首先感谢(http://blog.csdn.net/magic_leg/article/details/73957331)这篇博客首次将《A Survey on Transfer Learning》这篇文章翻译成中文版,给予我们很大的参考。
但上述作者翻译的内容有很多不准确的词语、省略了很多内容、工作略显粗糙,因此本文将给出一篇完整近乎准确的中文版《A Survey on Transfer Learning》的翻译。
《A Survey on Transfer Learning》这篇综述性文章是一篇迁移学习入门者的必读文章,非常具有权威性和引用价值。下面是中文翻译。
迁移学习研究综述
Translator:Xu Yin
在许多机器学习和数据挖掘算法中,一个重要的假设就是目前的训练数据和将来的训练数据,一定要在相同的特征空间并且具有相同的分布。然而,在许多现实的应用案例中,这个假设可能不会成立。比如,我们有时候在某个感兴趣的领域有个分类任务,但是我们只有另一个感兴趣领域的足够训练数据,并且后者的数据可能处于与之前领域不同的特征空间或者遵循不同的数据分布。这类情况下,如果知识的迁移做的成功,我们将会通过避免花费大量昂贵的标记样本数据的代价,使得学习性能取得显著的提升。近年来,为了解决这类问题,迁移学习作为一个新的学习框架出现在人们面前。这篇综述主要聚焦于当前迁移学习对于分类、回归和聚类问题的梳理和回顾。在这篇综述中,我们主要讨论了其他的机器学习算法,比如领域适应、多任务学习、样本选择偏差以及协方差转变等和迁移学习之间的关系。我们也探索了一些迁移学习在未来的潜在方法的研究。
关键词:
迁移学习;综述;机器学习;数据挖掘
1 引言
数据挖掘和机器学习已经在许多知识工程领域实现了巨大成功,比如分类、回归和聚类。然而,许多机器学习方法仅在一个共同的假设的前提下:训练数据和测试数据必须从同一特种空间中获得,并且需要具有相同的分布。当分布情况改变时,大多数的统计模型需要使用新收集的训练样本进行重建。在许多现实的应用中,重新收集所需要的训练数据来对模型进行重建,是需要花费很大代价或者是不可能的。如果降低重新收集训练数据的需求和代价,那将是非常不错的。在这些情况下,在任务领域之间进行知识的迁移或者迁移学习,将会变得十分有必要。
许多知识工程领域的例子,都能够从迁移学习中真正获益。举一个网页文件分类的例子。我们的目的是把给定的网页文件分类到几个之前定义的目录里。作为一个例子,在网页文件分类中,可能是根据之前手工标注的样本,与之关联的分类信息,而进行分类的大学网页。对于一个新建网页的分类任务,其中,数据特征或数据分布可能不同,因此就出现了已标注训练样本的缺失问题。因此,我们将不能直接把之前在大学网页上的分类器用到新的网页中进行分类。在这类情况下,如果我们能够把分类知识迁移到新的领域中是非常有帮助的。
当数据很容易就过时的时候,对于迁移学习的需求将会大大提高。在这种情况下,一个时期所获得的被标记的数据将不会服从另一个时期的分布。例如室内wifi定位问题,它旨在基于之前wifi用户的数据来查明用户当前的位置。在大规模的环境中,为了建立位置模型来校正wifi数据,代价是非常昂贵的。因为用户需要在每一个位置收集和标记大量的wifi信号数据。然而,wifi的信号强度可能是一个时间、设备或者其他类型的动态因素函数。在一个时间或一台设备上训练的模型可能导致另一个时间或设备上位置估计的性能降低。为了减少再校正的代价,我们可能会把在一个时间段(源域)内建立的位置模型适配到另一个时间段(目标域),或者把在一台设备(源域)上训练的位置模型适配到另一台设备(目标域)上。
对于第三个例子,关于情感分类的问题。我们的任务是自动将产品(例如相机品牌)上的评论分类为正面和负面意见。对于这些分类任务,我们需要首先收集大量的关于本产品和相关产品的评论。然后我们需要在与它们相关标记的评论上,训练分类器。因此,关于不同产品牌的评论分布将会变得十分不一样。为了达到良好的分类效果,我们需要收集大量的带标记的数据来对某一产品进行情感分类。然而,标记数据的过程可能会付出昂贵的代价。为了降低对不同的产品进行情感标记的注释,我们将会训练在某一个产品上的情感分类模型,并把它适配到其它产品上去。在这种情况下,迁移学习将会节省大量的标记成本。
