最近对python很感兴趣 看着人家的代码爬了网页的图片
其中类似正则表达式的都还没有学习
还有 python 2 跟 python 3 差别真的蛮大的 本来是python2 的代码 一点一点改成 python3
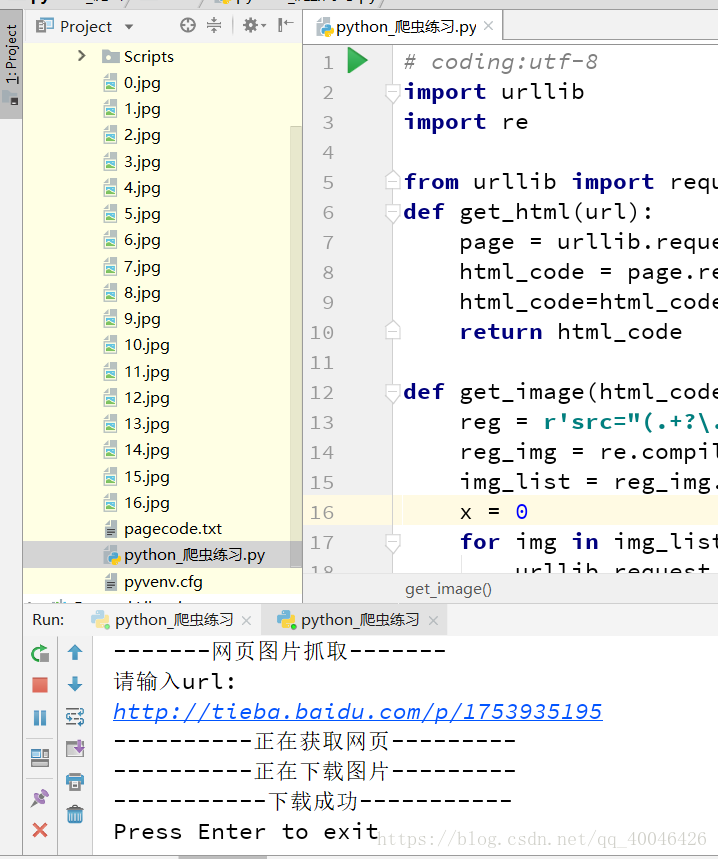
# coding:utf-8
import urllib
import re
from urllib import request
def get_html(url):
page = urllib.request.urlopen(url)//打开网页
html_code = page.read()//读取网页源码
html_code=html_code.decode('utf-8')//转换格式
return html_code//返回网页源码
def get_image(html_code):
reg = r'src="(.+?\.jpg)" width'//正则表达式
reg_img = re.compile(reg)//关于正则表达式的 还不太懂
img_list = reg_img.findall(html_code)//找标签 找图片
x = 0
for img in img_list:
urllib.request.urlretrieve(img, '%s.jpg' % x)
x += 1
print (u'-------网页图片抓取-------')
print (u'请输入url:',)
url = input()//输入网址
if url:
pass
else:
print (u'---没有地址输入正在使用默认地址---')
url = 'http://tieba.baidu.com/p/1753935195'
print (u'----------正在获取网页---------')
html_code = get_html(url)
print (u'----------正在下载图片---------')
get_image(html_code)
print (u'-----------下载成功-----------')
input('Press Enter to exit')
开心。。。。晚安 明天继续学。