1.1.1. Bagging
Bagging也叫自举汇聚法(bootstrap-aggregating),是一种在原始数据集上通过有放回抽样重新选出S个新数据集来训练分类器的集成技术。也就是说这些新数据集是允许重复的。使用训练出来的分类器集合来对新样本进行分类,然后用多数投票或者对输出求均值的方法统计所有分类器的分类结果,结果最高的类别即为最终标签。
1.1.1.1. 随机森林
其基本思想就是构造很多棵决策树,形成一个森林,然后用这些决策树共同决策输出类别是什么。随机森林算法及在构建单一决策树的基础上的,同时是单一决策树算法的延伸和改进。在整个随机森林算法的过程中,有两个随机过程,第一个就是输入数据是随机的从整体的训练数据中选取一部分作为一棵决策树的构建,而且是有放回的选取;第二个就是每棵决策树的构建所需的特征是从整体的特征集随机的选取的,这两个随机过程使得随机森林很大程度上避免了过拟合现象的出现。
算法过程:
1、从训练数据中选取n个数据作为训练数据输入,一般情况下n是远小于整体的训练数据N的,这样就会造成有一部分数据是无法被去到的,这部分数据称为袋外数据,可以使用袋外数据做误差估计。
2、选取了输入的训练数据的之后,需要构建决策树,具体方法是每一个分裂结点从整体的特征集M中选取m个特征构建,一般情况下m远小于M。
3、在构造每棵决策树的过程中,按照选取最小的基尼指数进行分裂节点的选取进行决策树的构建。决策树的其他结点都采取相同的分裂规则进行构建,直到该节点的所有训练样例都属于同一类或者达到树的最大深度。
4、 重复第2步和第3步多次,每一次输入数据对应一颗决策树,这样就得到了随机森林,可以用来对预测数据进行决策。
5、 输入的训练数据选择好了,多棵决策树也构建好了,对待预测数据进行预测,比如说输入一个待预测数据,然后多棵决策树同时进行决策,最后采用多数投票的方式进行类别的决策。
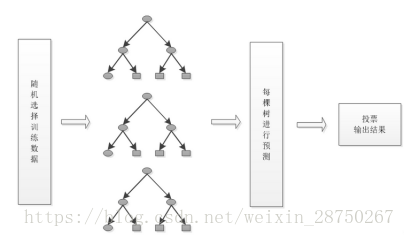
1. 在构建决策树的过程中是不需要剪枝的。
2. 整个森林的树的数量和每棵树的特征需要人为进行设定。
构建决策树的时候分裂节点的选择是依据最小基尼系数的。