论文地址:
《2016 PAMI HyperFace: A Deep Multi-task Learning Framework for Face Detection, Landmark Localization, Pose Estimation, and Gender Recognition.
全文翻译有几处文意不同,后期慢慢进行修改。
只是大体把主要步骤描述了一遍。
由深度学习完成,将人脸检测,关键点定位,头部角度预测与性别识别相结合。
此算法用深度卷积神经网络完成(CNN:什么是卷积神经网络及其结构),此方法名称被称为Hyperface,期间融合中间层。
Hyperface的两个重要点:
1.Hyperface-ResNet基于ResNet-101模型,并在此基础上实现了很大提升
2.Fast-Hyperface针对截出的脸部区域,使用了一个很高的召回率脸部识别器,以此提高了算法速度
1.Introduction
同时使用四个任务进行预测估计,有助于提升单个任务效率。
浅层对边与角落的信息敏感,因此浅层有更好的关键点位置信息。
浅层处理,有助于学习关键点定位与头部角度预测任务。
深层更适合学习更复杂的任务,例如人脸识别与性别识别。
实现表明多任务学习比单任务学习效果要好,也要用好融合中间层。
两种后处理方法能有效提升识别效果:IRP与L-NMS
iterative region proposals 和 landmarks-based non-maximum suppression
深度学习网络与fusion-CNN结合相比其他的来说效果更好。
我们必须要用好深度神经网络的中间层,我们更倾向于在中间层设置hyperface的特征。
通过融合中间层,我们推出两种新的算法,Hyperface与HF-ResNet
2.Hyperface
Hyperface算法由三个模块组成:
1.生成裁剪区域框
用选择性搜索(什么是selective search)选出候选框,然后resize到227*227像素中:
2.用CNN判别该区域是否是脸部。如果是脸,那么进行另外三个判断
3.后处理阶段IPR与L-NMS,用来提高脸部检测分数与提升单个任务的性能。
2.1Hyperface的结构组成
采用Alexnet进行图像分类,每个输入图片都将被缩放成227*227大小,分rgb三个颜色维度输入。AlexNet一共8个层,包含前5个卷积层与后3个全连接层(什么是全连接层)。每一层所做的处理:请点击出查看。利用R-CNN_Face网络初始化模型
图像中卷积卷积地是什么意思呢,就是图像f(x),模板g(x),然后将模版g(x)在模版中移动,每到一个位置,就把f(x)与g(x)的定义域相交的元素进行乘积并且求和,得出新的图像一点,就是被卷积后的图像. 模版又称为卷积核.卷积核做一个矩阵的形状.
去除了三个全连接层,因为这三个全连接层对于头部姿态估计与关键点定位不能起到帮助。
算法对于以下两项进行了拓展,从而创建自己的网络:
(1)低层特征有助于进行关键点识别与头部姿态估计,高层有助于识别与分类
(2)我们通过融合中间层的特征,来达到四个任务的目标,但并不是把所有的中间层都融合。
我们使用分开的网络融合了AlexNet的最大层1(维度:27*27*96),卷积层3(13*13*384)与池化层5(6*6*256)(具体流程)。
他们有各自的维度,因此我们添加了卷积层conv1a与conv3a,分别添加到池化层pool1与卷积层conv3后,来获取持续的feature map(6*6*256)(什么是feature map)。我们之后连接池化层pool5来形成一个6*6*768维度的feature map。
我们用一个1*1的卷积核(什么是1*1卷积核),添加到(6*6*192)里面来进行降维。
我们对于CONVall添加一个全连接层(FCall,输出3072个特征向量)。
我们将网络分为5各分支对应5个1不同的任务,我们添加:

全连接层,到FCall中。
最后一个全连接层添加到最后,连接各自的五个任务。
最后我们再添加ReLU当做激活函数,同时我们不考虑池化层。
整个算法的流程如下图所示:

3.Training
使用AFLW人脸数据库进行训练,AFLW提供脸部的21个位置标记点。我们使用损失函数(loss function)进行评估。
脸部识别,使用R-CNN的Selective Search算法来找到脸部区域。利用IOU系数(Intersection over Union),如果IOU超过0.5,那么就认为是一个正样本(即人脸),低于0.35被认为是负样本(不是人脸),其他区域被忽略。
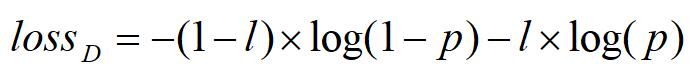
p是区域是否是人脸的概率。概率值从最后一层的全连接层中获取。
关键点定位:
我们利用AFLW提供的脸部21点位置信息来进行定位。AFLW的数据库提供了定位信息。如下图所示
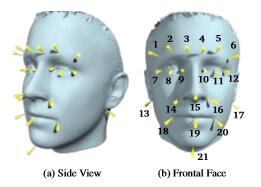
一个区域的特征有四个点信息{x,y,w,h},x,y是区域的位置,w,h是区域的宽度与高度。

上述公式,是利用可见因子(visbility factor)为衡量标准的使用欧几里得损失函数来训练关键点特征的任务。
ai,bi是训练的标签,xi,yi是真实的脸部坐标位置。xywh是人脸框。
计算预测关键点标记的损失函数如下所示:
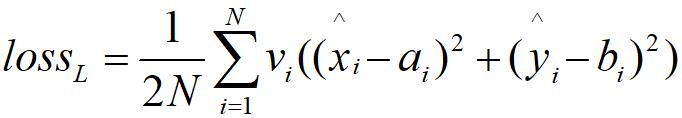
xi,yi是第i个被网络预测的关键点标记,N是关键点个数(在本文中,利用AFLW是21个),vi是可见因子,它只能是1或者0,当为1时,代表该关键点可见,0的时候代表关键点不可见。因为图像中会出现偏着头的情况,例如上图中关键点有可能没有全部被标注。
3.3Testing
我们使用selective search来选出区域,
在最后两步中,Hyperface加入了两步算法第一个是IPR,第二个是L-NMS(什么是NMS)。
IRP(iterative region proposals):
我们使用selective search的快速版本,从一张图片中抽取出两千个区域,我们将此版本成为FAST_SS.
网络可能因为低分数而没有检测到部分人脸。因此需要一个更加精准的检测器,我们由此发明了一个新的候选区域,这个候选区域来源于预测关键点,通过使用了FaceRectCalculator提供的预测关键点(AFLW人脸数据库提供21个人脸关键点)。
L-NMS:传统的NMS方法,是采用选取分数最高的区域,并抛掉分数超过阈值的区域,去除冗杂区域,如下图所示。

传统方法有两个缺点:
1.如果对于一张相同的脸来说,该区域有着最高的分数,较少的重复度,那么有可能被认为是一个单独分开的人脸。
2.最高得分的区域,可能不是每次都精准的定位到人脸上,如果两张脸靠的很近,可能会有矛盾。
为了克服这些困难,我们提出了新的算法L-NMS。
我们在一个新的区域上,边界为
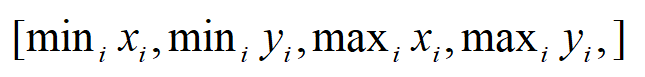
其算法步骤为:

- 获取检测区域
- 获取检测区域区域的基准值
- 精准区域的坐标位置,获取上述1的四个值
- 从与区域重叠中提取人脸
- 对每张人脸进行迭代
- 获取最高值的前K个区域
- 中和前K个区域的值
- 确定最终的姿态(根据前K个)
- 获取最终性别
- 获取最终可见度
- 获取最终的区域
- 算法结束