背景:
RNN(Recurrent Neural Network)是一类用于处理序列数据的神经网络。首先我们要明确什么是序列数据,摘取百度百科词条:时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。这是时间序列数据的定义,当然这里也可以不是时间,比如文字序列,但总归序列数据有一个特点——后面的数据跟前面的数据有关系。
无论是卷积神经网络,还是人工神经网络,他们的前提假设都是:元素之间是相互独立的,输入与输出也是独立的,但现实世界中,很多元素都是相互连接的,可以根据上下文的内容推断出来的,因此,就有了现在的循环神经网络,他的本质是:像人一样拥有记忆的能力。因此,他的输出就依赖于当前的输入和记忆。
从基础的神经网络中知道,神经网络包含输入层、隐层、输出层,通过激活函数控制输出,层与层之间通过权值连接。激活函数是事先确定好的,那么神经网络模型通过训练“学“到的东西就蕴含在“权值“中。
基础的神经网络只在层与层之间建立了权连接,RNN最大的不同之处就是在层之间的神经元之间也建立的权连接。
网络结构及原理:

RNN是一个序列到序列的模型,定义:
因为我们当前时刻的输出是由记忆和当前时刻的输出决定的,因此就定义了RNN的基础:

加一个f()函数,其实这个函数是神经网络中的激活函数,但为什么要加上它呢?
举个例子,假如你在大学学了非常好的解题方法,那你初中那时候的解题方法还要用吗?显然是不用了的。RNN的想法也一样,既然我能记忆了,那我当然是只记重要的信息啦,其他不重要的,就肯定会忘记,是吧。但是在神经网络中什么最适合过滤信息呀?肯定是激活函数嘛,因此在这里就套用一个激活函数,来做一个非线性映射,来过滤信息,这个激活函数可能为tanh,也可为其他。
很显然RNN预测的时候带着当前时刻的记忆St去预测。假如你要预测“我是中国“的下一个词出现的概率,这里已经很显然了,运用softmax来预测每个词出现的概率再合适不过了,但预测不能直接带用一个矩阵来预测呀,所有预测的时候还要带一个权重矩阵V,用公式表示为:

其中Ot就表示时刻t的输出。和卷积神经网络一样,这里的网络中每个cell都共享了一组参数(U,V,W),这样就能极大的降低计算量了。
RNN的改进1:双向RNN
RNN既然能继承历史信息,是不是也能吸收点未来的信息呢?因为在序列信号分析中,如果我能预知未来,对识别一定也是有所帮助的。因此就有了双向RNN、双向LSTM,同时利用历史和未来的信息。


对于正向RNN最后一个向量中记录的信息量从前往后依次增强,反向的最后一个state记录的信息从后往前依次增强,两者组合正好记录了比较完整的信息。
RNN的改进2:深层双向RNN、Pyramidal RNN
RNN的训练-BPTT:
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。BPTT的中心思想和BP算法相同,沿着需要优化的参数的负梯度方向不断寻找更优的点直至收敛。
如前面我们讲的,如果要预测t时刻的输出,我们必须先利用上一时刻(t-1)的记忆和当前时刻的输入,得到t时刻的记忆:

为了找出模型最好的参数,U,W,V,我们就要知道当前参数得到的结果怎么样,因此就要定义我们的损失函数,用交叉熵损失函数:

其中yt是t时刻的标准答案,是一个只有一个是1,其他都是0的向量;y^t是我们预测出来的结果,与yt的维度一样,但它是一个概率向量,里面是每个词出现的概率。因为对结果的影响,肯定不止一个时刻,因此需要把所有时刻的造成的损失都加起来:

