目录

前言
本项目专注于MovieLens数据集,并采用TensorFlow中的2D文本卷积网络模型。它结合了协同过滤算法来计算电影之间的余弦相似度,并通过用户的交互方式,以单击电影的方式,提供两种不同的电影推荐方式。
首先,项目使用MovieLens数据集,这个数据集包含了大量用户对电影的评分和评论。这些数据用于训练协同过滤算法,以便推荐与用户喜好相似的电影。
其次,项目使用TensorFlow中的2D文本卷积网络模型,这个模型可以处理电影的文本描述信息。模型通过学习电影的文本特征,能够更好地理解电影的内容和风格。
当用户与小程序进行交互时,有两种不同的电影推荐方式:
-
协同过滤推荐:基于用户的历史评分和协同过滤算法,系统会推荐与用户喜好相似的电影。这是一种传统的推荐方式,通过分析用户和其他用户的行为来推荐电影。
-
文本卷积网络推荐:用户可以通过点击电影或输入文本描述,以启动文本卷积网络模型。模型会分析电影的文本信息,并推荐与输入的电影或描述相匹配的其他电影。这种方式更注重电影的内容和情节相似性。
综合来看,本项目融合了协同过滤和深度学习技术,为用户提供了两种不同但有效的电影推荐方式。这可以提高用户体验,使他们更容易找到符合他们口味的电影。
总体设计
本部分包括系统整体结构图和系统流程图。
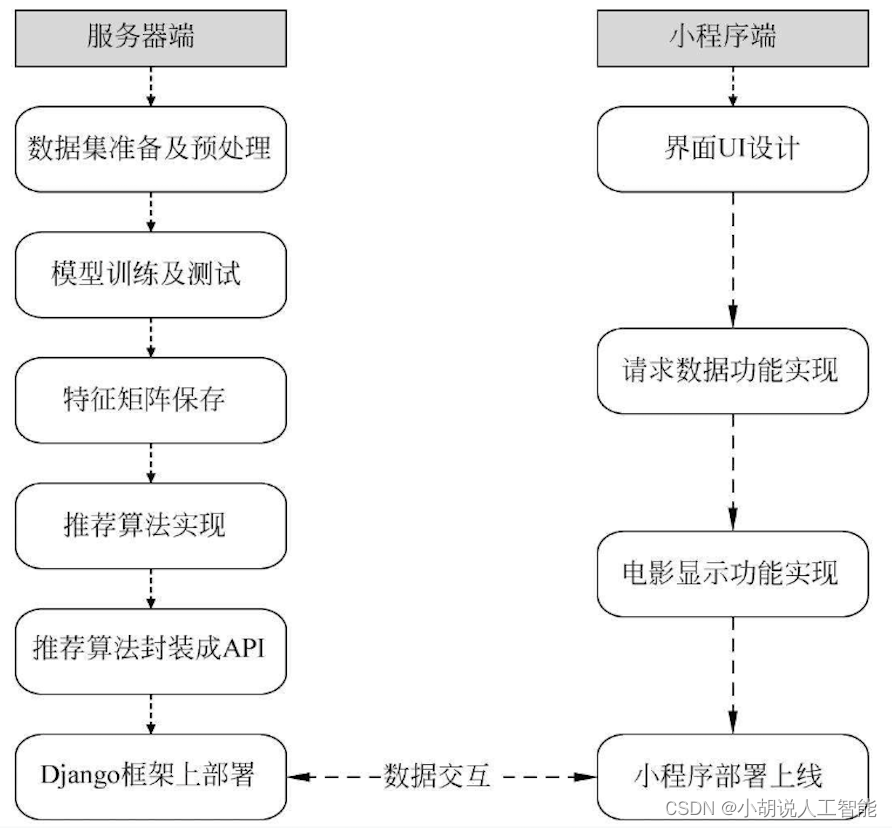
系统整体结构图
系统整体结构如图所示。
系统流程图
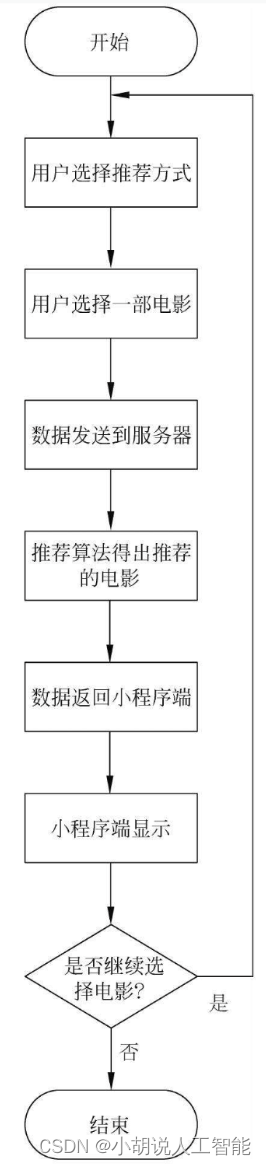
系统流程如图所示。
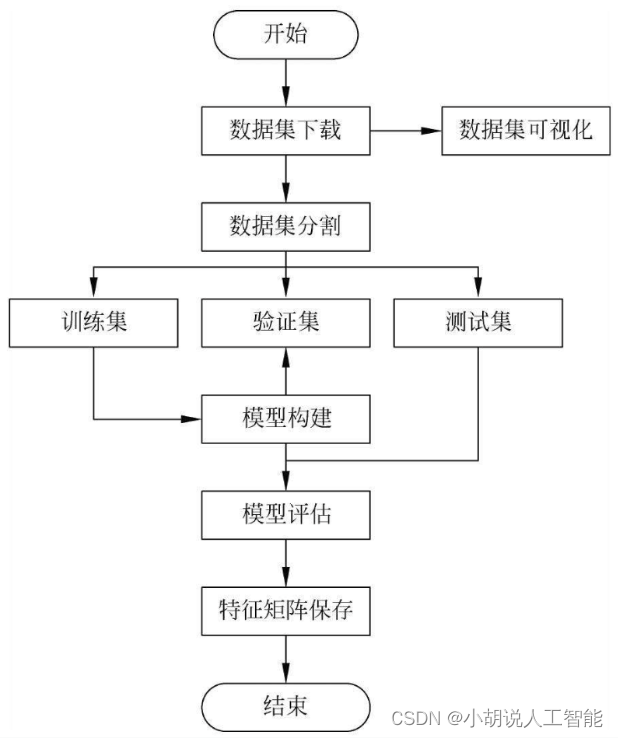
模型训练流程如图所示。
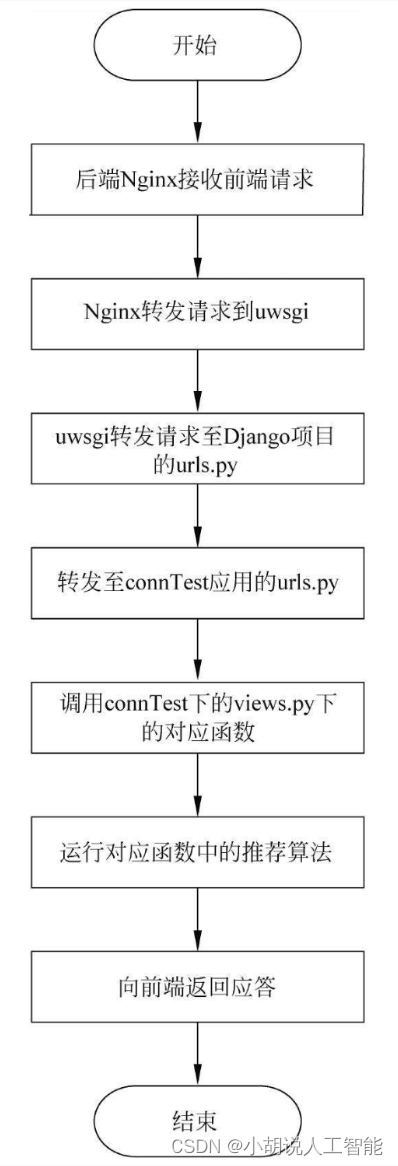
服务器运行流程如图所示。
运行环境
本部分包括Python环境、TensorFlow环境、 后端服务器、Django和微信小程序环境。
模块实现
本项目包括3个模块:模型训练、后端Django、 前端微信小程序模块,下面分别给出各模块的功能介绍及相关代码。
1. 模型训练
下载数据集,解压到项目目录下的./ml-1m文件夹下。数据集分用户数据users.dat、电影数据movies.dat和评分数据ratings.dat。
1)数据集分析
数据集网站地址为http://files.grouplens.org/datasets/movielens/ml-1m-README.txt对数据的描述。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133124641#1_44
2)数据预处理
通过研究数据集中的字段类型,发现有一些是类别字段,将其转成独热编码,但是UserID、MovieID的字段会变稀疏,输入数据的维度急剧膨胀,所以在预处理数据时将这些字段转成数字。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133124641#2_123
