第2节结构化搜索_在案例中实战使用term filter来搜索数据
课程大纲
1、根据用户ID、是否隐藏、帖子ID、发帖日期来搜索帖子
(1)插入一些测试帖子数据
POST /forum/article/_bulk
{ "index": { "_id": 1 }}
{ "articleID" : "XHDK-A-1293-#fJ3", "userID" : 1, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 2 }}
{ "articleID" : "KDKE-B-9947-#kL5", "userID" : 1, "hidden": false, "postDate": "2017-01-02" }
{ "index": { "_id": 3 }}
{ "articleID" : "JODL-X-1937-#pV7", "userID" : 2, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 4 }}
{ "articleID" : "QQPX-R-3956-#aD8", "userID" : 2, "hidden": true, "postDate": "2017-01-02" }
初步来说,就先搞4个字段,因为整个es是支持json document格式的,所以说扩展性和灵活性非常之好。如果后续随着业务需求的增加,要在document中增加更多的field,那么我们可以很方便的随时添加field。但是如果是在关系型数据库中,比如mysql,我们建立了一个表,现在要给表中新增一些column,那就很坑爹了,必须用复杂的修改表结构的语法去执行。而且可能对系统代码还有一定的影响。
GET /forum/_mapping/article
{
"forum": {
"mappings": {
"article": {
"properties": {
"articleID": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"hidden": {
"type": "boolean"
},
"postDate": {
"type": "date"
},
"userID": {
"type": "long"
}
}
}
}
}
}
现在es 5.2版本,type=text,默认会设置两个field,一个是field本身,比如articleID,就是分词的;还有一个的话,就是field.keyword,articleID.keyword,默认不分词,会最多保留256个字符
(2)根据用户ID搜索帖子
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"userID" : 1
}
}
}
}
}
term filter/query:对搜索文本不分词,直接拿去倒排索引中匹配,你输入的是什么,就去匹配什么
比如说,如果对搜索文本进行分词的话,“helle world” --> “hello”和“world”,两个词分别去倒排索引中匹配
term,“hello world” --> “hello world”,直接去倒排索引中匹配“hello world”
(3)搜索没有隐藏的帖子
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"hidden" : false
}
}
}
}
}
(4)根据发帖日期搜索帖子
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"postDate" : "2017-01-01"
}
}
}
}
}
(5)根据帖子ID搜索帖子
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"articleID" : "XHDK-A-1293-#fJ3"
}
}
}
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 0,
"max_score": null,
"hits": []
}
}
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"articleID.keyword" : "XHDK-A-1293-#fJ3"
}
}
}
}
}
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 1,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 1,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01"
}
}
]
}
}
articleID.keyword,是es最新版本内置建立的field,就是不分词的。所以一个articleID过来的时候,会建立两次索引,一次是自己本身,是要分词的,分词后放入倒排索引;另外一次是基于articleID.keyword,不分词,保留256个字符最多,直接一个字符串放入倒排索引中。
所以term filter,对text过滤,可以考虑使用内置的field.keyword来进行匹配。但是有个问题,默认就保留256个字符。所以尽可能还是自己去手动建立索引,指定not_analyzed吧。在最新版本的es中,不需要指定not_analyzed也可以,将type=keyword即可。
(6)查看分词
GET /forum/_analyze
{
"field": "articleID",
"text": "XHDK-A-1293-#fJ3"
