来源《零基础入门 深度学习 (5) - 循环神经网络》
全连接神经网络和卷积神经网络,他们都只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的(这个是从某一层来看)。 但是,某些任务需要能够更好的处理序列的信息, 即前面的输入和后面的输入是有关系的。 比如, 当我们在理解一句话意思时, 孤立的理解这句话的每个词是不够的, 我们需要处理这些词连接起来的整个序列 ; 当我们处理视频的时候, 我们也不能只单独的去分析每一帧, 而要分析这些帧连接起来的整个序列 。 这时, 就需要用到深度学习领域中另一类非常重要神经网络: 循环神 经网络(Recurrent Neural Network) 。 RNN种类很多, 也比较绕脑子。 不过读者不用担心, 本文将一如既往的对复杂的东西剥茧抽丝, 帮助您理解RNNs以及它的训练算法, 并动手实现一个循环神经网络。
1、语言模型
RNN是在自然语言处理领域中最先被用起来的,比如,RNN可以为语言模型来建模。 那么 ,什么是语言模型呢?
我们可以和电脑玩一个游戏,我们写出一个句子前面的一些词,然后,让电脑帮我们写下接下来的一个词。 比如下面这句:
我昨天上学迟到了 , 老师批评了 ____。我们给电脑展示了这句话前面这些词, 然后, 让电脑写下接下来的一个词。 在这个例子中, 接下来的这个词最有可能是『 我』 , 而不太可能
是『 小明』 , 甚至是『 吃饭』 。
语言模型就是这样的东西:给定一个一句话前面的部分,预测接下来最有可能的一个词是什么 。
语言模型是对一种语言的特征进行建模,它有很多很多用处。 比如在语音转文本(STT) 的应用中,声学模型输出的结果, 往往是若干个可能的候选词, 这时候就需要语言模型来从这些候选词中选择一个最可能的。 当然,它同样也可以用在图像到文本的识别中(OCR) 。
使用RNN之前, 语言模型主要是采用N-Gram。 N可以是一个自然数, 比如2或者3。 它的含义是,假设一个词出现的概率只与前面N个词相关。 我们以2-Gram为例。 首先, 对前面的一句话进行切词:
我 昨天 上学 迟到 了 , 老师 批评 了 ____。如果用2-Gram进行建模, 那么电脑在预测的时候, 只会看到前面的『 了 』 , 然后,电脑会在语料库中, 搜索『 了 』 后面最可能的一个词。 不管最后电脑选的是不是『 我』,我们都知道这个模型是不靠谱的, 因为『 了 』 前面说了 那么一大堆实际上是没有用到的。 如果是3-Gram模型呢, 会搜索『 批评了 』 后面最可能的词, 感觉上比2-Gram靠谱了 不少, 但还是远远不够的。 因为这句话最关键的信息『 我』 , 远在9个词之前!