3)模型创建
相关博客:https://blog.csdn.net/qq_31136513/article/details/133125845#3_50
4)模型训练
相关博客:https://blog.csdn.net/qq_31136513/article/details/133130704#4_57
5)获取特征矩阵
本部分包括定义函数张量、生成电影特征矩阵、生成用户特征矩阵。
相关博客:https://blog.csdn.net/qq_31136513/article/details/133130704#5_240
2. 后端Django
该模块实现了推荐算法的封装与前端数据交互功能。Django项目mysite目录下的文件树如下:

manage.py用于控制项目各种功能; mysite与当前文件夹同名,注意区分,主要装的是项目的全局配置文件以及推荐算法用到的数据文件,同时需要在settings.py文件中设置对应文件路径;connTest是Django的应用文件夹,实施相应的功能; uwsgi.ini是配置uwsgi应用,与Nginx软件 实施数据通信功能;run.log文件 是运行日志。
1)路由文件
路由相关的文件./mysite/urls.py和./connTest/urls.py,一旦前端发起请求,服务器上的Nginx监听443端口并转发到uwsgi应用的端口8000,根据项目文件夹下的./mysite/urls.py判断路由规则。
./mysite/urls.py的相关代码如下:
from django.contrib import admin
from django.urls import include, path
urlpatterns = [
#转发至connTest应用
path('connTest/', include('connTest.urls')),
#管理功能,默认生成,不使用
path('admin/', admin.site.urls),
]
如果请求中包含connTest/,则将请求转发至应用connTest的urls.py文件,./connTest/urls.py相关代码如下:
from django.urls import path
#导入connTest下的视图层views.py
from . import views
urlpatterns = [
#请求中不包含其他字符,调用视图层中的index函数
path('', views.index, name='index'),
#请求中包含“get_rand_movies/”,调用视图层中的get_rand_movies()函数
path('get_rand_movies/',views.get_rand_movies,name='get_rand_movies'),