在这篇文章中,我们给出了在机器学习和数据挖掘领域,迁移学习在分类、回归和聚类方面的发展。同时,也有在机器学习方面的文献中,大量的迁移学习对增强学习的工作。然而,在这篇文章中,我们更多的关注于在数据挖掘及其相近的领域,关于迁移学习对分类、回归和聚类方面的问题。通过这篇综述,我们希望对于数据挖掘和机器学习的团体能够提供一些有用的帮助。
接下来本文的组织结构如下:在接下来的四个环节,我们先给出了一个总体的全览,并且定义了一些接下来用到的标记。然后,我们简短概括一下迁移学习的发展历程,同时给出迁移学习的统一定义,并将迁移学习分为三种不同的设置(在图2和表2中给出)。我们对于每一种设置回顾了不同的方法,在表3中给出。之后,在第6节,我们回顾了一些当前关于“负迁移”这一话题的研究,即那些发生在对知识迁移的过程中,产生负面影响的时候。在第7节,我们介绍了迁移学习的一些成功的应用,并且列举了一些已经发布的关于迁移学习数据集和工具包。最后在结论中,我们展望了迁移学习的发展前景。
2 概述
2.1 简短的有关迁移学习的历史
传统的数据挖掘和机器学习算法通过使用之前收集到的带标记的数据或者不带标记的数据进行训练,进而对将来的数据进行预测。在版监督分类中这样标注这类问题,即带标记的样本太少,以至于只使用大量未标记的样本数据和少量已标记的样本数据不能建立良好的分类器。监督学习和半监督学习分别对于缺失数据集的不同已经有人进行研究过。例如周和吴研究过如何处理噪音类标记的问题。杨认为当增加测试时,可以使得代价敏感的学习作为未来的样本。尽管如此,他们中的大多数假定的前提是带标记或者是未标记的样本都是服从相同分布的。相反,迁移学习允许训练和测试的域、任务以及分布是不同的。在现实中我们可以发现很多迁移学习的例子。例如我们可能发现,学习如何辨认苹果将会有助于辨认梨子。类似的,学会弹电子琴将会有助于学习钢琴。对于迁移学习研究的驱动,是基于事实上,人类可以智能地把先前学习到的知识应用到新的问题上进而快速或者更好的解决新问题。最初的关于迁移学习的研究是在NIPS-95研讨会上,机器学习领域的一个研讨话题“学会学习”,就是关注于保留和重用之前学到的知识这种永久的机器学习方法。
自从1995年开始,迁移学习就以不同的名字受到了越来越多人的关注:学会学习、终生学习、知识迁移、感应迁移、多任务学习、知识整合、前后敏感学习、基于感应阈值的学习、元学习、增量或者累积学习。所有的这些,都十分接近让迁移学习成为一个多任务学习的一个框架这样的学习技术,即使他们是不同的,也要尽量学习多项任务。多任务学习的一个典型的方法是揭示是每个任务都受益的共同(潜在)特征。
在2005年,美国国防部高级研究计划局的信息处理技术办公室发表的代理公告,给出了迁移学习的新任务:把之前任务中学习到的知识和技能应用到新的任务中的能力。在这个定义中,迁移学习旨在从一个或者多个源任务中提取信息,进而应用到目标任务上。与多任务学习相反,迁移学习不是同时学习源目标和任务目标的内容,而是更多的关注与任务目标。在迁移学习中,源任务和目标任务不再是对称的。

图1展示了传统的学习和迁移学习的学习过程之间的不同。我们可以看到,传统的机器学习技术致力于从每个任务中抓取信息,而迁移学习致力于当目标任务缺少高质量的训练数据时,从之前任务向目标任务迁移知识。
如今,迁移学习出现在许多顶级期刊上,令人注意的数据挖掘(比如ACM KDD,IEEE ICDM和PKDD),机器学习(比如ICML,ICDM和PKDD)和应用在数据挖掘和机器学习(比如ACM SIGIR,WWW和ACL)上。在我们给出迁移学习不同的类别的时候,我们首先描述一下本文中用到的符号。
2.2 符号和定义
