最近一个生产库挂了,通过后台日志分析截图如下:
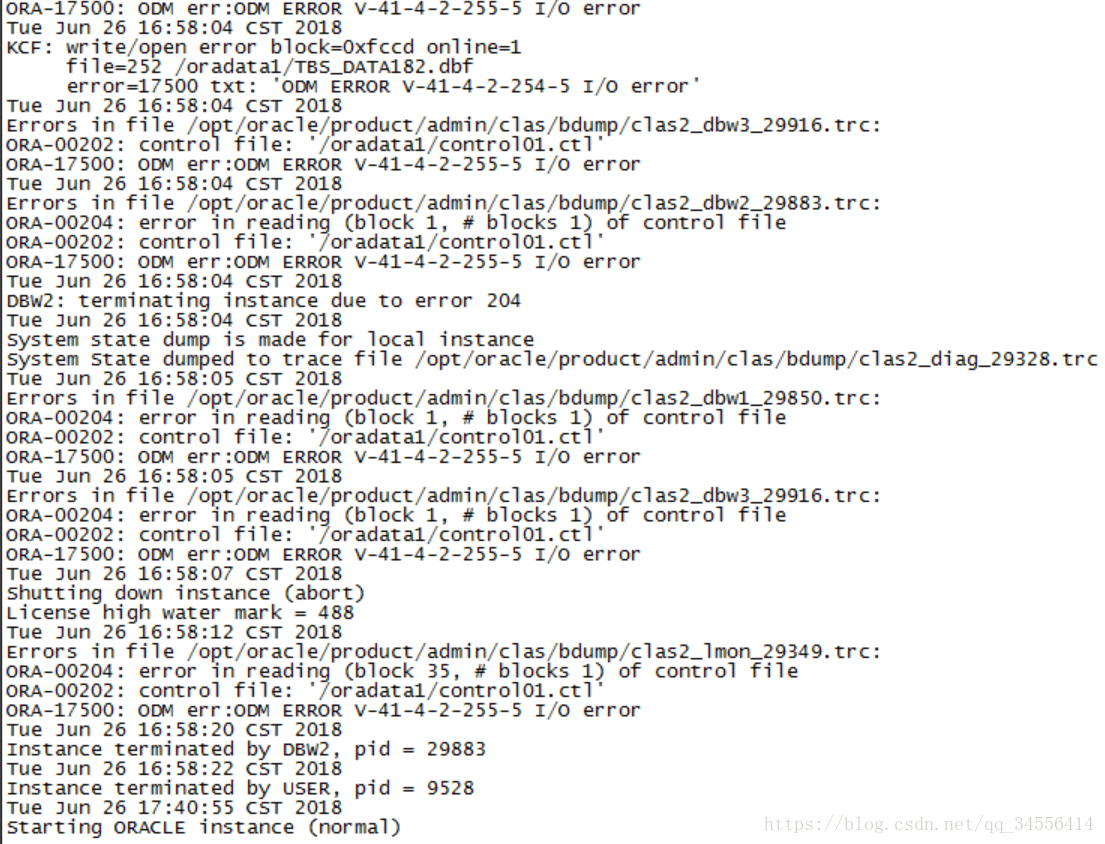
数据库挂了的原因是因为数据库的文件系统对应的磁盘全部掉了,但是看到后台日志ORA-00204这个错误,还是百度了一下
看到杨长老的文章,于是收入到自己博客,下面的故障时在RAC下面添加磁盘不当导致数据库宕了。
这是一则生产环境的真实维护过程,由于RAC的测试环境空间不足,因此规划给ASM扩展空间,然而在给ASM添加新的磁盘空间时又出现了故障,这类问题在很多用户的生产环境中可能也会遇到。
空间扩展的操作步骤如下:
在RAC环境的节点1上启动了DBCA工具来管理ASM设备;
由于新增的裸设备在ASM图形界面下看不到;
通过root用户将裸设备的访问权限授予了操作系统上的Oracle用户;
这时,从图形界面的候选磁盘中已经可以看到这些裸设备了;
通过图形界面将裸设备加到了磁盘组中。
但是这个操作引发了两个错误:分别是ORA-15032和ORA-15075。
首先看看在Oracle官方文档上是如何描述这两个错误的:
ORA-15032: not all alterations performed
Cause: At least one ALTER DISKGROUP action failed.
Action: Check the other messages issued along with this summary error.
ORA-15075: disk(s) are not visible cluster-wide
Cause: An ALTER DISKGROUP ADD DISK command specified a disk that could not be discoveredby one or more nodes in a RAC cluster configuration.
Action: Determine which disks are causing the problem from the GV$OSM_DISK fixedview. Check operating system permissions for the device and the storage sub-systemconfiguration on each node in a RAC cluster that cannot identify the disk.