#请求中包含“get_this_movie/”,调用视图层中的get_this_movie()函数
path('get_this_movie/', views.get_this_movie, name='get_this_movie'),
#请求中包含“post_st_movies/”,调用视图层中的post_st_movies()函数
path('post_st_movies/', views.post_st_movies, name='post_st_movies'),
#请求中包含“post_of_movies/”,调用视图层中的post_of_movies()函数
path('post_of_movies/',views.post_of_movies,name='post_of_movies'),
]
如果请求中有对应的字符串,则转发至相应的处理函数。
2)视图层文件
路由文件将请求转发到相应的视图层文件函数中,connTest应用的视图层文件views.py的相关代码如下:
#用于返回应答
from django.http import HttpResponse
#自定义文件my_data.py,用于封装推荐算法函数
from . import my_data
#路径
import os
#特征向量文件所在目录所需文件settings.PROJECT
from django.conf import settings
#处理json文件,API返回格式为json
import json
#index函数,接收视图层请求,此函数用于测试,推荐算法中不使用
def index(request):
#如果请求方法是POST
if(request.method == 'POST'):
data = request.POST['choice']
#返回get_random_movies()结果
rand_movies_list=my_data.get_random_movies(settings.PROJECT_ROOT)
results = {
}
for i in range(5):
result = {
}
result['movie_id'] = rand_movies_list[i][0]
result['movie_name'] = rand_movies_list[i][1]
result['movie_genres'] = rand_movies_list[i][2]
results[str(i)] = result
results = json.dumps(results)
return HttpResponse(results)
elif(request.method == 'GET'):
#如果请求方法是GET
return HttpResponse("Hello,this is connTest index.")
