xml解析器
xml只是一个文本文件,无论内容存储的是什么数据,总是需要被应用程序来使用。所以应用程序是依赖xml文件,应用程序就需要读取xml文件,并解析它,但xml解析并不很方便,我们需要使用xml解析器。
DOM和SAX
它们是思想,是可以跨语言的。
- DOM: 文档对象模型,它由W3C提供。
- SAX: xml简单的API
DOM原理
在解析XML文档之后,把所有的xml中数据保存到一组对象中。包含到Document中,可以通过Document对象来获取其中数据。
SAX原理
没有解析结果,在解析过程中来处理数据,而DOM是解析后的结果,即Document,所有数据都在Documentt,然后数据都在Document,然后处理数据使用Document完成,SAX是基于事件驱动的,当解析过程中,在特定事件引发时,来调用接口中的特定方法,在开始SAX解析之前用户需要给SAX提供接口实现类。
SAX和DOM优缺点
- 优点:SAX适合解析大xml文件(内存空间占用小),因为是解析一行处理一行,处理完了就不需要保留数据
- 缺点:SAX因为是解析一行处理一行,解析之后数据就丢失了,所以元素与元素之间的结构关系没有保留下来。
DOX和SAX在java中只是一组接口,儿实现类由第三方提供。例如:Apache xerces.jar就是DOM和SAX的实现。
我们的应用程序使用了A公司的解析器,然后又想更换为B公司的解析器,那么需要修改应用 程序,这就说明耦合过于太紧,java提供了JAXP,使我们的应用程序与第三方的解析器接耦。
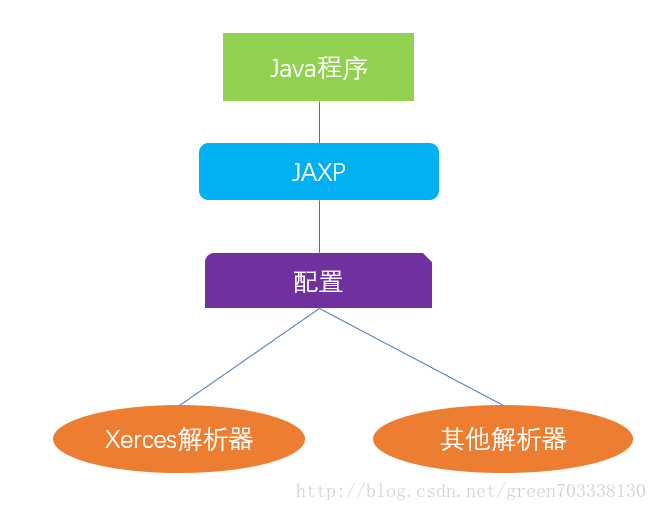
如果没有提供解析器,JAXP还有自己默认的解析器。
JAXP之DOM解析
1、得到解析器对象
2、使用解析器来解析指定的xml,得到Document.
//创建工厂
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
//得到解析器
DocumentBuilder builder=factory.newDocumentBuilder();
//解析指定的xml文件,得到Documnet
Documnet doc=builder.parse(new File("src/students.xml"));代码:
Demol.java
package com.me.jaxp;
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.junit.Test;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class Demol1 {
@Test
public void fun1() throws Exception{
/*
* 得到Document
* 1.创建工厂
* 2.通过工厂得到解析器
* 3.通过解析器来解析xml,得到Document
*/
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
//自己不提供,使用默认的。
DocumentBuilder builder=factory.newDocumentBuilder();
Document document=builder.parse(new File("src/students.xml"));
///////////////////////////////////////////////////////////////
/*
* 遍历Document
* 1.从Document中获取根元素,即文档元素。
* 2.通过root元素获取它的所有子元素
*/
Element root=document.getDocumentElement();
NodeList stuNodeList= root.getElementsByTagName("student");
/*
* 3.循环遍历stuNodeList,获取每个student元素
*/
for(int i=0;i < stuNodeList.getLength(); i++) {
Node node=stuNodeList.item(i);
Element stuEle= (Element) node;//因为stuNodeList中都是学生元素,所以可以强转
//获取stuEle元素中名称为number属性的值。
String number=stuEle.getAttribute("number");
//获取stuEle的所有名为name的 子元素,返回值为NodeLiset
//再调用NodeList的item(0),因为我们知道一个学生元素最多就一个name子元素
//调用name子元素的getTextContent()来获取name元素的文本内容。
String name=stuEle.getElementsByTagName("name").item(0).getTextContent();
String age=stuEle.getElementsByTagName("age").item(0).getTextContent();
String sex=stuEle.getElementsByTagName("sex").item(0).getTextContent();
System.out.println(number+","+age+","+sex);
}
}
}students.xml
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student number="ITCAST_1001">
<name>zhangSan</name>
<age>23</age>
<sex>male</sex>
</student>
<student number="ITCAST_1002">
<name>liSi</name>
<age>24</age>
<sex>female</sex>
</student>
</students>结果:
ITCAST_1001,23,male
ITCAST_1002,24,female
JAXP之SAX
1、得到工厂
2、通过工厂得到解析器
3、让解析去解析指定的 xml,不只是需要xml文件,还需要一个接口的实现。
class MyHandler extends DefaultHandler {
public void startDocument() {
System.out.println("开始解析");
}
public void startElement(String qName) {
System.out.println("开始解析一个元素,元素名为"+qName);
}
}代码
Demol2.java
package com.me.jaxp;
import java.io.File;
import java.io.IOException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.junit.Test;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.DefaultHandler;
public class Demol2 {
@Test
public void fun1() throws Exception
{
/*
* 1、创建工厂
* 2、创建解析器
* 3、给解析器提供xml和处理器,然后开始解析
*/
SAXParserFactory factory=SAXParserFactory.newInstance();
SAXParser parser = factory.newSAXParser();
//解析方法需要两个参数,一个是xml文件,一个是处理器对象
parser.parse(new File("src/students.xml"),new MyHandler());
}
}
//自定义SAX的处理器,这里的方法会在解析的过程中被调用!