现在读者可能会想, 可以提升继续提升N的值呀, 比如4-Gram、 5-Gram… … . 。 实际上, 这个想法是没有实用性的。 因为我们想处理任意长度的句子, N设为多少都不合适; 另外, 模型的大小和N的关系是指数级的, 4-Gram模型就会占用海量的存储空间。
所以, 该轮到RNN出场了 , RNN理论上可以往前看(往后看) 任意多个词。
2、循环神经网络是啥
循环神经网络种类繁多, 我们先从最简单的基本循环神经网络开始吧。
基本循环神经网络
下图是一个简单的循环神经网络, 它由输入层、 一个隐藏层和一个输出层组成:

纳尼? ! 相信第一次看到这个玩意的读者内心和我一样是崩溃的。 因为循环神 经网络实在是太难画出来了 , 网上所有大神们都不得不用了这种抽象艺术手法。 不过, 静下心来仔细看看的话, 其实也是很好理解的。 如果把上面有W的那个带箭头的圈去掉, 它就变成了最普通的全连接神经网络。 x是一个向量,它表示输入层的值(这里面没有画出来表示神经元节点的圆圈) ; s是一个向量, 它表示隐藏层的值(这里隐藏层面画了一个节点, 你也可以想象这一层其实是多个节点, 节点数与向量s的维度相同) ; U是输入层到隐藏层的权重矩阵(读者可以回到第三篇文章零基础入门深度学习 (3) - 神经网络和反向传播算法,看看我们是怎样用矩阵来表示全连接神经网络的计算的);o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。那么 ,现在我们来看看W是什么。 循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x, 还取决于上一次隐藏层的值s。 权重矩阵W就是隐藏层上一次的值作为这一次的输入的权重。如果我们把上面的图展开, 循环神经网络也可以画成下面这个样子:

现在看上去就比较清楚了,这个网络在
时刻接收到输入
之后,隐藏层的值是
,输出值是
。关键一点是,
的值不仅仅取决于
,还取决于
。我们可以用下面的公式来表示循环神经网络的计算方法:
式1是隐藏层的计算公式,它是循环层。 U是输入x的权重矩阵, W是上一次的值作为这一次的输入的权重矩阵, f是激活函数。式2是输出层的计算公式,输出层是一个全连接层,也就是它的每个节点都和隐藏层的每个节点相连。 V是输出层的权重矩阵,g是激活函数。
从上面的公式我们可以看出, 循环层和全连接层的区别就是循环层多了一个权重矩阵 W。
如果反复把式2带入到式1 ,我们将得到:
从上面可以看出, 循环神 经网络的输出值 ,是受前面历次输入值 影响的, 这就是为什么循环神经网络可以往前看任意多个输入值的原因。
3、双向循环神经网络
对于语言 模型来说, 很多时候光看前面的词是不够的,比如下面这句话:
我的手机坏了 , 我打算____一部新手机。可以想象, 如果我们只看横线前面的词, 手机坏了 ,那么 我是打算修一修? 换一部新的?还是大哭一场?这些都是无法确定的。但如果我们也看到了横线后面的词是『 一部新手机』 ,那么 ,横线上的词填『 买』 的概率就大得多了 。
在上一小节中的基本循环神 经网 络是无法对此进行建模的, 因此,我们需要双向循环神 经网络,如下图所示:

当遇到这种从未来穿越回来的场景时,难免处于懵逼的状态。 不过我们还是可以用屡试不爽的老办法: 先分析一个特殊场景, 然后再总结一般规律。 我们先考虑上图中,
的计算。
从上图可以看出, 双向卷积神经网络的隐藏层要保存两个值, 一个A参与正向计算, 另一个值A’参与反向计算。最终的输出值
取决于
和
。 其计算方法为:
现在,我们已经可以看出一般的规律: 正向计算时, 隐藏层的值 与 有关; 反向计算时, 隐藏层的值 与 有关; 最终的输出取决于正向和反向计算的加和 。现在,我们仿照式1 和式2,写出双向循环神经网络的计算方法:
从上面三个公式我们可以看到,正向计算和反向计算不共享权重,也就是说U和U’ 、W和W’ 、V和V’ 都是不同的权重矩阵。