定义好了损失函数,接下来就是熟悉的一步了,那就是根据损失函数利用SGD来求解最优参数,在CNN中使用反向传播BP算法来求解最优参数,但在RNN就要用到BPTT,它和BP算法的本质区别,也是CNN和RNN的本质区别:CNN没有记忆功能,它的输出仅依赖与输入,但RNN有记忆功能,它的输出不仅依赖与当前输入,还依赖与当前的记忆。这个记忆是序列到序列的,也就是当前时刻收到上一时刻的影响。
因此,在对参数求偏导的时候,对当前时刻求偏导,一定会涉及前一时刻,我们用例子看一下:
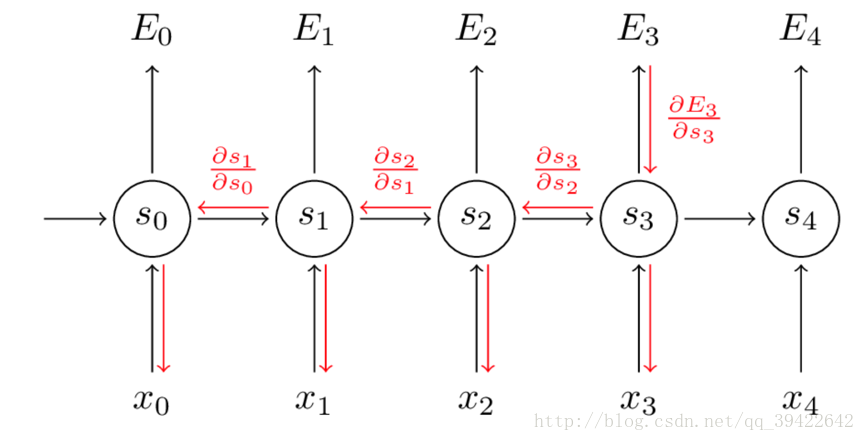
假设我们对E3的W求偏导:它的损失首先来源于预测的输出y^3,预测的输出又是来源于当前时刻的记忆s3=tanh(Ux3+Ws2)
因此,根据链式法则可以有:

我们要把当前时刻造成的损失,和以往每个时刻造成的损失加起来,因为我们每一个时刻都用到了权重参数W。和以往的网络不同,一般的网络,比如人工神经网络,参数是不同享的,但在循环神经网络,和CNN一样,设立了参数共享机制,来降低模型的计算量。
这个式子看起来简单但是求解起来很容易出错,因为其中嵌套着激活函数函数,是复合函数的求道过程。如果我们把激活函数放进去,拿出中间累乘的那部分,会发现累乘会导致激活函数导数的累乘,进而会导致“梯度消失“和“梯度爆炸“现象的发生。
至于为什么,我们先来看看这两个激活函数的图像。
这是sigmoid函数的函数图和导数图。 
这是tanh函数的函数图和导数图。 
它们二者是何其的相似,都把输出压缩在了一个范围之内。他们的导数图像也非常相近,我们可以从中观察到,sigmoid函数的导数范围是(0,0.25],tach函数的导数范围是(0,1],他们的导数最大都不大于1。
这就会导致一个问题,在上面式子累乘的过程中,如果取sigmoid函数作为激活函数的话,那么必然是一堆小数在做乘法,结果就是越乘越小。随着时间序列的不断深入,小数的累乘就会导致梯度越来越小直到接近于0,这就是“梯度消失“现象。其实RNN的时间序列与深层神经网络很像,在较为深层的神经网络中使用sigmoid函数做激活函数也会导致反向传播时梯度消失,梯度消失就意味消失那一层的参数再也不更新,那么那一层隐层就变成了单纯的映射层,毫无意义了,所以在深层神经网络中,有时候多加神经元数量可能会比多加深度好。
解决“梯度消失“的方法主要有:
1、选取更好的激活函数
2、改变传播结构
关于第一点,一般选用ReLU函数作为激活函数,ReLU函数的图像为: 
ReLU函数的左侧导数为0,右侧导数恒为1,这就避免了“梯度消失“的发生。但恒为1的导数容易导致“梯度爆炸“,但设定合适的阈值可以解决这个问题。还有一点就是如果左侧横为0的导数有可能导致把神经元学死,不过设置合适的步长(学习旅)也可以有效避免这个问题的发生。
关于第二点,LSTM结构可以解决这个问题。
总结一下,sigmoid函数的缺点:
1、导数值范围为(0,0.25],反向传播时会导致“梯度消失“。tanh函数导数值范围更大,相对好一点。
2、sigmoid函数不是0中心对称,tanh函数是,可以使网络收敛的更好。
LSTM
长短期记忆网络是RNN的一种变体,RNN由于梯度消失的原因只能有短期记忆,LSTM网络通过精妙的门控制将短期记忆与长期记忆结合起来,并且一定程度上解决了梯度消失的问题。
Long Short Term 网络—— 一般就叫做 LSTM ——是一种 RNN 特殊的类型,可以学习长期依赖信息。LSTM 由Hochreiter & Schmidhuber (1997)提出,并在近期被Alex Graves进行了改良和推广。在很多问题,LSTM 都取得相当巨大的成功,并得到了广泛的使用。
LSTM 通过刻意的设计来避免长期依赖问题。记住长期的信息在实践中是 LSTM 的默认行为,而非需要付出很大代价才能获得的能力!