}
默认是analyzed的text类型的field,建立倒排索引的时候,就会对所有的articleID分词,分词以后,原本的articleID就没有了,只有分词后的各个word存在于倒排索引中。
term,是不对搜索文本分词的,XHDK-A-1293-#fJ3 --> XHDK-A-1293-#fJ3;但是articleID建立索引的时候,XHDK-A-1293-#fJ3 --> xhdk,a,1293,fj3
(7)重建索引
直接设置为keyword类型

能够搜索到
DELETE /forum
PUT /forum
{
"mappings": {
"article": {
"properties": {
"articleID": {
"type": "keyword"
}
}
}
}
}
POST /forum/article/_bulk
{ "index": { "_id": 1 }}
{ "articleID" : "XHDK-A-1293-#fJ3", "userID" : 1, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 2 }}
{ "articleID" : "KDKE-B-9947-#kL5", "userID" : 1, "hidden": false, "postDate": "2017-01-02" }
{ "index": { "_id": 3 }}
{ "articleID" : "JODL-X-1937-#pV7", "userID" : 2, "hidden": false, "postDate": "2017-01-01" }
{ "index": { "_id": 4 }}
{ "articleID" : "QQPX-R-3956-#aD8", "userID" : 2, "hidden": true, "postDate": "2017-01-02" }
(8)重新根据帖子ID和发帖日期进行搜索
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"articleID" : "XHDK-A-1293-#fJ3"
}
}
}
}
}
2、梳理学到的知识点
(1)term filter:根据exact value进行搜索,数字、boolean、date天然支持
(2)text需要建索引时指定为not_analyzed,才能用term query
(3)相当于SQL中的单个where条件
select *
from forum.article
where articleID='XHDK-A-1293-#fJ3'
第3节结构化搜索_filter执行原理深度剖析(bitset机制与caching机制)
课程大纲
(1)在倒排索引中查找搜索串,获取document list
date来举例

filter:2017-02-02
到倒排索引中一找,发现2017-02-02对应的document list是doc2,doc3
(2)为每个在倒排索引中搜索到的结果,构建一个bitset,[0, 0, 0, 1, 0, 1]
非常重要
使用找到的doc list,构建一个bitset,就是一个二进制的数组,数组每个元素都是0或1,用来标识一个doc对一个filter条件是否匹配,如果匹配就是1,不匹配就是0
[0, 1, 1]
doc1:不匹配这个filter的
doc2和do3:是匹配这个filter的
尽可能用简单的数据结构去实现复杂的功能,可以节省内存空间,提升性能
(3)遍历每个过滤条件对应的bitset,优先从最稀疏的开始搜索,查找满足所有条件的document
后面会讲解,一次性其实可以在一个search请求中,发出多个filter条件,每个filter条件都会对应一个bitset
遍历每个filter条件对应的bitset,先从最稀疏的开始遍历
[0, 0, 0, 1, 0, 0]:比较稀疏
[0, 1, 0, 1, 0, 1]
先遍历比较稀疏的bitset,就可以先过滤掉尽可能多的数据
遍历所有的bitset,找到匹配所有filter条件的doc
请求:filter,postDate=2017-01-01,userI D=1
postDate: [0, 0, 1, 1, 0, 0]
userID: [0, 1, 0, 1, 0, 1]
遍历完两个bitset之后,找到的匹配所有条件的doc,就是doc4
就可以将document作为结果返回给client了
(4)caching bitset,跟踪query,在最近256个query中超过一定次数的过滤条件,缓存其bitset。对于小segment(<1000,或<3%),不缓存bitset。
比如postDate=2017-01-01,[0, 0, 1, 1, 0, 0],可以缓存在内存中,这样下次如果再有这个条件过来的时候,就不用重新扫描倒排索引,反复生成bitset,可以大幅度提升性能。
在最近的256个filter中,有某个filter超过了一定的次数,次数不固定,就会自动缓存这个filter对应的bitset
segment(上半季),filter针对小segment获取到的结果,可以不缓存,segment记录数<1000,或者segment大小<index总大小的3%
segment数据量很小,此时哪怕是扫描也很快;segment会在后台自动合并,小segment很快就会跟其他小segment合并成大segment,此时就缓存也没有什么意义,segment很快就消失了
针对一个小segment的bitset,[0, 0, 1, 0]
