最近,线上环境的Java代码里,处理了一个由ExecutorServicec线程池引发的问题,将处理过程和一些调试过程沉淀下来。
- 场景描述
应用为分布式场景下,海量任务处理模块。其中,有一个Java daemon进程,通过队列接受Java代码描述的任务(jar),产生子进程(单独的JVM)class loader,处理定义的Java代码,并收集日志、处理结果等,子进程数量在百级。启动参数如下:
java -server -Xss256k -Xmx4096m -Xms4096m -XX:NewRatio=4 -XX:PermSize=96m -XX:MaxPermSize=96m -XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:gc.log -XX:+HeapDumpOnOutOfMemoryError -XX:ErrorFile=./stderr -XX:+UseConcMarkSweepGC
- 问题现象
执行的大量任务集中在凌晨,通常情况下,内存维持在1G ~ 1.5G,由于代码方面上会注意Yong GC的亲和性,并且处理逻辑趋向短时间的内存适用,故YongGC次数稍多,每次回收较多,FullGC很少。

日常的gc.log截取:
- 2014-04-02T00:15:13.336+0800: 31549.990: [GC 31549.990: [ParNew: 673793K->2029K(755008K), 0.0051360 secs] 731427K->60257K(4110464K), 0.0053540 secs] [Times: user=0.03 sys=0.00, real=0.00 secs]
- 2014-04-02T02:02:17.091+0800: 37973.745: [GC 37973.745: [ParNew: 673197K->3098K(755008K), 0.0056950 secs] 731425K->61807K(4110464K), 0.0059840 secs] [Times: user=0.04 sys=0.00, real=0.00 secs]
- 2014-04-02T03:25:39.567+0800: 42976.221: [GC 42976.221: [ParNew: 674266K->2130K(755008K), 0.0067750 secs] 732975K->60842K(4110464K), 0.0070530 secs] [Times: user=0.04 sys=0.00, real=0.01 secs]
- 2014-04-02T04:12:15.891+0800: 45772.545: [GC 45772.545: [ParNew: 673298K->4497K(755008K), 0.0103740 secs] 732010K->64271K(4110464K), 0.0106280 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]
- 2014-04-02T04:40:27.685+0800: 47464.339: [GC 47464.340: [ParNew: 675611K->1931K(755008K), 0.0076410 secs] 735386K->61723K(4110464K), 0.0078830 secs] [Times: user=0.04 sys=0.00, real=0.01 secs]
- 2014-04-02T05:02:00.719+0800: 48757.373: [GC 48757.373: [ParNew: 673095K->2770K(755008K), 0.0069400 secs] 732887K->62579K(4110464K), 0.0071810 secs] [Times: user=0.04 sys=0.00, real=0.00 secs]
- 2014-04-02T05:18:45.616+0800: 49762.270: [GC 49762.270: [ParNew: 673911K->4611K(755008K), 0.0084600 secs] 733720K->64424K(4110464K), 0.0087260 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
- 2014-04-02T05:31:57.960+0800: 50554.614: [GC 50554.614: [ParNew: 675779K->7261K(755008K), 0.0111740 secs] 735592K->67237K(4110464K), 0.0114760 secs] [Times: user=0.06 sys=0.00, real=0.02 secs]
- 2014-04-02T05:39:29.031+0800: 51005.685: [GC 51005.686: [ParNew: 678429K->8082K(755008K), 0.0091520 secs] 738405K->68060K(4110464K), 0.0094180 secs] [Times: user=0.05 sys=0.00, real=0.01 secs]