4、深度循环神经网络
前面我们介绍的循环神经网络只有一个隐藏层,我们当然也可以堆叠两个以上的隐藏层,这样就得到了深度循环神经网络。如下图所示:

我们把第i个隐藏层的值表示为
、
, 则深度循环神经网络的计算方式可以表示为:
5、循环神经网络的训练
循环神经网络的训练算法: BPTT(Back Propagation Trough Time基于时间的反向传播算法)
BPTT算法是针对循环层的训练算法, 它的基本原理和BP算法是一样的, 也包含同样的三个步骤:
- 1、前向计算每个神经元的输出值;
- 2、反向计算每个神经元的误差项 值,它是误差函数 对神经元 的加权输入 的偏导数;
- 3、计算每个权重的梯度。
最后再用随机梯度下 降算法更新权重。
5.1、前向计算
使用前面的式2对循环层进行前向计算:
注意, 上面的 都是向量, 用黑 体字母表示;而U、V是矩阵,用大写字母表示。 向量的下标表示时刻, 例如, 表示在t时刻向量s的值。
我们假设输入向量x的维度是m,输出向量s的维度是n,则矩阵U的维度是 ,矩阵W的维度是 。下面是上式展开成矩阵的样子, 看起来更直观一些:
在这里我们用手写体字母表示向量的一个元素,它的下标表示它是这个向量的第几个元素,它的上标表示第几个时刻 。例如, 表示向量 的第j个元素在t时刻的值。 表示输入层第i个神经元到循环层第j个神经元的权重。 表示循环层第t-1时刻的第i个神经元到循环层第t个时刻的第j个神经元的权重。
误差项的计算
BPTT算法将第 层 时刻的误差项 值沿两个方向传播, 一个方向是其传递到上一层网络,得到 , 这部分只和权重矩阵U有关; 另一个是方向是将其沿时间线传递到初始 时刻,得到 , 这部分只和权重矩阵W有关。
我们用向量 表示神经元在t时刻的加权输入, 因为:
因此:
我们用 表示列向量,用 表示行向量。 上式的第一项是向量函数对向量求导, 其结果为Jacobian矩阵:
同理, 上式第二项也是一个Jacobian矩阵:
其中, 表示根据向量 创建一个对角 矩阵,即
最后, 将两项合在一起, 可得:
上式描述了将 沿时间往前传递一个时刻的规律,有了这个规律, 我们就可以求得任意时刻k的误差项 :
式3就是将误差项沿时间反向传播的算法。
循环层将误差项反向传递到上一层网络, 与普通的全连接层是完全一样的。
下面是循环神经网络的其它资料
中文来源、英文来源
循环神经网络(Recurrent Neural Networks,RNNs)已经在众多自然语言处理(Natural Language Processing, NLP)中取得了巨大成功以及广泛应用。
该系列便是介绍RNNs的原理以及如何实现。主要分成以下几个部分对RNNs进行介绍:
1. RNNs的基本介绍以及一些常见的RNNs(本文内容);
2. 详细介绍RNNs中一些经常使用的训练算法,如Back Propagation Through Time(BPTT)、Real-time Recurrent Learning(RTRL)、Extended Kalman Filter(EKF)等学习算法,以及梯度消失问题(vanishing gradient problem)
3. 详细介绍Long Short-Term Memory(LSTM,长短时记忆网络);
4. 详细介绍Clockwork RNNs(CW-RNNs,时钟频率驱动循环神经网络);
5. 基于Python和Theano对RNNs进行实现,包括一些常见的RNNs模型。
不同于传统的FNNs(Feed-forward Neural Networks,前向反馈神经网络),RNNs引入了定向循环,能够处理那些输入之间前后关联的问题。定向循环结构如下图所示:
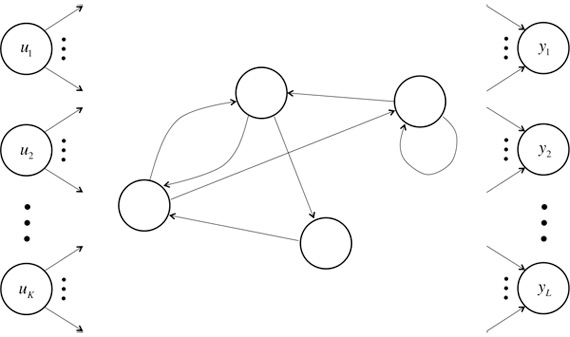
该tutorial默认读者已经熟悉了基本的神经网络模型。如果不熟悉,可以点击:Implementing A Neural Network From Scratch进行学习。