filter比query的好处就在于会caching,但是之前不知道caching的是什么东西,实际上并不是一个filter返回的完整的doc list数据结果。而是filter bitset缓存起来。下次不用扫描倒排索引了。
(5)filter大部分情况下来说,在query之前执行,先尽量过滤掉尽可能多的数据
query:是会计算doc对搜索条件的relevance score,还会根据这个score去排序
filter:只是简单过滤出想要的数据,不计算relevance score,也不排序
(6)如果document有新增或修改,那么cached bitset会被自动更新
postDate=2017-01-01,[0, 0, 1, 0]
document,id=5,postDate=2017-01-01,会自动更新到postDate=2017-01-01这个filter的bitset中,全自动,缓存会自动更新。postDate=2017-01-01的bitset,[0, 0, 1, 0, 1]
document,id=1,postDate=2016-12-30,修改为postDate-2017-01-01,此时也会自动更新bitset,[1, 0, 1, 0, 1]
(7)以后只要是有相同的filter条件的,会直接来使用这个过滤条件对应的cached bitset
第4节结构化搜索_在案例中实战基于bool组合多个filter条件来搜索数据
课程大纲
1、搜索发帖日期为2017-01-01,或者帖子ID为XHDK-A-1293-#fJ3的帖子,同时要求帖子的发帖日期绝对不为2017-01-02
select *
from forum.article
where (post_date='2017-01-01' or article_id='XHDK-A-1293-#fJ3')
and post_date!='2017-01-02'
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"should": [
{"term": { "postDate": "2017-01-01" }},
{"term": {"articleID": "XHDK-A-1293-#fJ3"}}
],
"must_not": {
"term": {
"postDate": "2017-01-02"
}
}
}
}
}
}
}
must,should,must_not,filter:必须匹配,可以匹配其中任意一个即可,必须不匹配
2、搜索帖子ID为XHDK-A-1293-#fJ3,或者是帖子ID为JODL-X-1937-#pV7而且发帖日期为2017-01-01的帖子
select *
from forum.article
where article_id='XHDK-A-1293-#fJ3'
or (article_id='JODL-X-1937-#pV7' and post_date='2017-01-01')
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"should": [
{
"term": {
"articleID": "XHDK-A-1293-#fJ3"
}
},
{
"bool": {
"must": [
{
"term":{
"articleID": "JODL-X-1937-#pV7"
}
},
{
"term": {
"postDate": "2017-01-01"
}
}
]
}
}
]
}
}
}
}
}
3、梳理学到的知识点
(1)bool:must,must_not,should,组合多个过滤条件
(2)bool可以嵌套
(3)相当于SQL中的多个and条件:当你把搜索语法学好了以后,基本可以实现部分常用的sql语法对应的功能
第5节结构化搜索_在案例中实战使用terms搜索多个值以及多值搜索结果优化
课程大纲
term: {"field": "value"}
terms: {"field": ["value1", "value2"]}
sql中的in
select * from tbl where col in ("value1", "value2")
1、为帖子数据增加tag字段
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"tag" : ["java", "hadoop"]} }
{ "update": { "_id": "2"} }
{ "doc" : {"tag" : ["java"]} }
{ "update": { "_id": "3"} }
{ "doc" : {"tag" : ["hadoop"]} }
{ "update": { "_id": "4"} }
{ "doc" : {"tag" : ["java", "elasticsearch"]} }
2、搜索articleID为KDKE-B-9947-#kL5或QQPX-R-3956-#aD8的帖子,搜索tag中包含java的帖子
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"terms": {
"articleID": [
"KDKE-B-9947-#kL5",
"QQPX-R-3956-#aD8"
]
}
}
}
}
}
GET /forum/article/_search
{
"query" : {
"constant_score" : {
"filter" : {
"terms" : {
"tag" : ["java"]
}
}
}
}
}
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 1,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