- 2014-04-02T05:45:38.114+0800: 51374.768: [GC 51374.768: [ParNew: 679250K->8359K(755008K), 0.0071780 secs] 739228K->69105K(4110464K), 0.0074630 secs] [Times: user=0.04 sys=0.00, real=0.01 secs]
日常的jstat截取(启动后一段时间):
- [xxxxxxxxxxxxxxxxxxxx]$ sudo /usr/java/default/bin/jstat -gcutil 9974 1s
- S0 S1 E O P YGC YGCT FGC FGCT GCT
- 0.00 0.60 78.51 2.52 40.91 139 0.718 0 0.000 0.718
- 0.00 0.60 78.51 2.52 40.91 139 0.718 0 0.000 0.718
- 0.00 0.60 78.51 2.52 40.91 139 0.718 0 0.000 0.718
- 0.00 0.60 78.51 2.52 40.91 139 0.718 0 0.000 0.718
- 0.00 0.60 78.51 2.52 40.91 139 0.718 0 0.000 0.718
当天凌晨 JVM内存异常,触发报警。内存几乎用满,FullGC频率极具增加,子进程由于和该进程有内存交互,故部分任务直接oom,报错out of memroy : java heap space。
内存暴增后的gc.log:
- 2014-03-31T08:28:49.731+0800: 210168.258: [CMS-concurrent-sweep-start]
- 2014-03-31T08:28:49.766+0800: 210168.294: [CMS-concurrent-sweep: 0.035/0.035 secs] [Times: user=0.03 sys=0.00, real=0.03 secs]
- 2014-03-31T08:28:49.766+0800: 210168.294: [CMS-concurrent-reset-start]
- 2014-03-31T08:28:49.776+0800: 210168.304: [CMS-concurrent-reset: 0.010/0.010 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
- 2014-03-31T08:28:49.851+0800: 210168.379: [GC 210168.379: [ParNew: 755007K->755007K(755008K), 0.0000420 secs]210168.379: [CMS: 3355177K->3355176K(3355456K), 0.2814320 secs] 4110185K->4110177K(4110464K), [CMS Perm : 40876K->4087
- 6K(98304K)], 0.2817730 secs] [Times: user=0.29 sys=0.00, real=0.28 secs]
- 2014-03-31T08:28:50.134+0800: 210168.662: [GC [1 CMS-initial-mark: 3355176K(3355456K)] 4110182K(4110464K), 0.0070090 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
- 2014-03-31T08:28:50.827+0800: 210169.355: [GC [1 CMS-initial-mark: 3355176K(3355456K)] 4110182K(4110464K), 0.0070100 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
- 2014-03-31T08:28:50.834+0800: 210169.362: [CMS-concurrent-mark-start]
- 2014-03-31T08:28:50.884+0800: 210169.412: [CMS-concurrent-mark: 0.049/0.050 secs] [Times: user=0.25 sys=0.00, real=0.05 secs]
- 2014-03-31T08:28:50.884+0800: 210169.412: [CMS-concurrent-preclean-start]
- 2014-03-31T08:28:51.007+0800: 210169.534: [CMS-concurrent-preclean: 0.123/0.123 secs] [Times: user=0.12 sys=0.00, real=0.12 secs]
- 2014-03-31T08:28:51.007+0800: 210169.534: [CMS-concurrent-abortable-preclean-start]
- 2014-03-31T08:28:51.007+0800: 210169.534: [CMS-concurrent-abortable-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