LSTM重点有三个门:
- 输入门:input是否写入Memory
- 输出门:是否从Memory中读取
- 遗忘门:是否遗忘数据并清除
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。

LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,整体上除了h在随时间流动,细胞状态c也在随时间流动,细胞状态c就代表着长期记忆。 
不必担心这里的细节。我们会一步一步地剖析 LSTM 解析图。现在,我们先来熟悉一下图中使用的各种元素的图标。 
- 黄色的矩形是学习得到的神经网络层
- 粉色的圆形表示一些运算操作,诸如加法乘法
- 黑色的单箭头表示向量的传输
- 两个箭头合成一个表示向量的连接
- 一个箭头分开表示向量的复制
LSTM 的核心思想
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。
细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。 
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。

Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!
LSTM 拥有三个门,来保护和控制细胞状态。
逐步理解 LSTM
在我们 LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。这个决定通过一个称为遗忘门完成。该门会读取ht−1ht−1和xtxt,输出一个在 0 到 1 之间的数值给每个在细胞状态Ct−1Ct−1 中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
让我们回到语言模型的例子中来基于已经看到的预测下一个词。在这个问题中,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。 
这里可以抛出两个问题:这个门怎么做到“遗忘“的呢?怎么理解?既然是遗忘旧的内容,为什么这个门还要接收新的xtxt?
对于第一个问题,“遗忘“可以理解为“之前的内容记住多少“,其精髓在于只能输出(0,1)小数的sigmoid函数和粉色圆圈的乘法,LSTM网络经过学习决定让网络记住以前百分之多少的内容。对于第二个问题就更好理解,决定记住什么遗忘什么,其中新的输入肯定要产生影响。
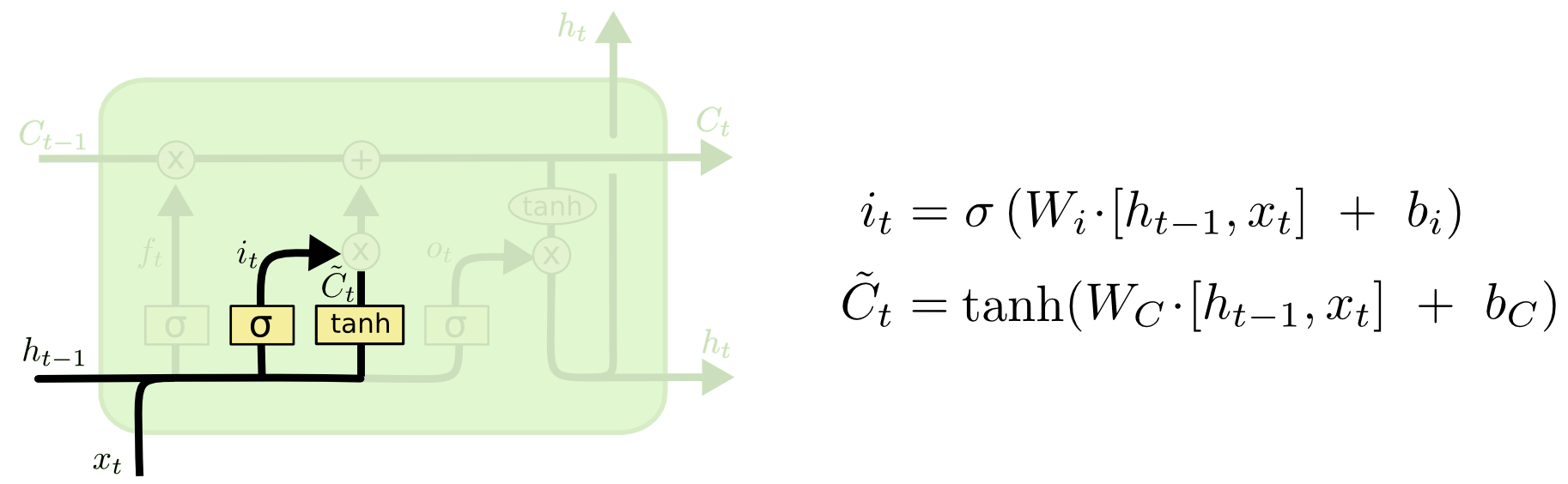
下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量,C~tC~t,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
在我们语言模型的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。
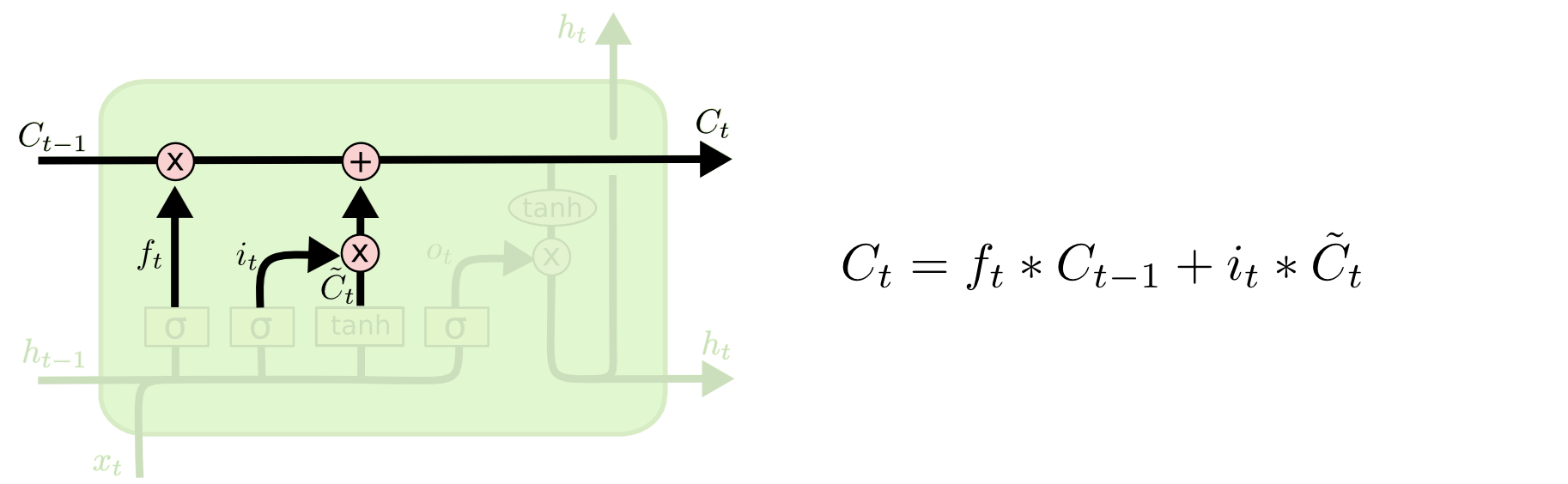
我们把旧状态与ft相乘,丢弃掉我们确定需要丢弃的信息。接着加上it*Ct~。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