在本节中,我们介绍了本文中使用的一些符号和定义。首先,我们分别给出“域”和“任务的定义”。
在本综述中,D域包含两部分:一个特征空间X和一个边缘概率分布P(X)。其中 X={x1,x2,...,xn}∈X。比如我们的学习任务是文本分类,每一个术语被用作一个二进制特征,然后X就是所有的术语向量的空间,xi是第i个与一些文本相关的术语向量。X是一个学习样本。总的来说,如果两个域不同,那么它们会有不同的特征空间或者服从不同的边缘概率分布。
给定一个具体的领域,D={X,P(X)},一任务个由两部分组成:一个标签空间Y和一个目标预测函数f(⋅)(由T={Y,f(⋅)}表示)。task不可被直观观测,但是可以通过训练数据学习得来。task由pair{xi,yi}组成,且xi∈X,yi∈Y。函数f(x)可用于预测对应标签。从概率学角度看,f(x)也可被写为P(y|x)。
简化起见,本文中我们只考虑一个源域DS一个目标域DT。更准确点,用 DS={(xS1,yS1),...,(xSn,ySn)},xSi∈Xs,ySi∈Ys 来表示源域。以文档分类为例,DS是文档对象向量及对应的true或false标签的集合。相似地有目标域记法DT,一般有0≤nT≪nS。
现在我们给出迁移学习的统一定义:
Definition 1 (Transfer learning): 给定源域DS和学习任务TS,一个目标域DT和学习任务TT,迁移学习致力于用DS和TS中的知识,帮助提高DT中目标预测函数fT(⋅)的学习。并且有DS≠DT或TS≠TT。
在上面定义中,D={X,P(X)},DS≠DT意味着源域和目标域实例不同(XS≠XT)或者源域和目标域边缘概率分布不同(PS(X)≠PT(X))。同理T={Y,P(Y|X)},TS≠TT意味着源域和目标域标签不同(YS≠YT)或者源域和目标域条件概率分布不同(P(YS|XS)≠P(YT|XT))。当源域和目标域相同且源任务和目标任务相同,则学习问题是一个传统机器学习问题。
以文档分类为例,域不同有以下两种情况:
1. 特征空间不同,即DS≠DT。可能是文档的语言不同。
2. 特征空间相同但边缘分布不同,即P(XS)≠P(XT)。可能是文档主题不同。
给定域DS和DT,学习任务不同可能有以下两种情况:
1. 域间标签空间不同,即YS≠YT。可能是源域中文档需要分两类,目标域需要分十类。
2. 域间条件概率分布不同,即P(YS|XS)≠P(YT|XT)。
除此之外,当两个域或者特征空间之间无论显式或隐式地存在某种关系时,我们说源域和目标域相关。
2.3 迁移学习分类
迁移学习主要有以下三个研究问题:1)迁移什么,2)如何迁移,3)何时迁移。
“迁移什么”提出了迁移哪部分知识的问题。
“何时迁移”提出了哪种情况下迁移手段应当被运用。当源域和目标域无关时,强行迁移可能并不会提高目标域上算法的性能,甚至会损害性能。这种情况称为negative transfer。当前大部分关于迁移学习的工作关注于“迁移什么”和“如何迁移”,隐含着一个假设:源域和目标域彼此相关。然而,如何避免negative transfer是一个很重要的问题。
基于迁移学习的定义,我们归纳了传统机器学习方法和迁移学习的异同见Table 1。

1. inductive transfer learning
目标任务和源任务不同,无论目标域与源域是否相同。
这种情况下,要用目标域中的一些已标注数据生成一个客观预测模型fT(⋅)以应用到目标域中。除此之外,根据源域中已标注和未标注数据的不同情况,可以进一步将inductive transfer learning分为两种情况:
- 源域中大量已标注数据可用。这种情况下inductive transfer learning和multitask learning类似。然而,inductive transfer learning只关注于通过从源任务中迁移知识以便在目标任务中获得更高性能,然而multitask learning尝试同时学习源任务和目标任务。