什么是RNNs
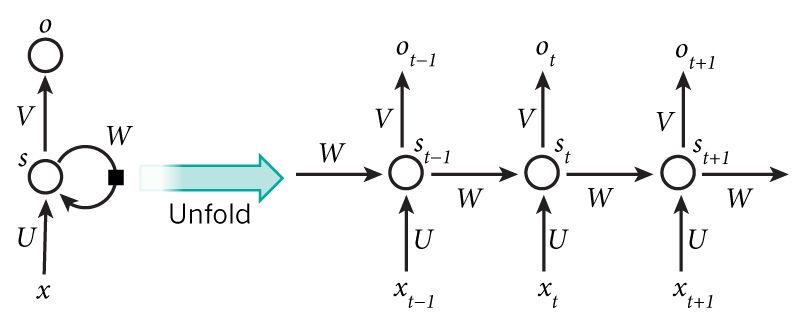
RNNs的目的是用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,下图便是一个典型的RNNs:

From Nature
RNNs包含输入单元(Input units),输入集标记为
,而输出单元(Output units)的输出集则被标记为
。RNNs还包含隐藏单元(Hidden units),我们将其输出集标记为
,这些隐藏单元完成了最为主要的工作。你会发现,在图中:有一条单向流动的信息流是从输入单元到达隐藏单元的,与此同时另一条单向流动的信息流从隐藏单元到达输出单元。在某些情况下,RNNs会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”,并且隐藏层的输入还包括上一隐藏层的状态,即隐藏层内的节点可以自连也可以互连。
上图将循环神经网络进行展开成一个全神经网络。例如,对一个包含5个单词的语句,那么展开的网络便是一个五层的神经网络,每一层代表一个单词。对于该网络的计算过程如下:
-
表示第
步(step)的输入。比如,
为第二个词的one-hot向量(根据上图,
为第一个词);
PS:使用计算机对自然语言进行处理,便需要将自然语言处理成为机器能够识别的符号,加上在机器学习过程中,需要将其进行数值化。而词是自然语言理解与处理的基础,因此需要对词进行数值化,词向量(Word Representation,Word embeding)[1]便是一种可行又有效的方法。何为词向量,即使用一个指定长度的实数向量v来表示一个词。有一种种最简单的表示方法,就是使用One-hot vector表示单词,即根据单词的数量|V|生成一个|V| * 1的向量,当某一位为一的时候其他位都为零,然后这个向量就代表一个单词。缺点也很明显:
- 由于向量长度是根据单词个数来的,如果有新词出现,这个向量还得增加,麻烦!(Impossible to keep up to date);
- 主观性太强(subjective)
- 这么多单词,还得人工打labor并且adapt,想想就恐
- 最不能忍受的一点便是很难计算单词之间的相似性。
现在有一种更加有效的词向量模式,该模式是通过神经网或者深度学习对词进行训练,输出一个指定维度的向量,该向量便是输入词的表达。如word2vec。
- 为隐藏层的第t步的状态,它是网络的记忆单元。 根据当前输入层的输出与上一步隐藏层的状态进行计算。 ,其中f一般是非线性的激活函数,如 或 ,在计算 时,即第一个单词的隐藏层状态,需要用到 ,但是其并不存在,在实现中一般置为0向量;
-
是第t步的输出,如下个单词的向量表示,
。
需要注意的是: - 你可以认为隐藏层状态 是网络的记忆单元. 包含了前面所有步的隐藏层状态。而输出层的输出 只与当前步的 有关,在实践中,为了降低网络的复杂度,往往 只包含前面若干步而不是所有步的隐藏层状态;
- 在传统神经网络中,每一个网络层的参数是不共享的。而在RNNs中,每输入一步,每一层各自都共享参数U,V,W。其反应在RNNs中的每一步都在做相同的事,只是输入不同,因此大大地降低了网络中需要学习的参数;这里并没有说清楚,解释一下,传统神经网络的参数是不共享的,并不是表示对于每个输入有不同的参数,而是将RNN是进行展开,这样变成了多层的网络,如果这是一个多层的传统神经网络,那么 到 之间的U矩阵与 到 之间的U是不同的,而RNNs中的却是一样的,同理对于s与s层之间的W、s层与o层之间的V也是一样的。
- 上图中每一步都会有输出,但是每一步都要有输出并不是必须的。比如,我们需要预测一条语句所表达的情绪,我们仅仅需要关心最后一个单词输入后的输出,而不需要知道每个单词输入后的输出。同理,每步都需要输入也不是必须的。RNNs的关键之处在于隐藏层,隐藏层能够捕捉序列的信息。
RNNs能干什么?