有了上面的理解基础输入门,输入门理解起来就简单多了。sigmoid函数选择更新内容,tanh函数创建更新候选。
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
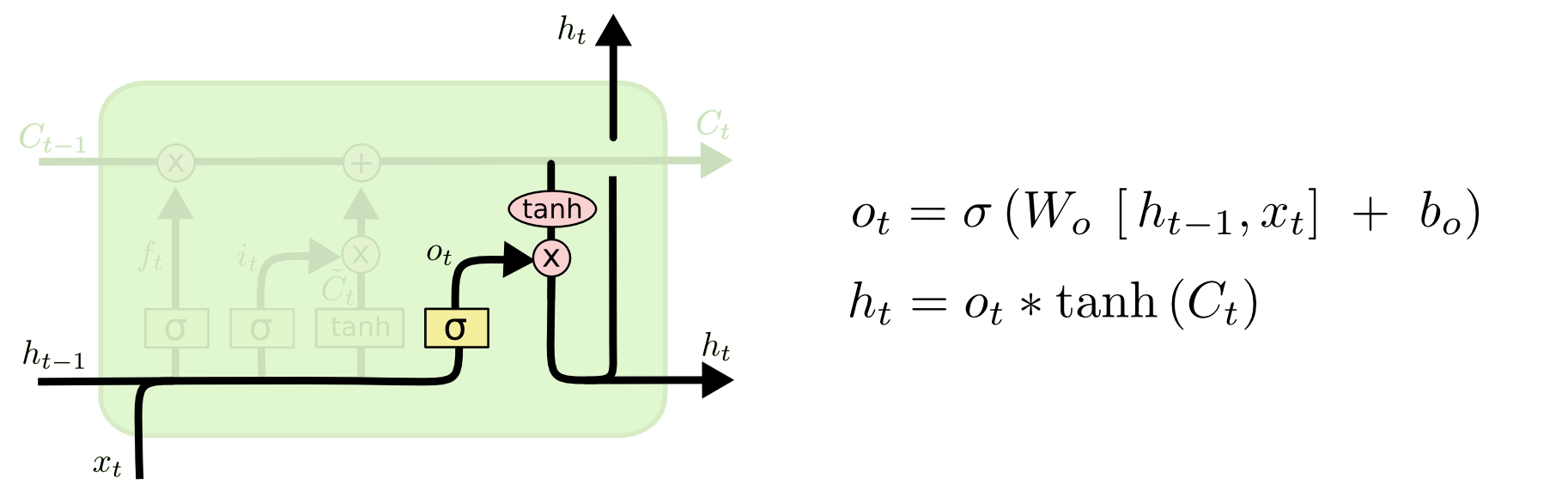
这三个门虽然功能上不同,但在执行任务的操作上是相同的。他们都是使用sigmoid函数作为选择工具,tanh函数作为变换工具,这两个函数结合起来实现三个门的功能。
RNN与CNN的结合应用:看图说话
在图像处理中,目前做的最好的是CNN,而自然语言处理中,表现比较好的是RNN,因此,我们能否把他们结合起来,一起用呢?那就是看图说话了,这个原理也比较简单,举个小栗子:假设我们有CNN的模型训练了一个网络结构,比如是这个

最后我们不是要分类嘛,那在分类前,是不是已经拿到了图像的特征呀,那我们能不能把图像的特征拿出来,放到RNN的输入里,让他学习呢?
之前的RNN是这样的:

我们把图像的特征加在里面,可以得到:

RNNs能干什么:
语言模型与文本生成、机器翻译(Machine Translation)、语音识别(Speech Recognition)
图像描述生成 (Generating Image Descriptions)
参考:https://blog.csdn.net/zhaojc1995/article/details/80572098
https://blog.csdn.net/qq_39422642/article/details/78676567