传统方法系列:
一、流程
二、Selective Search
三、MSER
四、Slide Window
五、EdgeBox
深度学习方法系列:
一、R-CNN
1.思想:
首先提取一系列的候选区域,然后对这些候选区域用CNN提取固定长度的特征,然后用SVM对特征进行分类,最后对候选区域进行微调。
2.步骤:
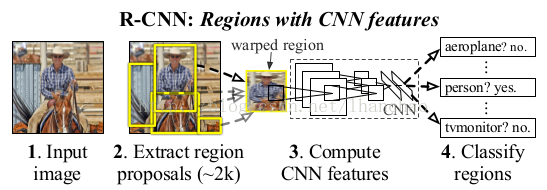
(1)使用Selective Search对输入图像提取大约2000个候选区域(proposal);
(2)对每个候选区域的图像进行拉伸形变,使之成为固定大小的图像(如227*227),并将该图像输入到CNN(Alexnet)中提取(4096维的)特征;(先在ImageNet上进行预训练再微调,IOU阈值为0.5,分类为21个channel(是不是目标,是哪类目标))
(3)使用线性的SVM对提取的特征进行分类(对每一类训练一个分类器);
(4)对proposal进行微调(在附录里面)。
(5)测试时,用NMS做后处理。(对IOU大于一定阈值(如0.5)的proposal对,去掉面积小的proposal)
3.缺点:
(1)输入需要固定尺寸;
(2)proposal的特征需要存储,占用大量存储空间;
(3)每个proposal单独提取特征,大量重叠,浪费计算资源。
4.参考:
https://blog.csdn.net/lhanchao/article/details/72287377;
https://www.cnblogs.com/gongxijun/p/7071509.html?utm_source=debugrun&utm_medium=referral
二、SPPNet
1.思想:
改进R-CNN,使得原图只需输入一次,并且不需要固定大小。思路是,首先提取Proposal,然后将整张图输入到神经网络中得到feature map,将proposal位置对应到feature map上,剪切下来再进行图像金字塔池化得到固定长度的特征,最后再用分类器进行分类。
2.步骤:
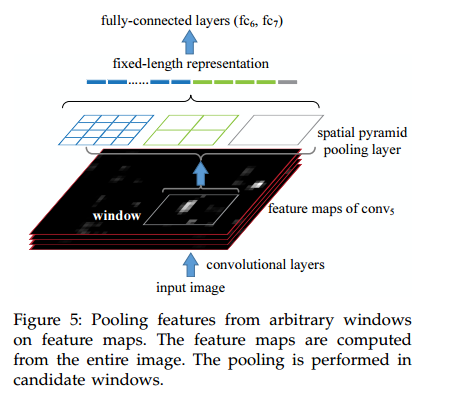
(1)使用Selective Search对输入图像提取大约2000个候选区域(proposal);
(2)将整张图像输入到神经网络(如ZF-5)中得到feature map,并对候选区域对应的feature map采用空间金字塔(4级,1*1,2*2,3*3,6*6共50块)池化得到固定大小(256个channel*50=12800维)的特征;(只有1*1时是全局平均池化)
(3)用多个二分类SVM进行分类;
(4)bounding box回归。
(5)测试时,NMS做后处理。
3.缺点:
(1)仍然基于RCNN框架,非端到端;
(2)提取proposal依然耗时;
(3)金字塔池化两端无法同时训练。
4.参考:
http://www.dengfanxin.cn/?p=403
三、Fast R-CNN
1.思想:
将SPP的空间金字塔池化思想引入到R-CNN,用softmax代替SVM分类器,同时将bounding box 回归纳入到整体框架中。
2.步骤:
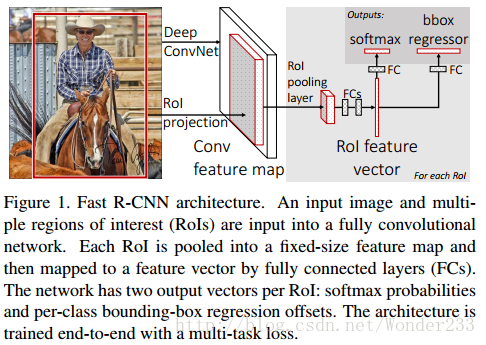
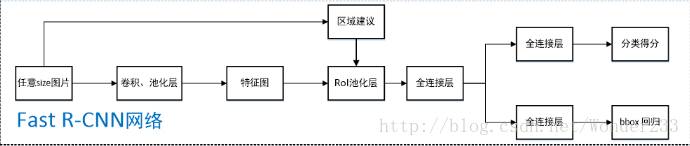