#get_rand_movies函数,接收视图层请求,返回5个随机电影
def get_rand_movies(request):
#调用my_data中的get_rand_movies()函数,获得电影
rand_movies_list = my_data.get_random_movies(settings.PROJECT_ROOT)
results = {
}
#遍历list化成dict
for i in range(5):
result = {
}
result['movie_id'] = rand_movies_list[i][0]
result['movie_name'] = rand_movies_list[i][1]
result['movie_genres'] = rand_movies_list[i][2]
results[str(i)] = result
#转化为json格式
results = json.dumps(results)
#返回应答
return HttpResponse(results)
#get_this_movie函数,接收视图层请求,返回电影相关信息,系统中未使用,仅做测试使用
def get_this_movie(request):
#POST请求,接收参数movie_id
movie_id = request.POST['movie_id']
movie_id = int(movie_id)
#调用my_data中的get_a_movie()函数,获得电影
this_movie_data = my_data.get_a_movie(settings.PROJECT_ROOT,movie_id)
#转化成dict
results = {
}
result = {
}
result['movie_id'] = this_movie_data[0]
result['movie_name'] = this_movie_data[1]
result['movie_genres'] = this_movie_data[2]
results["0"] = result
#转化成json格式
results = json.dumps(results)
#返回应答
return HttpResponse(results)
#post_st_movies()函数,接收视图层请求,返回某个电影的同种电影
def post_st_movies(request):
#接收POST请求参数
movie_id = request.POST['movie_id']
movie_id = int(movie_id)
#调用my_data中的recommend_same_type_movie()函数,获得同种电影列表
st_movies_list = my_data.recommend_same_type_movie(settings.PROJECT_ROOT,movie_id)
#list化成dict
results = {
}
for i in range(5):
result = {
}
result['movie_id'] = st_movies_list[i][0]
result['movie_name'] = st_movies_list[i][1]
result['movie_genres'] = st_movies_list[i][2]
results[str(i)] = result
#转化成json格式
results = json.dumps(results)
#返回应答
return HttpResponse(results)
#post_of_movies函数,接收视图层请求,返回看过某个电影的人喜欢的电影
def post_of_movies(request):
#接收POST请求参数
movie_id = request.POST['movie_id']
movie_id = int(movie_id)
#调用my_data中的recommend_other_favorite_movie ()函数,获得电影列表
of_movies_list = my_data.recommend_other_favorite_movie(settings.PROJECT_ROOT,movie_id)
#list转化成dict
results = {
}
for i in range(5):
result = {
}
result['movie_id'] = of_movies_list[i][0]
result['movie_name'] = of_movies_list[i][1]
result['movie_genres'] = of_movies_list[i][2]
results[str(i)] = result
#转化成json格式
results = json.dumps(results)
#返回应答
return HttpResponse(results)
实现推荐算法文件my_data.py相关代码如下:
#导入需要用到的包
import pandas as pd
import numpy as np
import pickle
import random
import os
#get_random_movies函数返回5个随机电影
def get_random_movies(PROJECT_ROOT):
#读取数据
title_count, title_set, genres2int, features, targets_values, ratings, users, movies, data, movies_orig, users_orig = pickle.load(open(os.path.join(PROJECT_ROOT,'preprocess.p'), mode='rb'))
#随机5个索引
random_movies = [random.randint(0,3833) for i in range(5)]
#返回电影数据列表
return movies_orig[random_movies]
#get_a_movie函数,参数电影ID对应信息
def get_a_movie(PROJECT_ROOT,movie_id):
title_count, title_set, genres2int, features, targets_values, ratings, users, movies, data, movies_orig, users_orig = pickle.load(open(os.path.join(PROJECT_ROOT,'preprocess.p'), mode='rb'))
#电影ID转下标的字典,数据集中电影ID跟下标不一致,例如,第5行的数据电影ID不一定是5
movieid2idx = {
val[0]:i for i, val in enumerate(movies.values)}
this_movie_data = movies_orig[movieid2idx[movie_id]]
return this_movie_data
#recommend_same_type_movie函数返回同种类电影列表
def recommend_same_type_movie(PROJECT_ROOT,movie_id_val, top_k=20):
#读取数据
title_count, title_set, genres2int, features, targets_values, ratings, users, movies, data, movies_orig, users_orig = pickle.load(open(os.path.join(PROJECT_ROOT,'preprocess.p'), mode='rb'))
#电影ID转下标的字典,数据集中电影ID跟下标不一致,例如,第5行的数据电影ID不一定是5
movieid2idx = {
val[0]:i for i, val in enumerate(movies.values)}
#读取电影特征矩阵 movie_matrics=pickle.load(open(os.path.join(PROJECT_ROOT,'movie_matrics.p'), mode='rb'))
#读取用户特征矩阵
users_matrics = pickle.load(open(os.path.join(PROJECT_ROOT,'users_matrics.p'), mode='rb'))
#推荐与选择
同类型的电影
print("您选择的电影是:{}".format(movies_orig[movieid2idx[movie_id_val]]))
#规范化电影特征矩阵
norm_movie_matrics = np.sqrt(np.sum(np.square(movie_matrics),axis=1)).reshape(3883,1)
normalized_movie_matrics = movie_matrics/norm_movie_matrics
#获取所选电影特征向量
probs_embeddings = (movie_matrics[movieid2idx[movie_id_val]]).reshape([1, 200])