其实ORA-15075错误中的信息已经足够明显了。根据这个错误进行分析应该就能很快找到问题的原因。但是由于发生了其他的意外,导致解决问题的方向发生了偏差。
这个错误导致了奇怪的现象:根据错误信息判断,操作已经失败了,但是检查发现这些裸设备在DBCA的ASM配置中已经可见了。
当正在检查这两个错误信息时,同事告诉我节点2上的实例连不上了。
通过操作系统命令检查发现数据库实例2已经关闭了,不过这个节点上的ASM实例仍然存在。
这个现象的怪异之处在于:对ASM的操作引起的错误,当前ASM实例没有出错,却有另外一个数据库实例被关闭。
检查alert文件如下,显著的信息显示是控制文件访问出错:
$ tail -500 alert*
List of nodes:
……
Thu Mar 29 17:25:36 2007
SUCCESS: disk DISK_0017(17.4042303525) added to diskgroup DISK
SUCCESS: disk DISK_0018(18.4042303520) added to diskgroup DISK
SUCCESS: disk DISK_0019(19.4042303521) added to diskgroup DISK
SUCCESS: disk DISK_0020(20.4042303522) added to diskgroup DISK
SUCCESS: disk DISK_0021(21.4042303523) added to diskgroup DISK
SUCCESS: disk DISK_0022(22.4042303524) added to diskgroup DISK
Thu Mar 29 17:29:45 2007
SUCCESS: diskgroup DISKwas dismounted
SUCCESS: diskgroup DISKwas dismounted
Thu Mar 29 17:29:46 2007
Errors in file /data/oracle/admin/testrac/bdump/testrac2_lmon_2789.trc:
ORA-00202: control file:'+DISK/testrac/control01.ctl'
ORA-15078: ASM diskgroupwas forcibly dismounted
Thu Mar 29 17:29:46 2007
LMON: terminating instancedue to error 204
Thu Mar 29 17:29:46 2007
Errors in file /data/oracle/admin/testrac/bdump/testrac2_pmon_2754.trc:
ORA-00204: error in reading(block , # blocks ) of control file
Thu Mar 29 17:29:46 2007
System state dump ismade for local instance
Thu Mar 29 17:29:46 2007
Errors in file /data/oracle/admin/testrac/bdump/testrac2_lms1_2797.trc:
ORA-00204: error in reading(block , # blocks ) of control file
Thu Mar 29 17:29:46 2007
Errors in file /data/oracle/admin/testrac/bdump/testrac2_lms0_2793.trc:
ORA-00204: error in reading(block , # blocks ) of control file
System State dumped totrace file /data/oracle/admin/testrac/bdump/testrac2_diag_2756.trc
Thu Mar 29 17:29:47 2007
Errors in file /data/oracle/admin/testrac/bdump/testrac2_j001_677.trc:
ORA-00204: 读取控制文件时出错(块 , # 块 )
Thu Mar 29 17:29:47 2007
Errors in file /data/oracle/admin/testrac/bdump/testrac2_j000_3675.trc:
ORA-00204: 读取控制文件时出错(块 , # 块 )
Thu Mar 29 17:29:47 2007
Errors in file /data/oracle/admin/testrac/bdump/testrac2_rbal_2982.trc:
ORA-00204: error in reading(block , # blocks ) of control file
Thu Mar 29 17:29:52 2007
Instance terminated by LMON, pid = 2789
尝试重启系统,看看会产生何种错误信息,这一次看到的显示信息居然又是参数文件的读取错误:
$ sqlplus "/ as sysdba"
已连接到空闲例程。
SQL> startup
ORA-01078: failure inprocessing system parameters
ORA-01565: error in identifyingfile '+DISK/testrac/spfiletestrac.ora'
ORA-17503: ksfdopn:2Failed to open file +DISK/testrac/spfiletestrac.ora
ORA-15077: could notlocate ASM instance serving a required diskgroup
SQL> shutdown
ORA-01034: ORACLE notavailable
ORA-27101: shared memory realm does not exist
SVR4 Error: 2: No such file or directory
那么到底是怎么回事呢?如果仔细一行一行来分析告警日志,其实这时alert文件中已经明显包含了导致错误的原因:
SUCCESS: diskgroup DISK was dismounted
SUCCESS: diskgroup DISK was dismounted
Thu Mar 29 17:29:46 2007
Errors in file /data/oracle/admin/testrac/bdump/testrac2_lmon_2789.trc:
ORA-00202: control file:'+DISK/testrac/control01.ctl'
ORA-15078: ASM diskgroupwas forcibly dismounted
Thu Mar 29 17:29:46 2007
Errors in file /data/oracle/admin/testrac/bdump/testrac2_lmon_2789.trc:
ORA-00204: error in reading(block 35, # blocks 1) of control file
ORA-00202: control file:'+DISK/testrac/control01.ctl'
ORA-15078: ASM diskgroup was forcibly dismounted
