一 软件静态分析背景
软件静态分析的相当部分的内容就是发现代码中的缺陷,缺陷的形式往往五花八门,各式各样。每当发现一个缺陷,测试人员首先会感到高兴,终于抓到了一条“虫”,可继而很可能会感到心虚,因为,在现有技术条件下,一条软件行业的规律是仍然有效的:你发现的问题越多意味着被测试软件中隐藏的问题也越多。测试人员真希望能够有这么个系统,当我我发现一个代码缺陷后,系统能够提供给我所有代码中可能存在的通该缺陷相关的缺陷,从而有针对性的去高效的抓其它的“虫”,如果这样的系统真的出现了,理想情况下,那条软件行业的规律也就失效了。当然,有人会说,如果把所有代码缺陷之间的关系都研究清楚了,那不就可以彻底解决这个问题了么。问题是代码的缺陷成百上千,各式各样,组合起来的数量更是天文数字。目前的技术水平是没有办法研究清楚所有缺陷之间的相关关系的。
二 “机器学习”与“推荐系统”简介
“机器学习”是人工智能的一个分支。它的概念有多种表述形式。具体说就是使用计算机设计一个系统,它能够根据提供的训练数据按照一定的方式来学习;随着训练次数的增加,该系统可以在性能上不断学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。它是用来解决不确定性问题的,解决的程度可能不是百分之百。换句话说,如果问题有明确的解决方法,跟本用不到“机器学习”。“ 机器学习”全过程包括获取数据、清洗数据、分析数据与建立模型、测试与优化模型等几个步骤。
“推荐系统”顾名思义是一个用于向用户推荐信息的软件系统。目的是帮助用户快速准确的找到自己需要的信息。具体就是应用推荐算法根据用户提供的线索信息获得同线索相关的信息列表。推荐算法主要包括基于内容推荐、协同过滤推荐、基于关联规则推荐、基于效用推荐、基于知识推荐、基于模型推荐、组合推荐等多种推荐方法。早在行业信息化之初,“推荐系统”就在很多行业中应用了,关键的是推荐的信息变得越来越有价值了,而这个变化很大程度上要归功于“推荐系统”中应用了“机器学习”中的相关算法。
三 应用“推荐系统”提高静态分析的效率
在对代码的静态分析过程中,由于存在大量类似于“啤酒同尿不湿”之间的关系,所以无法准确分析出所有缺陷之间的内在逻辑关联,因此,当测试人员发现一个编码缺陷,如果能有一个系统将同该缺陷相关的可能的其它缺陷按照出现概率的大小罗列出来,测试人员将会节省大量的代码走查时间,隐藏在代码之海中的缺陷沙粒也会大幅度减少。这很容易令我们联想起电商网站,当我们搜到一个商品,并放入购物车后,页面上的某个角落马上就会显示出同我们购买的当前商品相关联的其它数个商品。实际上这就是一个在静态分析领域的“推荐系统”,推荐算法的线索是已经发现的缺陷或者缺陷集合,推荐的内容是潜在的缺陷。前文已经介绍过,推荐算法有很多种,下面我们就以基于关联规则推荐算法为例简要介绍软件静态分析领域的推荐算法的实现过程。
1 基本概念
首先,要了解关联规则的几个概念,定义N为总事务数,N(A)、N(B)分别为项集A、项集B出现的次数,N(AB)为项集A、项集B同时出现的次数,A、B为不相交项集A∩B=Ø,规则A→B表示由A推到B。
支持度(Support):支持度是两个样本在所有事务中同时出现的概率,可以记录为P(A U B)。支持度的计算公式为A,B两各样本同时出现的次数与事务总数的比率。支持度是一种重要度量,支持度低的规则很可能是偶然现象,对推荐意义不大,另外支持度是数据剪枝的一个重要依据。
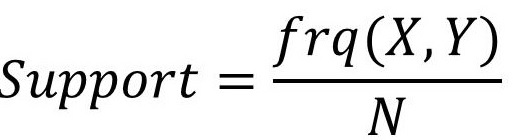
单个样本的支持度的计算方法与两个样本一样。
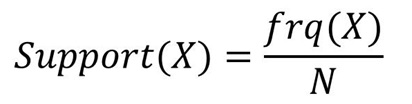
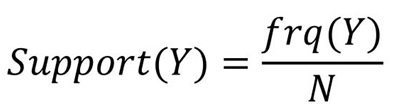
置信度(Confidence):字面上的解释就是这个规则到底有多可信,对于给定的规则A→B,置信度越高,B出现在包含A的事务中的概率越高。
置信度是一个条件概率,两个样本其中一个出现在事务中时,另一件也会出现的概率。可以记录为P(B|A)。
提升度(Lift):
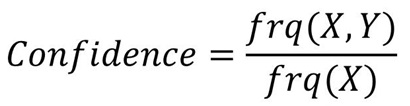
{kind=link}
{kind=link}
作用度通过衡量使用规则后的提升效果来判断规则是否可用,简单来说就是使用规则后样本在事务中出现的次数是否高于样本单独出现在事务中的频率。如果大于1说明规则有效,小于1则无效。
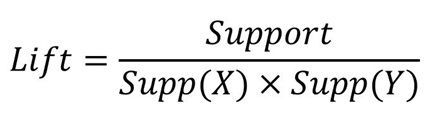
Support(A→B)其实就是AB的联合概率P(AB),Support(A) 、 Support(B)分别为A、B的概率估计P(A)、P(B),如果A、B相互独立,则P(AB) = P(A) ×P(B),所以只有 Lift > 1 才表示A、B正相关,且越大越好。
为什么要引入提升度的概念呢?还是拿歌曲来做例子,比如歌曲A、歌曲C为小众歌曲,歌曲B为口水歌,共有10万个用户,有200个人听过歌曲A,这200个人里面有60个听过口水歌B,有40个人听过歌曲C,同时听过歌曲C的人数是300,听过口水歌B的人为50000,那么Confidence(A→B) = 0.3,Confidence(A→C) = 0.2,从置信度来看貌似A和B更相关,但是10W人里面有5W听过歌曲B,说明有一半的用户都喜欢歌曲B,但听过歌曲A的人里面只有30%的人喜欢歌曲B,很明显歌曲A和歌曲B负相关,计算Lift(A→B) = 0.6,小于1,负相关,Lift(A→C) = 66.7,远大于1,正相关。
当然,还有一些其他的度量因子,在此不逐个介绍了。
2 搭建“推荐系统”
搭建过程分为三个步骤:样本收集与清理、规则提取、推荐、优化。
- 样本收集与清理
软件静态分析领域,样本指的是以次为单位的静态分析结果中的缺陷列表。按照统计学的知识,过滤掉一些极端的静态分析或者某些极少出现的缺陷。
- 规则提取
计算两两编码缺陷之间的支持度、置信度、提升度,根据最低支持度、最低置信度、最低提升度剪枝,把低于最小值的规则扔掉。
- 推荐
输入当前测试人员发现的编码缺陷,找出该缺陷对应的所有规则,按照置信度降序排序,Top-N即为和缺陷A最相关的前N个软件缺陷。
- 优化
将最新的静态分析结果数据添加到历史数据库中,重新计算规则集合用于下次测试。
四 总结
实际工程应用中通常会使用多种推荐算法的组合,根据实际应用的领域的不同为不同的算法设定相应的权值,综合各算法的结果为用户提供推荐信息。