RNNs已经被在实践中证明对NLP是非常成功的。如词向量表达、语句合法性检查、词性标注等。在RNNs中,目前使用最广泛最成功的模型便是LSTMs(Long Short-Term Memory,长短时记忆模型)模型,该模型通常比vanilla RNNs能够更好地对长短时依赖进行表达,该模型相对于一般的RNNs,只是在隐藏层做了手脚。对于LSTMs,后面会进行详细地介绍。下面对RNNs在NLP中的应用进行简单的介绍。
语言模型与文本生成(Language Modeling and Generating Text)
给你一个单词序列,我们需要根据前面的单词预测每一个单词的可能性。语言模型能够一个语句正确的可能性,这是机器翻译的一部分,往往可能性越大,语句越正确。另一种应用便是使用生成模型预测下一个单词的概率,从而生成新的文本根据输出概率的采样。语言模型中,典型的输入是单词序列中每个单词的词向量(如 One-hot vector),输出时预测的单词序列。当在对网络进行训练时,如果
,那么第t步的输出便是下一步的输入。
下面是RNNs中的语言模型和文本生成研究的三篇文章:
- Recurrent neural network based language model
- Extensions of Recurrent neural network based language model
- Generating Text with Recurrent Neural Networks
机器翻译(Machine Translation)
机器翻译是将一种源语言语句变成意思相同的另一种源语言语句,如将英语语句变成同样意思的中文语句。与语言模型关键的区别在于,需要将源语言语句序列输入后,才进行输出,即输出第一个单词时,便需要从完整的输入序列中进行获取。机器翻译如下图所示:
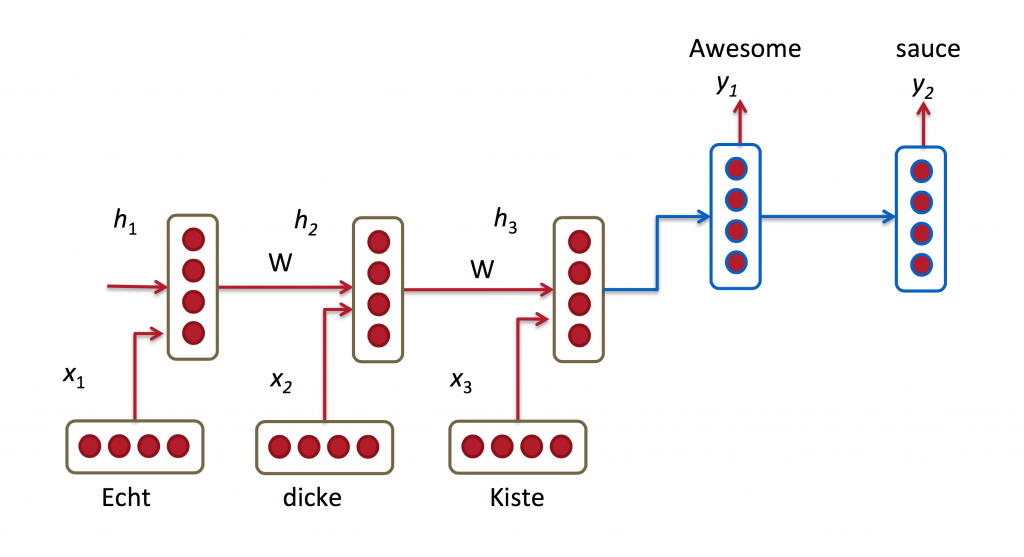
下面是关于RNNs中机器翻译研究的三篇文章:
- A Recursive Recurrent Neural Network for Statistical Machine Translation
- Sequence to Sequence Learning with Neural Networks
- Joint Language and Translation Modeling with Recurrent Neural Networks
语音识别(Speech Recognition)
语音识别是指给一段声波的声音信号,预测该声波对应的某种指定源语言的语句以及该语句的概率值。
RNNs中的语音识别研究论文:
- Towards End-to-End Speech Recognition with Recurrent Neural Networks
图像描述生成 (Generating Image Descriptions)
和卷积神经网络(convolutional Neural Networks, CNNs)一样,RNNs已经在对无标图像描述自动生成中得到应用。将CNNs与RNNs结合进行图像描述自动生成。这是一个非常神奇的研究与应用。该组合模型能够根据图像的特征生成描述。如下图所示:
图像描述生成中的深度视觉语义对比.