ASM的磁盘组首先已经DISMOUNT了,所以后面对于ASM中文件的访问当然会出现问题,只不过我们在阅读日志时,注意力很容易被明显、易懂、熟悉的吸引,往往就忽略了真实的问题所在,这就是人的选择性注意力关注吧:
Errors in file /data/oracle/admin/testrac/bdump/testrac2_j001_677.trc:
ORA-00204: 读取控制文件时出错(块 , # 块 )
Thu Mar 29 17:29:47 2007
Errors in file /data/oracle/admin/testrac/bdump/testrac2_j000_3675.trc:
ORA-00204: 读取控制文件时出错(块 , # 块 )
Thu Mar 29 17:29:47 2007
Errors in file /data/oracle/admin/testrac/bdump/testrac2_rbal_2982.trc:
ORA-00204: error in reading(block , # blocks ) of control file
Thu Mar 29 17:29:52 2007
Instance terminated by LMON, pid = 2789
看到这个ORA-204错误信息,想当然地认为这是导致问题的原因。
其实如果查看随后的启动报错信息就可以看出问题:
ORA-15077: could not locate ASM instance serving a requireddiskgroup。
Oracle官方文档对这个错误的描述为:
ORA-15077: could not locateASM instance serving a required diskgroup
Cause: The instance failed to perform the specified operation because it could notlocate a required ASM instance.
Action: Start an ASM instance and mount the required diskgroup.
在遇到这个案例时,还同时遭遇了另外一个思维陷阱:此前刚刚碰到一个Bug,这个Bug的关键报错信息恰好也是 ORA-17503: ksfdopn:2 Failed to open file +DISK/testrac/spfiletestrac.ora。于是忽略了以上的关键信息,而把关注点转移到Bug上,并认为这次碰到的问题可能和上次有关。
参数文件不能读取,怎么办呢?当时就去尝试使用本地pfile文件启动数据库:
SQL> startup pfile=/export/home/oracle/inittestrac2.ora
ORACLE 例程已经启动。
Total System Global Area 2147483648 bytes
Fixed Size 2030296 bytes
Variable Size 503317800 bytes
Database Buffers 1627389952 bytes
Redo Buffers 14745600 bytes
ORA-00205: ?????????, ??????, ???????
出现了报错后,又一次被误导,去检查ORA-00205报错信息。
ORA-00205: error in identifying control file, check alert log for more info
Cause: The system could not find a control file of the specified name and size.
Action: Check that ALL control files are online and that they are the same filesthat the system created at cold start time.
直到发现控制文件本身并没有问题—实例1一直正常运行。这时才意识到自己“误入歧途”。
仔细检查所有的报错信息以及导致错误产生的原因——添加磁盘组的操作,终于发现了问题的真正原因:当时在给裸设备授权的时候,只在节点1进行了授权,而没有在节点2进行授权,因此节点1上的DBCA配置的ASM实例可以成功地将裸设备加到磁盘组中,而在节点2上同样的操作由于缺少权限,导致了磁盘组DISMOUNT,最终导致了数据库实例的关闭。
于是在节点2上对裸设备进行授权,重启ASM实例,问题解决。
$ su -
Password:
Sun Microsystems Inc. SunOS 5.8 Generic Patch October 2001
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad6s1
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad6s3
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad6s4
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad6s5
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad6s6
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad6s7
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad7s1
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad7s3
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad7s4
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad7s5
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad7s6
# chown oracle:oinstall/dev/rdsk/c2t500601603022E66Ad7s7
$ sqlplus "/ assysdba"
SQL> shutdown
ORA-01507: 未装载数据库
ORACLE 例程已经关闭。
$ srvctl stop asm -nracnode2
$ srvctl start asm -nracnode2
$ sqlplus "/ assysdba"
已连接到空闲例程。
SQL> startup
ORACLE 例程已经启动。
Total System Global Area 2147483648 bytes
Fixed Size 2030296 bytes
Variable Size 469763368 bytes
Database Buffers 1660944384 bytes
Redo Buffers 14745600 bytes
数据库装载完毕。
数据库已经打开。
本来很简单的一个问题却大费周折。这个教训说明解决问题的时候须冷静地分析和判断,否则很容易被一些其他的信息干扰而误入歧途,从而导致在解决问题时走上弯路。
尤其是,如果在误入歧途的过程中,执行了破坏性或不可逆转的操作,则可能产生运维事故。由此可见,DBA在诊断、分析和处理问题时,保持头脑的清醒和冷静是多么的重要。
与DBA朋友们共勉。