昨天晚上学长挂了4道题,让7点开始做,挂5个小时,我真的是。。。。吃完饭7.30开始做题,,
都是简单的并查集,然而我做道11点才做了3道,第四道简直了,做了这4道题我也正真认识道我自己有多菜,连并查集都理解不透彻,并查集改的是内容不是下标,我也学到了,当你不知道怎么读代码时,就动手画,然后一句一句读,一笔一笔改就能懂了,我从昨天晚上10点到11.30一直再想,尝试用各种方法
才有了点思路,下面让我们来看看是什么题难倒了我。。。。
动物王国中有三类动物A,B,C,这三类动物的食物链构成了有趣的环形。A吃B, B吃C,C吃A。
现有N个动物,以1-N编号。每个动物都是A,B,C中的一种,但是我们并不知道它到底是哪一种。
有人用两种说法对这N个动物所构成的食物链关系进行描述:
第一种说法是"1 X Y",表示X和Y是同类。
第二种说法是"2 X Y",表示X吃Y。
此人对N个动物,用上述两种说法,一句接一句地说出K句话,这K句话有的是真的,有的是假的。当一句话满足下列三条之一时,这句话就是假话,否则就是真话。
1) 当前的话与前面的某些真的话冲突,就是假话;
2) 当前的话中X或Y比N大,就是假话;
3) 当前的话表示X吃X,就是假话。
你的任务是根据给定的N(1 <= N <= 50,000)和K句话(0 <= K <= 100,000),输出假话的总数。
输入
第一行是两个整数N和K,以一个空格分隔。
以下K行每行是三个正整数 D,X,Y,两数之间用一个空格隔开,其中D表示说法的种类。
若D=1,则表示X和Y是同类。
若D=2,则表示X吃Y。
输出
只有一个整数,表示假话的数目。
100 7 1 101 1 2 1 2 2 2 3 2 3 3 1 1 3 2 3 1 1 5 5
3
我对题的理解就是,n个动物 m对关系,之后输入三个数如果1则这两个数有关系,如果2则这两个个数没有关系
之后判断假话,先把两种请况判断了,第一种输入的动物超过你给的动物h++,第二就是输入如果是2,然后后面两个数(动物)
一样h++,这两种都是假话,然后是最后一种,我想的办法是先把所有1,也就是有关系的联立起来形成几个集合sum1,然后输入有几个,然后在判断所有2,打破2中动物关系,然后输出有多少个集合sum2,然后sum2-sum1+h,就是假话的数量,
但是我不会用代码敲出来很崩溃,,试了一天无果,准备上网查答案看看能不能理解。
哦我想到了 在判断2的时候不需要让他们的祖宗都成为他们自己,只需要判断祖宗是不是一个就行了,如果是一个则h++
下面我要继续尝试了
#include<cstdio>
#include<iostream>
using namespace std;
int f[50000];
int find(int v){
return f[v]==v?v:find(f[v]);
}
void unions(int x,int y)
{
int fx = find(x);
int fy = find(y);
if(fx != fy)
f[fx] = fy;
}
int main()
{
int x,y,z;
int n,m,sum2=0;
int h=0,p=0,a[100000][2];
cin>>n>>m;
for(int i=1;i<=n;i++)
{
f[i] = i;
}
for(int i=1;i<=m;i++)
{
cin>>z>>x>>y;
if(x>n||y>n)
{
h++;
continue;
}
if(z==2&&x==y)
{
h++;
continue;
}
if(z==1){
unions(x,y);
}
if(z==2)
{
p++;
a[p][0]=x;
a[p][1]=y;
}
}
for(int i=1;i<=n;i++)
f[i] = find(f[i]);
for(int i=1;i<=p;i++)
if(f[a[i][0]]==f[a[i][1]])
sum2++;
h=h+sum2;
cout<<h;
return 0;
}
这种就是,假设1是对的,然后去去判断2,如果2两个数是同类的话这个2就是错的,答案+1.