如何训练RNNs
对于RNN的训练和对传统的ANN训练一样。同样使用BP误差反向传播算法,不过有一点区别。如果将RNNs进行网络展开,那么参数W,U,V是共享的,而传统神经网络却不是的。并且在使用梯度下降算法中,每一步的输出不仅依赖当前步的网络,并且还以来前面若干步网络的状态。比如,在t=4时,我们还需要向后传递三步,已经后面的三步都需要加上各种的梯度。该学习算法称为Backpropagation Through Time (BPTT)。后面会对BPTT进行详细的介绍。需要意识到的是,在vanilla RNNs训练中,BPTT无法解决长时依赖问题(即当前的输出与前面很长的一段序列有关,一般超过十步就无能为力了),因为BPTT会带来所谓的梯度消失或梯度爆炸问题(the vanishing/exploding gradient problem)。当然,有很多方法去解决这个问题,如LSTMs便是专门应对这种问题的。
RNNs扩展和改进模型
这些年,研究者们已经提出了多种复杂的RNNs去改进vanilla RNN模型的缺点。下面是目前常见的一些RNNs模型,后面会对其中使用比较广泛的进行详细讲解,在这里进行简单的概述。
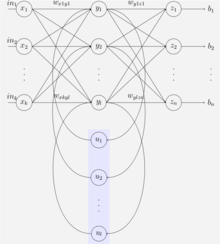
Simple RNNs(SRNs)[2]
SRNs是RNNs的一种特例,它是一个三层网络,并且在隐藏层增加了上下文单元,下图中的y便是隐藏层,u便是上下文单元。上下文单元节点与隐藏层中的节点的连接是固定(谁与谁连接)的,并且权值也是固定的(值是多少),其实是一个上下文节点与隐藏层节点一一对应,并且值是确定的。在每一步中,使用标准的前向反馈进行传播,然后使用学习算法进行学习。上下文每一个节点保存其连接的隐藏层节点的上一步的输出,即保存上文,并作用于当前步对应的隐藏层节点的状态,即隐藏层的输入由输入层的输出与上一步的自己的状态所决定的。因此SRNs能够解决标准的多层感知机(MLP)无法解决的对序列数据进行预测的任务。
SRNs网络结构如下图所示:
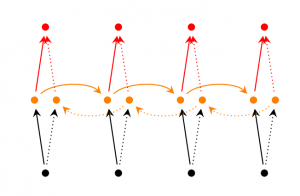
Bidirectional RNNs[3]
Bidirectional RNNs(双向网络)的改进之处便是,假设当前的输出(第t步的输出)不仅仅与前面的序列有关,并且还与后面的序列有关。例如:预测一个语句中缺失的词语那么就需要根据上下文来进行预测。Bidirectional RNNs是一个相对较简单的RNNs,是由两个RNNs上下叠加在一起组成的。输出由这两个RNNs的隐藏层的状态决定的。如下图所示:
Deep(Bidirectional)RNNs[4]
Deep(Bidirectional)RNNs与Bidirectional RNNs相似,只是对于每一步的输入有多层网络。这样,该网络便有更强大的表达与学习能力,但是复杂性也提高了,同时需要更多的训练数据。Deep(Bidirectional)RNNs的结构如下图所示:
Echo State Networks[5]
ESNs(回声状态网络)虽然也是一种RNNs,但是它与传统的RNNs相差很大。ESNs具有三个特点:
- 它的核心结构时一个随机生成、且保持不变的储备池(Reservoir),储备池是大规模的、随机生成的、稀疏连接(SD通常保持1%~5%,SD表示储备池中互相连接的神经元占总的神经元个数N的比例)的循环结构;
- 其储备池到输出层的权值矩阵是唯一需要调整的部分;
- 简单的线性回归就可完成网络的训练。
…….