]
}
},
{
"_index": "forum",
"_type": "article",
"_id": "4",
"_score": 1,
"_source": {
"articleID": "QQPX-R-3956-#aD8",
"userID": 2,
"hidden": true,
"postDate": "2017-01-02",
"tag": [
"java",
"elasticsearch"
]
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 1,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
]
}
}
]
}
}
3、优化搜索结果,仅仅搜索tag只包含java的帖子
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"tag_cnt" : 2} }
{ "update": { "_id": "2"} }
{ "doc" : {"tag_cnt" : 1} }
{ "update": { "_id": "3"} }
{ "doc" : {"tag_cnt" : 1} }
{ "update": { "_id": "4"} }
{ "doc" : {"tag_cnt" : 2} }
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"bool": {
"must": [
{
"term": {
"tag_cnt": 1
}
},
{
"terms": {
"tag": ["java"]
}
}
]
}
}
}
}
}
["java", "hadoop", "elasticsearch"]
4、学到的知识点梳理
(1)terms多值搜索
(2)优化terms多值搜索的结果
(3)相当于SQL中的in语句
第6节结构化搜索_在案例中实战基于range filter来进行范围过滤
课程大纲
1、为帖子数据增加浏览量的字段
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"view_cnt" : 30} }
{ "update": { "_id": "2"} }
{ "doc" : {"view_cnt" : 50} }
{ "update": { "_id": "3"} }
{ "doc" : {"view_cnt" : 100} }
{ "update": { "_id": "4"} }
{ "doc" : {"view_cnt" : 80} }
2、搜索浏览量在30~60之间的帖子
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"view_cnt": {
"gt": 30,
"lt": 60
}
}
}
}
}
}
gte
lte
3、搜索发帖日期在最近1个月的帖子
POST /forum/article/_bulk
{ "index": { "_id": 5 }}
{ "articleID" : "DHJK-B-1395-#Ky5", "userID" : 3, "hidden": false, "postDate": "2017-03-01", "tag": ["elasticsearch"], "tag_cnt": 1, "view_cnt": 10 }
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"postDate": {
"gt": "2017-03-10||-30d"
}
}
}
}
}
}
GET /forum/article/_search
{
"query": {
"constant_score": {
"filter": {
"range": {
"postDate": {
"gt": "now-30d"
}
}
}
}
}
}
4、梳理一下学到的知识点
(1)range,sql中的between,或者是>=1,<=1
(2)range做范围过滤
第7节深度探秘搜索技术_在案例中体验如何手动控制全文检索结果的精准度
课程大纲
1、为帖子数据增加标题字段
POST /forum/article/_bulk
{ "update": { "_id": "1"} }
{ "doc" : {"title" : "this is java and elasticsearch blog"} }
{ "update": { "_id": "2"} }
{ "doc" : {"title" : "this is java blog"} }
{ "update": { "_id": "3"} }
{ "doc" : {"title" : "this is elasticsearch blog"} }
{ "update": { "_id": "4"} }
{ "doc" : {"title" : "this is java, elasticsearch, hadoop blog"} }
{ "update": { "_id": "5"} }
{ "doc" : {"title" : "this is spark blog"} }
2、搜索标题中包含java或elasticsearch的blog
或
这个,就跟之前的那个term query,不一样了。不是搜索exact value,是进行full text全文检索。
match query,是负责进行全文检索的。当然,如果要检索的field,是not_analyzed类型的,那么match query也相当于term query。