- 源域中无已标注数据可用。这种情况下inductive transfer learning和self-taught learning相似。self-taught learning中,源域和目标域间的特征空间(原文为label spaces)可能不同,这意味着源域中的边缘信息不能直接使用。因此当源域中无已标注数据可用时这两种学习方法相似。
2. transductive transfer learning
源任务和目标任务相同,源域和目标域不同。这种情况下,目标域中无已标注数据可用,源域中有大量已标注数据可用。除此之外,根据源域和目标域中的不同状况,可以进一步将transductive transfer learning分为两类:
- 源域和目标域中的特征空间不同,即XS≠XT;
- 源域和目标域间的特征空间相同,XS=XT,但输入数据的边缘概率分布不同,即P(XS)≠P(XT).
transductive transfer learning中的后一种情况与domain adaptation相关,因为文本分类、sample selection bias, covaritate shift的知识迁移都有相似的假设。
3. unsupervised transfer learning
与inductive transfer learning相似,目标任务与源任务不同但相关。然而,unsupervised transfer learning专注于解决目标域中的无监督学习问题,如聚类、降维、密度估计。这种情况下,训练中源域和目标域都无已标注数据可用。
迁移学习中不同分类的联系及相关领域被终结在T able2和Fig2中。
上述三种迁移学习可以基于“迁移什么”被分为四种情况,如Table3所示。Table3中已经描述的比较详细,在此不对这部分作翻译。

Table 4展示了不同迁移学习分类应用到的不同方法。

3 Inductive Transfer Learning
Definition 2 (Inductive Transfer learning): 给定源域、源任务、目标域、目标任务:DS,TS,DT,TT,Inductive Transfer Learning目标是在TS≠TT的情况下利用DS,TS的知识提升DT中的目标预测函数fT(⋅)。
基于上述对Inductive Transfer Learning的定义,用目标域中的一小部分已标注数据作为训练数据以诱导(induce)目标预测函数是必要的。
3.1 Transferring Knowledeg of Instances
Inductive Transfer Learning的instance-transfer approach直观上很吸引眼球:尽管源域数据不能直接重用,但还是有一部分特定数据可以和目标域中的一些已标注数据实现重用。
Dai et al. [6]提出了一个boosting algorithm, TrAdaBoost, 它是AdaBoost algorithm的一个扩展,以处理inductive transfer learning问题。TrAdaBoost假设源域和目标域数据使用相同的特征集和标签集,但两个域中的数据分布不同。除此之外,因为源域和目标域的分布不同,因此TrAdaBoost进一步假设源域中的部分数据对目标域的学习有用,另一部分数据没用甚至有害。它尝试对源域数据迭代式地重加权以减轻坏的源域数据对目标域的影响,增强好数据的增益。迭代的每一轮,TrAdaBoost在加权过的源数据和目标数据上训练基本分类器。只在目标数据上计算错误。TrAdaBoost在更新目标域上的错误分类样例上和AdaBoost使用相同策略,在更新源域上的错误分类源样例上和AdaBoost使用不同策略。TrAdaBoost的具体理论分析见[6]。
[30]提出了一种基于不同条件概率P(yT|xT),P(yS|xS)的从源域中移除误导性训练样例的启发式方法。