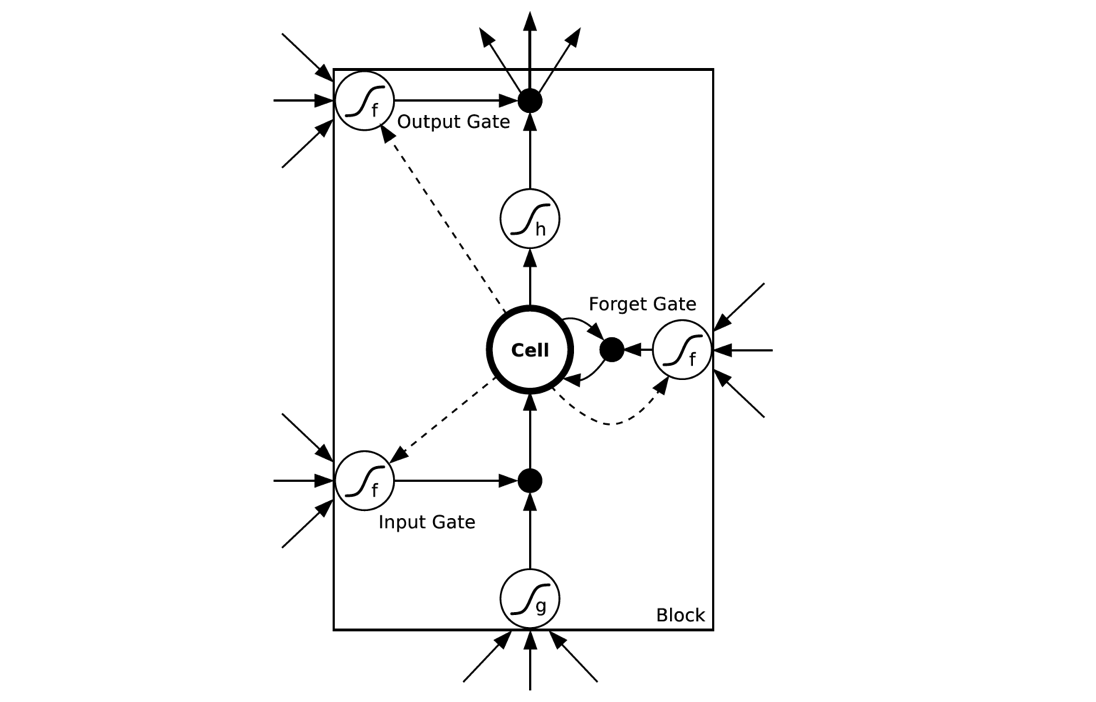
LSTMs与GRUs类似,目前非常流行。它与一般的RNNs结构本质上并没有什么不同,只是使用了不同的函数去去计算隐藏层的状态。在LSTMs中,i结构被称为cells,可以把cells看作是黑盒用以保存当前输入
之前的保存的状态
,这些cells更加一定的条件决定哪些cell抑制哪些cell兴奋。它们结合前面的状态、当前的记忆与当前的输入。已经证明,该网络结构在对长序列依赖问题中非常有效。LSTMs的网络结构如下图所示。对于LSTMs的学习,参见 this post has an excellent explanation