也不过是一个较大的常数。此类算法的时间复杂度是O(1)。
(2)、O(n2)
2.1. 交换i和j的内容
sum=0; (1次)
for(i=1;i<=n;i++) (i增长到n后,还会执行i++一次,所以是n+1次)
for(j=1;j<=n;j++) (内层循环n次*外层循环n次==n^2次)
sum++; (与上一条语句“共生”==n^2次)
解:f(n)=n+1+2*n^2;
因为Θ(f(n))=n2(Θ即:去低阶项,去掉常数项,去掉高阶项的常参得到),所以T(n)= =O(n2);
2.2.
for (i=1;i<n;i++) //i增长到n的时候就不会执行i++了,所以是n-1次
{
y=y+1; //①
for (j=0;j<=(2*n);j++)
x++; //②
}
语句1的频度是n-1;
语句2的频度是(n-1)*(2n+1)=2n2-n-1
f(n)=2n2-n-1+(n-1)=2n2-2;
又Θ(2n2-2)=n2
该程序的时间复杂度T(n)=O(n2).
一般情况下,对步进循环语句只需考虑循环体中语句的执行次数,忽略该语句中步长加1、终值判别、控制转移等成分,当有若干个循环语句时,算法的时间复杂度是由嵌套层数最多的循环语句中最内层语句的频度f(n)决定的。
(3)、O(n)
a=0;
b=1; //①
for (i=1;i<=n;i++) //②
{
s=a+b; //③
b=a; //④
a=s; //⑤
}
语句2的频度: n+1,
语句3的频度: n,
语句4的频度:n,
语句5的频度:n,
f(n)=1+n+1+3n=4n+2;
O(f(n))=O(n);
(4)、O(log2n) i=1; ①
while (i<=n)
i=i*2; ② //若循环了n次,也就是这条语句被执行了n次,i的值就会变为2^n,此时必有i>n,即2^n>n,所以有n>log2n ,也就是O(log2n )问题
设语句2的频度是f(n), 则:2^f(n)<=n;f(n)<= log2n
取最大值f(n)= log2n ,
T(n)=O(log2n )
(5)、O(n3)
for(i=0;i<n;i++)
{
for(j=0;j<i;j++)
{
for(k=0;k<j;k++)
x=x+2;
}
}
解:当i=m, j=k的时候,内层循环的次数为k当i=m时, j 可以取 0,1,...,m-1 , 所以这里最内循环共进行了0+1+...+m-1=(m-1)m/2次所以,i从0取到n, 则循环共进行了: 0+(1-1)*1/2+...+(n-1)n/2=n(n+1)(n-1)/6所以时间复杂度为O(n3).
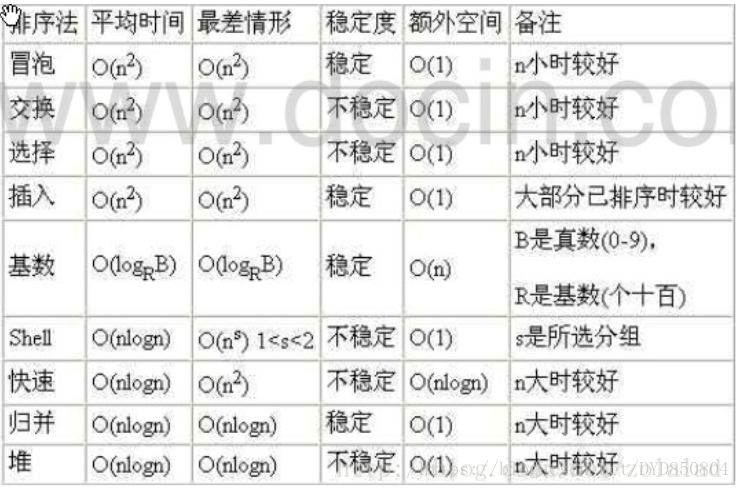
(5)常用的算法的时间复杂度和空间复杂度
本文大部分摘自:点击打开链接