class MyHandler extends DefaultHandler
{
@Override
public void startDocument() throws SAXException {
System.out.println("开始解析....");
}
@Override
public void endDocument() throws SAXException {
System.out.println("解析结束....");
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println("开始解析元素"+qName);
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.println("结束解析元素"+qName);
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
String str =new String(ch, start, length);
str.trim();//去空白有问题
if(!str.isEmpty()){
System.out.println(str);
}
}
}students.xml
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student number="ITCAST_1001">
<name>zhangSan</name>
<age>23</age>
<sex>male</sex>
</student>
<student number="ITCAST_1002">
<name>liSi</name>
<age>24</age>
<sex>female</sex>
</student>
</students>Dom4j
相关Jar包:dom4j.jar、jaxen.jar,复制jar后要buildpath
相关操作
1、获取org.dom4j.Document
2、保存Document到xml文件中
3、遍历
4、添加
5、修改
6、删除
7、上面包含了查询
代码
Demol3.java
package com.me.jaxp;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.UnsupportedEncodingException;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
/**
* Dom4j演示
*
*/
public class Demol3 {
/*
* 得到Document
*/
@Test
public void fun1() throws Exception{
//创建解析器
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("src/students.xml"));
System.out.println(doc.asXML());
}
/*
* 保存Document
*/
@Test
public void fun2() throws Exception {
//得到Document
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("src/students.xml"));
//保存Document
XMLWriter writer=new XMLWriter(new FileOutputStream("src/student_copy.xml"));
writer.write(doc);
}
/*
* 遍历Document
*/
@Test
public void fun3() throws Exception{
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("src/students.xml"));
//---------------------------//
//1、获取根元素
Element root=doc.getRootElement();
//2、获取根元素中所以student元素
List<Element> stuEleList = root.elements("student");
//3、循环遍历所有学生元素
for(Element stuEle : stuEleList){
//1、获取学生元素的number
String number=stuEle.attributeValue("number");
//2、获取学生元素名为name的子元素的文本内容
String name=stuEle.elementText("name");
String age=stuEle.elementText("age");
String sex=stuEle.elementText("sex");
System.out.println(number+","+name+","+age+","+sex);
}
}
/*
* 添加元素
*/
@Test
public void fun4() throws Exception{
//得到Document
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("src/students.xml"));
//1、获取根元素
Element root=doc.getRootElement();
//2、给root元素添加一个名Ericstudent的子元素,并返回它
/*
* 三件事
* *创建一个名为student的元素
* *把这个元素添加到root中
* *返回它
*/
Element stuEle = root.addElement("student");
//给stuEle添加属性,名为number,值为ITCAST_1003
stuEle.addAttribute("number", "ITCAST_1003");
// Element nameEle = stuEle.addElement("name");//此时name无值
// nameEle.setText("WangWu");
//给stuEle添加名为name的子元素,并为子元素设置文本内容为wangwu
stuEle.addElement("name").setText("WangWu");
stuEle.addElement("age").setText("17");
stuEle.addElement("sex").setText("male");
// //////////////////////////////////
// /*//设置保存的格式化器
// /*参数说明
// * 1、\t:使用什么来完成缩进
// * 2、是否换行
// */
// OutputFormat format = new OutputFormat("\t",true);
// //把文档中原有的空白去掉
// format.setTrimText(true);
// //保存Document
// //在创建writer时,知道格式化器
// XMLWriter writer=new XMLWriter(new FileOutputStream("src/student_copy.xml"),format);
// writer.write(doc);
//保存Document
//在创建writer时,知道格式化器
XMLWriter writer=new XMLWriter(new FileOutputStream("src/student_copy.xml"));
writer.write(doc);
}
/*
* 修改元素
*/
@Test
public void fun5() throws Exception{
/*
* XPath
*/
//得到Document
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("src/student_copy.xml"));
///////////
/*
* 找到number为ITCAST_1003的student元素
* 修改它的age子元素内容为81
* 修改它的sex子元素内容为female
*/
//1、使用XPath找到符合条件的子元素
//查找student元素,条件是number子元素的属性为ITCAST_1003
Element stuEle = (Element) doc.selectSingleNode("//student[@number='ITCAST_1003']");
//2、修改stuEle的age子元素内容为81
stuEle.element("age").setText("81");
stuEle.element("sex").setText("female");
XMLWriter writer=new XMLWriter(new FileOutputStream("src/student_copy.xml"));
writer.write(doc);
}
/*
* 删除元素
*/
@Test
public void fun6() throws Exception{
/*
* XPath
*/
//得到Document
SAXReader reader=new SAXReader();
Document doc=reader.read(new File("src/student_copy.xml"));
///////////
/*
* 找到number为ITCAST_1003的student元素
* 修改它的age子元素内容为81
* 修改它的sex子元素内容为female
*/
//1、使用XPath找到符合条件的子元素
//查找student元素,条件是name子元素的文本内容为WangWu
Element stuEle = (Element) doc.selectSingleNode("//student[name='WangWu']");
//2、获取父元素,使用父元素删除指定子元素
stuEle.getParent().remove(stuEle);
XMLWriter writer=new XMLWriter(new FileOutputStream("src/student_copy.xml"));
writer.write(doc);
}
}