probs_embeddings = probs_embeddings/np.sqrt(np.sum(np.square(probs_embeddings)))
#计算相似度
probs_similarity = np.matmul(probs_embeddings, np.transpose(normalized_movie_matrics))
#print("根据您看的电影类型给您的推荐:")
p = np.squeeze(probs_similarity)
#获取topk个电影
p[np.argsort(p)[:-top_k]] = 0
p = p / np.sum(p)
results = set()
#在topk个电影汇总选取5个
while len(results) != 5:
c = np.random.choice(3883, 1, p=p)[0]
results.add(c)
final_results = [movies_orig[val] for val in results]
#返回电影列表
return final_results
#recommend_other_favorite_movie函数,返回看过同一个电影的人喜欢的电影
def recommend_other_favorite_movie(PROJECT_ROOT,movie_id_val, top_k=20):
#读取数据
title_count, title_set, genres2int, features, targets_values, ratings, users, movies, data, movies_orig, users_orig = pickle.load(open(os.path.join(PROJECT_ROOT,'preprocess.p'), mode='rb'))
#电影ID转下标的字典,数据集中电影ID跟下标不一致,例如,第5行的数据电影ID不一定是5
movieid2idx = {
val[0]:i for i, val in enumerate(movies.values)}
#读取电影特征与用户特征矩阵
movie_matrics = pickle.load(open(os.path.join(PROJECT_ROOT,'movie_matrics.p'), mode='rb'))
users_matrics = pickle.load(open(os.path.join(PROJECT_ROOT,'users_matrics.p'), mode='rb'))
#推荐看过同一个的电影的人喜欢的电影
print("您看的电影是:{}".format(movies_orig[movieid2idx[movie_id_val]]))
#根据电影寻找相似的人
probs_movie_embeddings = (movie_matrics[movieid2idx[movie_id_val]]).reshape([1, 200])
probs_movie_embeddings = probs_movie_embeddings/np.sqrt(np.sum(np.square(probs_movie_embeddings)))
norm_users_matrics = np.sqrt(np.sum(np.square(users_matrics),axis=1)).reshape(6040,1)
normalized_users_matrics = users_matrics/norm_users_matrics
#计算相似度
probs_user_favorite_similarity = np.matmul(probs_movie_embeddings, np.transpose(normalized_users_matrics))
favorite_user_id = np.argsort(probs_user_favorite_similarity)[0][-top_k:]
print("喜欢看这个电影的人是:{}".format(users_orig[favorite_user_id-1]))
#他们喜欢什么样的电影
probs_users_embeddings = (users_matrics[favorite_user_id-1]).reshape([-1, 200])
probs_users_embeddings = probs_users_embeddings/np.sqrt(np.sum(np.square(probs_users_embeddings)))
norm_movie_matrics = np.sqrt(np.sum(np.square(movie_matrics),axis=1)).reshape(3883,1)
normalized_movie_matrics = movie_matrics/norm_movie_matrics
#计算相似度
probs_similarity = np.matmul(probs_users_embeddings, np.transpose(normalized_movie_matrics))
p = np.argmax(probs_similarity, 1)
#print("喜欢看这个电影的人还喜欢看:")
results = set()
#随机选取5个
while len(results) != 5:
c = p[random.randrange(top_k)]
results.add(c)
final_results = [movies_orig[val] for val in results]
return final_results
3)项目设置文件
项目设置在1/mytesttinspy文件中,相关代码如下:
#用于路径
import os
#默认设置
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
SECRET_KEY = '' #项目的秘钥,这里不显示
DEBUG = False
#允许接入的用户,通常填写域名,例如:
#ALLOWED_HOSTS = ['www.baidu.com']
ALLOWED_HOSTS = ['’] # 这里不显示
#Application definition
INSTALLED_APPS = [
#添加应用connTest
'connTest',
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
]
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
#如果报错,直接注释掉即可
#'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
ROOT_URLCONF = 'mysite.urls'
PROJECT_ROOT = os.path.abspath(os.path.dirname(__file__))
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, 'templates')],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
WSGI_APPLICATION = 'mysite.wsgi.application'
#数据库
#参考https://docs.djangoproject.com/en/2.2/ref/settings/#databases
#数据库在这更换,此处未用到数据库,所以不需更换
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
#密码验证
AUTH_PASSWORD_VALIDATORS = [
{
'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
},
{
'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
},
]
#语言
LANGUAGE_CODE = 'en-us'
#时区
TIME_ZONE = 'UTC'
USE_I18N = True
USE_L10N = True
USE_TZ = True
STATIC_URL = '/static/'
相关其它博客
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(一)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(二)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(三)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(四)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(六)
基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(七)
工程源代码下载
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。