GET /forum/article/_search
{
"query": {
"match": {
"title": "java elasticsearch"
}
}
}
3、搜索标题中包含java和elasticsearch的blog
和
搜索结果精准控制的第一步:灵活使用and关键字,如果你是希望所有的搜索关键字都要匹配的,那么就用and,可以实现单纯match query无法实现的效果
GET /forum/article/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}
}
4、搜索包含java,elasticsearch,spark,hadoop,4个关键字中,至少3个的blog
控制搜索结果的精准度的第二步:指定一些关键字中,必须至少匹配其中的多少个关键字,才能作为结果返回
GET /forum/article/_search
{
"query": {
"match": {
"title": {
"query": "java elasticsearch spark hadoop",
"minimum_should_match": "75%"
}
}
}
}
5、用bool组合多个搜索条件,来搜索title
GET /forum/article/_search
{
"query": {
"bool": {
"must": { "match": { "title": "java" }},
"must_not": { "match": { "title": "spark" }},
"should": [
{ "match": { "title": "hadoop" }},
{ "match": { "title": "elasticsearch" }}
]
}
}
}
6、bool组合多个搜索条件,如何计算relevance score
must和should搜索对应的分数,加起来,除以must和should的总数
排名第一:java,同时包含should中所有的关键字,hadoop,elasticsearch
排名第二:java,同时包含should中的elasticsearch
排名第三:java,不包含should中的任何关键字
should是可以影响相关度分数的
must是确保说,谁必须有这个关键字,同时会根据这个must的条件去计算出document对这个搜索条件的relevance score
在满足must的基础之上,should中的条件,不匹配也可以,但是如果匹配的更多,那么document的relevance score就会更高
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1.3375794,
"hits": [
{
"_index": "forum",
"_type": "article",
"_id": "4",
"_score": 1.3375794,
"_source": {
"articleID": "QQPX-R-3956-#aD8",
"userID": 2,
"hidden": true,
"postDate": "2017-01-02",
"tag": [
"java",
"elasticsearch"
],
"tag_cnt": 2,
"view_cnt": 80,
"title": "this is java, elasticsearch, hadoop blog"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "1",
"_score": 0.53484553,
"_source": {
"articleID": "XHDK-A-1293-#fJ3",
"userID": 1,
"hidden": false,
"postDate": "2017-01-01",
"tag": [
"java",
"hadoop"
],
"tag_cnt": 2,
"view_cnt": 30,
"title": "this is java and elasticsearch blog"
}
},
{
"_index": "forum",
"_type": "article",
"_id": "2",
"_score": 0.19856805,
"_source": {
"articleID": "KDKE-B-9947-#kL5",
"userID": 1,
"hidden": false,
"postDate": "2017-01-02",
"tag": [
"java"
],
"tag_cnt": 1,
"view_cnt": 50,
"title": "this is java blog"
}
}
]
}
}
7、搜索java,hadoop,spark,elasticsearch,至少包含其中3个关键字
默认情况下,should是可以不匹配任何一个的,比如上面的搜索中,this is java blog,就不匹配任何一个should条件
但是有个例外的情况,如果没有must的话,那么should中必须至少匹配一个才可以
比如下面的搜索,should中有4个条件,默认情况下,只要满足其中一个条件,就可以匹配作为结果返回
但是可以精准控制,should的4个条件中,至少匹配几个才能作为结果返回
GET /forum/article/_search
{
"query": {
"bool": {
"should": [
{ "match": { "title": "java" }},
{ "match": { "title": "elasticsearch" }},