(1)对输入的图片利用Selective Search得到约2000个感兴趣区域,即ROI;
(2)将整张图输入到网络中得到feature map,并在feature map上求得每个ROI对应的区域;
(3)用ROI Pooling层得到固定长度的向量,然后经过两个全连接层得到ROI的特征向量;
(4)分别经过两个全连接层得到预测结果,一个用来分类是哪个目标,一个用来bbox回归。
(5)测试时,非极大值抑制得到最终结果。
3.细节:
ROI pooling:
是SppNet的图像金字塔池化的一种特例,只有一层。
4.Loss:
分类softmax loss+回归smooth L1 loss
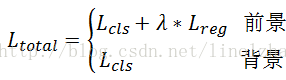
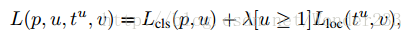
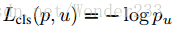
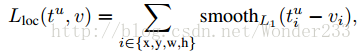
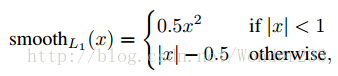
5.缺点:
(1)仍然是双阶段的;
6.参考:
https://blog.csdn.net/wonder233/article/details/53671018
四、Faster R-CNN
1.思想:
用RPN(区域生成网络)取代以往算法的区域生成阶段,然后交替训练,使得RPN和Fast RCNN共享参数。
2.步骤:
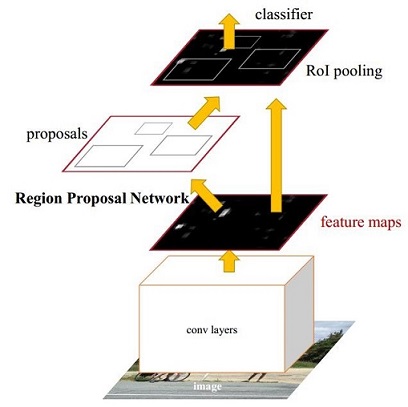

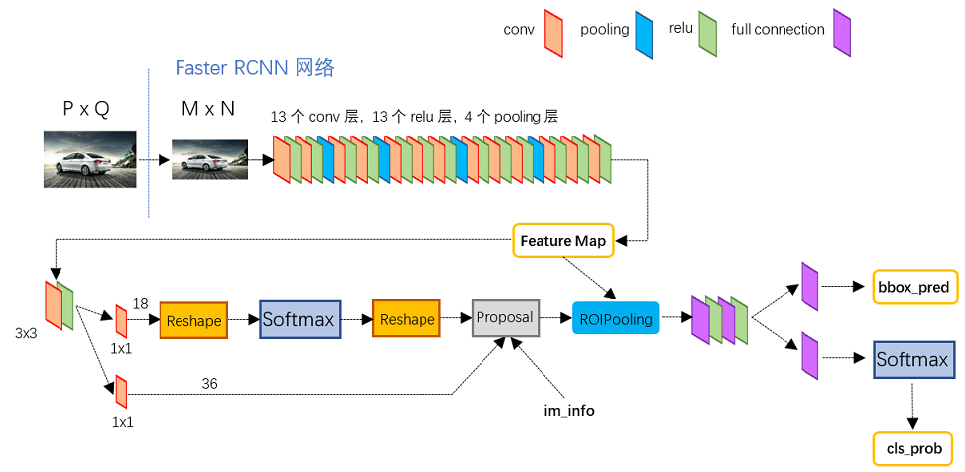
(1)用基础网络(VGG16)获得feature map;
(2)将feature map输入到RPN网络中,提取proposal,并将proposal映射到原feature上;
(3)将proposal的feature map用ROI pooling池化到固定长度;
(4)进行类别的分类和位置的回归。
3.细节:
RPN网络:

思想:在feature map的每个cell上赋予9=3(3种size)*3(3种比例,1:1,1:2,2:1)个anchor,每个anchor需要检测该cell是不是目标(9*2=18维),以及目标的更精确的位置(9*4=36维),整个feature map得到W/4*H/4*(18+36=54)大小的feature map,接着就可以按分数取正负样本,再从原feature map上裁出来然后ROI pooling,就得到待分类和回归的proposal。
bbox回归
将anchor映射回原图进行回归,回归之后去掉超出边界的Bbox,再用非极大值抑制,最后选择前TopN的anchor进行输出。
4.Loss:
RPN损失:分类损失(softmax)+λ回归损失(L1 smooth)
Fast RCNN损失:见上
5.参考:
http://www.360doc.com/content/17/0809/10/10408243_677742029.shtml
五、YOLO
六、SSD
七、R-FCN
八、EAST
九、RefineNet
十、Mask RCNN
十一、DSSD
十二、DCN