- 2014-03-31T08:28:51.007+0800: 210169.535: [GC[YG occupancy: 755007 K (755008 K)]210169.535: [Rescan (parallel) , 0.0059270 secs]210169.541: [weak refs processing, 0.0000110 secs] [1 CMS-remark: 3355177K(3355456K)] 4110185K(4110
- 464K), 0.0060740 secs] [Times: user=0.07 sys=0.00, real=0.01 secs]
- 2014-03-31T08:28:51.014+0800: 210169.541: [CMS-concurrent-sweep-start]
- 2014-03-31T08:28:51.049+0800: 210169.577: [CMS-concurrent-sweep: 0.035/0.035 secs] [Times: user=0.04 sys=0.00, real=0.04 secs]
- 2014-03-31T08:28:51.049+0800: 210169.577: [CMS-concurrent-reset-start]
- 2014-03-31T08:28:51.059+0800: 210169.587: [CMS-concurrent-reset: 0.010/0.010 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
(这里有个小技巧,如果jstat jmap等长时间没响应然后打出来异常日志,可以带-F参数多试几次。)
用/usr/java/default/bin/jmap -histo 9974查看内存,发现当量的char[]和string在占用,但由于没有trace或者class信息,不能定位问题,于是决定用/usr/java/default/bin/jmap -dump:format=b,file=jvm.dump.hprof 9974将JVM的整个Heap做了个镜像(JVM在oom时候也会自动dump一个hprof文件,文件名规则java_pidxxx.hprof)。此镜像和现在的eden + from/to + old + perm的总和是一样大的:
- [xxxxxxxxxxxxxxxxxxxxxxxx]$ du -sh jvm.dump.hprof
- 4.0G jvm.dump.hprof
起初,由于文件太大,并且是在线上remote server上,跨机房弄到本地比较慢。后来发现dump出来的hprof里面是大量的文本信息,就用tar压缩了一下,压缩后大小300+M,无奈公司的Heap分析不好用,就忍受了进20分钟,将hprof弄到了本地机器。用MAT(Eclipse MAT也可)分析了一下,注意如果hprof比较大,还要把MAT或者Eclipse的启动参数-Xmx最大堆调到比hprof大些才能分析。如下:
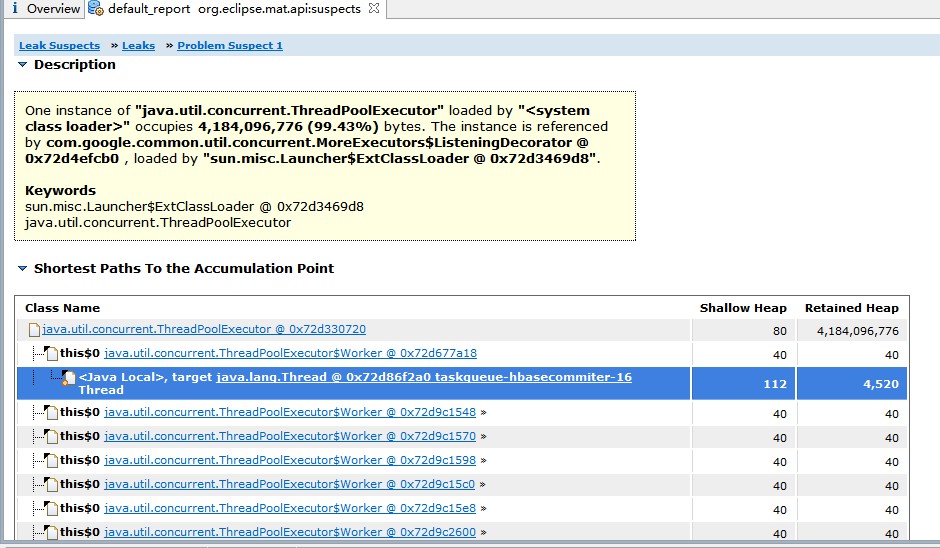
Eclipse MAT会直接给出建议(Leak suspect),代码里TaskDispatcher(spring注入的singleton单类)用了过多内存。经过其他统计,TopConsumer,Object Tree等,均印证了TaskDispatcher占用了大量内存,在 中深挖这个TaskDispatcher内存占用,跟踪shallow大小(@注意,shallow heap是这个对象成员引用自身和原始类型占用内存大小,不包含引用到Heap上的。Retained Heap则包括对象成员和成员指向的Heap内存),最终定位到Java类库ExecutorsService线程池中的BlockingQueue中有5万多元素,每个元素其实是一个日志的Buffer,大小在100k左右。乘下来算大概就是4G。
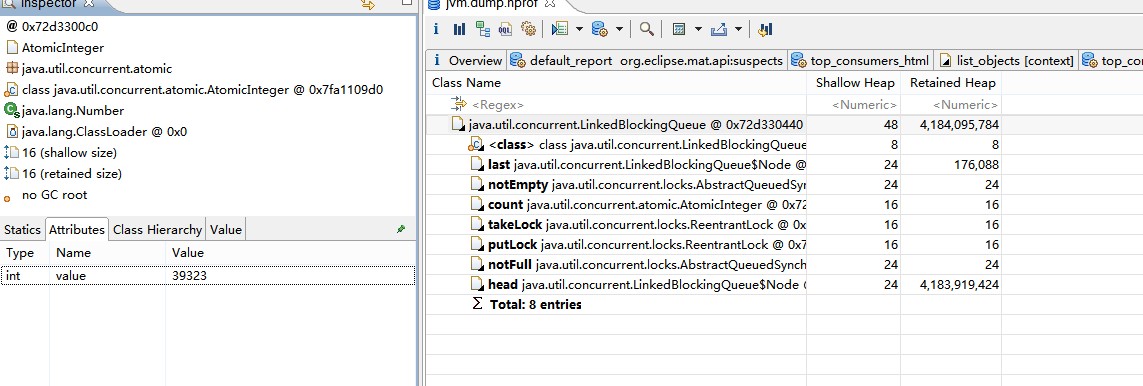
ExecutorService不太熟悉的同学可以Google,也可以参考我之前的博客Taskqueue队列类似。BlockingQueue是解耦生产者和消费者异步的中间存储队列。在当前场景中,线程池的大小和并发度已经进行了控制,正常情况下,如果消费端正常执行,则BlockingQueue不会太大。消费者是一个存在socket io的程序。难道是网络读写发生了异常或者阻塞?
后来经日志确认,发现了大量socket exception,那个时候网络出现了长时间的断开。这个socket的读写超时又设置的比较大源,秒级,导致消费端消费BlockingQueue里面的数据速度远小于生产者,导致Queue越来越大。Queue里面的对象又都是强引用,则不断的触发FullGC。
然后很多同学会好奇,为什么这么频繁的FullGC之后,为什么JVM不Crash呢?原因在于JVM有两个参数没设置:
-XX:+UseGCOverheadLimit 这个参数代表GC超过多长时间则放弃尝试,直接OOM
后续对代码进行了修改,手动构造new ThreadPoolExecutor(xxx,xxx,xxx,new LinkedBlockingDeque() )自己定义一个BlockingQueue的实例,在进一步,可以自定义ExecutorService的policy来制定如果队列太长了,所做的处理方式。默认的BlockingQueue最大元素是Integer.MAX_VALUE,满了的策略是直接Abort丢掉数据。