{ "match": { "title": "hadoop" }},
{ "match": { "title": "spark" }}
],
"minimum_should_match": 3
}
}
}
梳理一下学到的知识点
1、全文检索的时候,进行多个值的检索,有两种做法,match query;should
2、控制搜索结果精准度:and operator,minimum_should_match
第8节深度探秘搜索技术_基于term+bool实现的multiword搜索底层原理剖析
课程大纲
1、普通match如何转换为term+should
{
"match": { "title": "java elasticsearch"}
}
使用诸如上面的match query进行多值搜索的时候,es会在底层自动将这个match query转换为bool的语法
bool should,指定多个搜索词,同时使用term query
{
"bool": {
"should": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}
2、and match如何转换为term+must
{
"match": {
"title": {
"query": "java elasticsearch",
"operator": "and"
}
}
}
{
"bool": {
"must": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }}
]
}
}
3、minimum_should_match如何转换
{
"match": {
"title": {
"query": "java elasticsearch hadoop spark",
"minimum_should_match": "75%"
}
}
}
{
"bool": {
"should": [
{ "term": { "title": "java" }},
{ "term": { "title": "elasticsearch" }},
{ "term": { "title": "hadoop" }},
{ "term": { "title": "spark" }}
],
"minimum_should_match": 3
}
}
上一讲,为啥要讲解两种实现multi-value搜索的方式呢?实际上,就是给这一讲进行铺垫的。match query --> bool + term。
第9节深度探秘搜索技术_基于boost的细粒度搜索条件权重控制
课程大纲
需求:搜索标题中包含java的帖子,同时呢,如果标题中包含hadoop或elasticsearch就优先搜索出来,同时呢,如果一个帖子包含java hadoop,一个帖子包含java elasticsearch,包含hadoop的帖子要比elasticsearch优先搜索出来
知识点,搜索条件的权重,boost,可以将某个搜索条件的权重加大,此时当匹配这个搜索条件和匹配另一个搜索条件的document,计算relevance score时,匹配权重更大的搜索条件的document,relevance score会更高,当然也就会优先被返回回来
默认情况下,搜索条件的权重都是一样的,都是1
GET /forum/article/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "blog"
}
}
],
"should": [
{
"match": {
"title": {
"query": "java"
}
}
},
{
"match": {
"title": {
"query": "hadoop"
}
}
},
{
"match": {
"title": {
"query": "elasticsearch"
}
}
},
{
"match": {
"title": {
"query": "spark",
"boost": 5
}
}
}
]
}
}
}
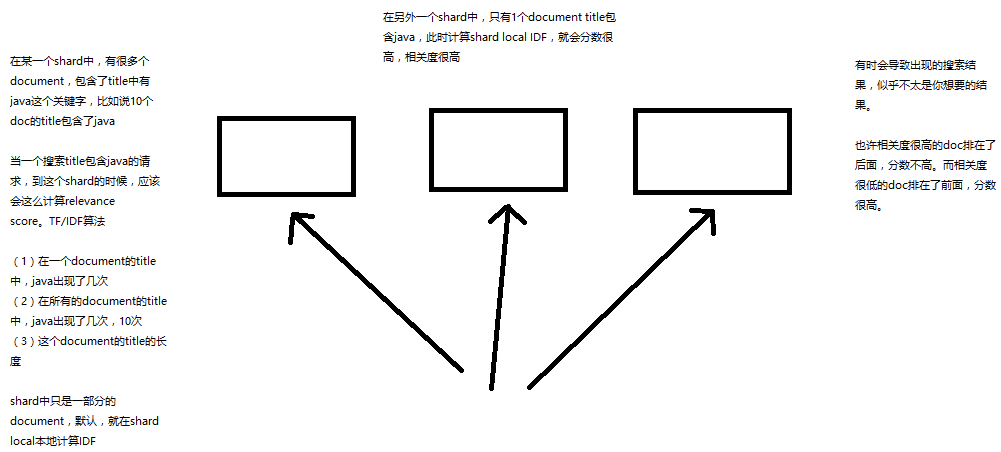
第10节深度探秘搜索技术_多shard场景下relevance score不准确问题大揭秘
课程大纲
1、多shard场景下relevance score不准确问题大揭秘
如果你的一个index有多个shard的话,可能搜索结果会不准确
图解
2、如何解决该问题?
(1)生产环境下,数据量大,尽可能实现均匀分配
数据量很大的话,其实一般情况下,在概率学的背景下,es都是在多个shard中均匀路由数据的,路由的时候根据_id,负载均衡
比如说有10个document,title都包含java,一共有5个shard,那么在概率学的背景下,如果负载均衡的话,其实每个shard都应该有2个doc,title包含java
如果说数据分布均匀的话,其实就没有刚才说的那个问题了
(2)测试环境下,将索引的primary shard设置为1个,number_of_shards=1,index settings
如果说只有一个shard,那么当然,所有的document都在这个shard里面,就没有这个问题了
(3)测试环境下,搜索附带search_type=dfs_query_then_fetch参数,会将local IDF取出来计算global IDF
计算一个doc的相关度分数的时候,就会将所有shard对的local IDF计算一下,获取出来,在本地进行global IDF分数的计算,会将所有shard的doc作为上下文来进行计算,也能确保准确性。但是production生产环境下,不推荐这个参数,因为性能很差。