但是这种思路是错的,假设2 1 2,2 3 1,然后1 2 3,这种情况是判断不出来的,今天放弃了,明天在战。
看下大佬的思路
https://blog.csdn.net/niushuai666/article/details/6981689
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
#define N 50010
struct node
{
int pre;
int relation;
};
node p[N];
int find(int x) //查找根结点
{
int temp;
if(x == p[x].pre)//如果根节点是他自己
return x;
temp = p[x].pre; //如果根节点不是他自己,则路径压缩
p[x].pre = find(temp);//找到根节点
p[x].relation = (p[x].relation + p[temp].relation) % 3; //并关系域更新跟新的是他们本身和根节点的关系
return p[x].pre; //根结点
}
int main()
{
int n, k;
int ope, a, b;
int root1, root2;
int sum = 0; //假话数量
scanf("%d%d", &n, &k);
for(int i = 1; i <= n; ++i) //初始化
{
p[i].pre = i;//开始让他们的父节点都是他们自己
p[i].relation = 0;//然后他们自己就是自己的同类
}
for(int i = 1; i <= k; ++i)
{
scanf("%d%d%d", &ope, &a, &b);
if(a > n || b > n) //条件2
{
sum++;
continue;
}
if(ope == 2 && a == b) //条件3
{
sum++;
continue;
}
root1 = find(a);//找到a的根节点,并用root1记录
root2 = find(b);//找到b的根节点,并用root2记录
if(root1 != root2) // //如果a,b的根节点不同,就是说他们其中一个还没有和另一个产生关系(两个集合没有交集),这时就合并他们,然后,判断输入的ope是1还是2,然后确定他们根节点的关系
{
p[root2].pre = root1;//合并a,b的根节点
p[root2].relation = (3 + (ope - 1) +p[a].relation - p[b].relation) % 3;//更新一下b的根节点和a的根节点关系
}
else//如果a,b的根节点相同,(就是说他们已经在说过的话中产生的关系,在一个集合内,),这时就判断ope然后判断a,b关系,并做出判断。
{
if(ope == 1 && p[a].relation != p[b].relation)//如果输入的是1,并且a和b跟他们根节点的关系不一样
{
sum++;//这句话是假话
continue;
}
if(ope == 2 && ((3 - p[a].relation + p[b].relation) % 3 != ope - 1))//如果输入的是2,但是他们的关系不是a吃b
{
sum++;//这句话是假话
continue;
}
}
}
printf("%d\n", sum);
return 0;
}
我觉得更新关系这一步很重要,也是一个难以理解的点
下面就是我看别大佬的解释
查找操作:
在查找时因为节点不仅有父亲节点域,而且还有表示节点与其父亲节点的关系域,查找过程中对父亲节点域的处理和简单的并查集处理一样,即在查找过程中同时实现路径压缩,但正是由于路径压缩,使得表示节点与其父亲节点的关系域发生了变化,所以在路径压缩过程中节点和其对应的父节点的关系域发生了变化(因为路径压缩之前节点x的父亲节点为rootx的话,那么在路径压缩之后节点x的父亲节点就变为了节点rootx的父亲节点rootxx,所以此时p[x].relation存储的应该是节点x与现在父亲节点rootxx的关系),此处可以画图理解一下:

很明显查找之前节点x的父亲节点为rootx,假设此时p[x].relation=1(即表示x的父亲节点rootx吃x)且p[rootx].relation=0(即表示rootx和其父亲节点rootxx是同类),由这两个关系可以推出rootxx吃x,而合并以后节点x的父亲节点为rootxx(实现了路径压缩),且节点x的父亲节点rootxx吃x,即查找之后p[x].relation=1。
合并操作:
在将元素x与y所在的集合合并时,假设元素x所在的集合编号为rootx,元素y所在的集合编号为rooty,合并时直接将集合rooty挂到集合rootx上,即p[rooty].parent=rootx,此时原来集合rooty中的根节点rooty的关系域也应随之发生变化,因为合并之前rooty的父亲节点就是其自身,故此时p[rooty].relation=0,而合并之后rooty的父亲节点为rootx,所以此时需判断rootx与rooty的关系,即更新p[rooty]的值,同理画图理解:
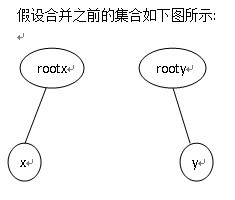
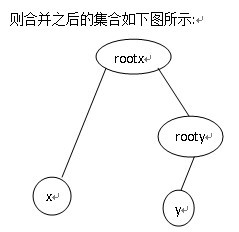
此时假设假设p[x].relation=0(即x与rootx的关系是同类),p[y].relation=1(即rooty吃y),则有:
1>输入d=1时,即输入的x和y是同类,则有上述关系可以推出rooty吃rootx,即p[rooty].relation=2;
2>输入d=2时,即输入的x吃y,则有上述关系可以推出rooty与rootx是同类(因为rooty吃y,x吃y,则rooty与x是同类,又rootx与x是同类),即p[rooty].relation=0;
当然,这只是一种可能,其它的可能情况和上面一样分析。
当元素x与元素y在同一集合时,则不需要合并,因为此时x与y的父亲节点相同,可以分情况讨论:
1>d=1时,即x与y是同类时,此时要满足这要求,则必须满足p[x].relation=p[y].relation,这很容易推出来.
2>d=2时,即表示x吃y,此时要满足这要求,则也必须满足一定的条件,如x和root是同类(即p[x].relation=0),此时要满足x吃y,则必须满足root吃y,即p[y].relation=1,可以像上面一样画图来帮助理解.
关系域更新:
当然,这道题理解到这里思路已经基本明确了,剩下的就是如何实现,在实现过程中,我们发现,更新关系域是一个很头疼的操作,网上各种分析都有,但是都是直接给出个公式,至于怎么推出来的都是一笔带过,让我着实头疼了很久,经过不断的看discuss,终于明白了更新操作是通过什么来实现的。下面讲解一下仔细再想想,rootx-x 、x-y、y-rooty,是不是很像向量形式?于是我们可以大胆的从向量入手:
tx ty
| |
x ~ y
对于集合里的任意两个元素x,y而言,它们之间必定存在着某种联系,因为并查集中的元素均是有联系的(这点是并查集的实质,要深刻理解),否则也不会被合并到当前集合中。那么我们就把这2个元素之间的关系量转化为一个偏移量(大牛不愧为大牛!~YM)。
由上面可知:
x->y 偏移量0时 x和y同类
x->y 偏移量1时 x被y吃
x->y 偏移量2时 x吃y
有了这个假设,我们就可以在并查集中完成任意两个元素之间的关系转换了。
不妨继续假设,x的当前集合根节点rootx,y的当前集合根节点rooty,x->y的偏移值为d-1(题中给出的询问已知条件)
(1)如果rootx和rooty不相同,那么我们把rooty合并到rootx上,并且更新relation关系域的值(注意:p[i].relation表示i的根结点到i的偏移量!!!!(向量方向性一定不能搞错))
此时 rootx->rooty = rootx->x + x->y + y->rooty,这一步就是大牛独创的向量思维模式
上式进一步转化为:rootx->rooty = (relation[x]+d-1+3-relation[y])%3 = relation[rooty],(模3是保证偏移量取值始终在[0,2]间)
(2)如果rootx和rooty相同(即x和y在已经在一个集合中,不需要合并操作了,根结点相同),那么我们就验证x->y之间的偏移量是否与题中给出的d-1一致
此时 x->y = x->rootx + rootx->y
上式进一步转化为:x->y = (3-relation[x]+relation[y])%3,
若一致则为真,否则为假。