3.2 Transferring Knowledge of Feature Representations
Inductive Transfer Learning的feature-representation-transfer approach致力于找到好的特征表示去最小化域差异以及分类和回归模型误差。不同类型的源数据有找好特征表示的不同策略。如果源域中大量已标注数据可用,有监督方式可以被用于构建特征表示。这有点像multitask learning中的common feature learning。如果源域中没有已标注数据可用,无监督方式就要被使用。
3.2.1 有监督特征构建
Inductive Transfer Learning中的有监督特征构建与multitask learning中使用的方法类似。基本想法是去构建一个可以跨相关任务的低维表示,而且学习到的新表示也可以用于减小每个任务的分类或回归误差。Argyriou et al. [40]提出了一种针对multitask learning的稀疏特征学习方法。在Inductive Transfer Learning中,可以通过一个优化问题来学习公共特征,见下式: 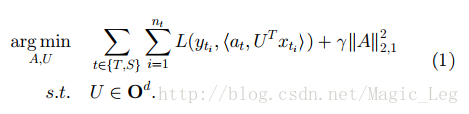
S和T表示源域和目标域中的任务,A=[aS,aT]∈Rd×2是参数矩阵。U是一个d×d的正交矩阵(mapping function)用于将高维数据映射成为低维表示。∥A∥r,p=(∑di=1∥ai∥pr)p。上式表达的优化问题同时估计了低维表示UTXT,UTXS和模型的参数A,上式也可被等效转化为凸优化函数并被高效地解决。
3.2.2 无监督特征构建
[22]提出以应用稀疏编码,他是一种无监督特征构建方法,以在迁移学习中学习高维特征。这种想法基本由两部构成:第一步,通过在源域数据上求解(2)式得到更高层的偏置向量b={b1,b2,...,bS}:
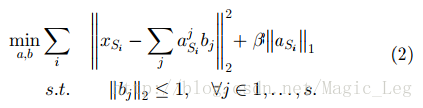
具体参数见原文
得到偏置向量b之后,第二步在目标域数据上应用(3)式以学习基于偏置向量b的更高维特征
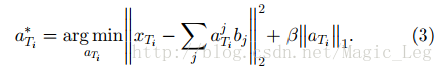
最后,目标域上,判别算法被应用到a∗Ti和对应的标签以训练分类和回归模型。这种方法的一个缺点是(2)式中在源域上学到的所谓更高维偏置向量b可能在目标域上并不适用。
最近,manifold learning methods被应用于迁移学习,可见[44]。
3.3 Transferring Knowledge of Parameters
大多数inductive transfer learning的parameter-transfer approaches都假设相关任务的不同模型之间共享一些参数或更高层的超参数分布。这部分描述的大多数方法包括一个规则化框架一个多层Bayes框架都被设计在multitask learning下工作。然而,它们可以很容易地为迁移学习修改。就像之前提到的,multitask learning试图同时完美地学习源任务和目标任务,而迁移学习只想利用源域数据提升目标域数据下的性能。因此,multitask learning中对源域和目标域数据的损失函数的权重都一样,而对迁移学习这两者的权重则不同。直观地,我们可以对目标域山上的损失函数赋予更高的权重以确保目标域上的效果更好。
[45]提出了一个高效的算法叫MT-IVM,基于 Gaussian Processes,以处理multitask learning任务。MT-IVM试图通过共享相同 GP prior 以在多任务情况下学习Gaussian Processes的参数。[46]也在GP情况下调研了multitask learning.
7 Applications of Transfer Learning
目前,至少有两个基于迁移学习的国际比赛。ECML/PKDD-2006竞赛内容是设计一个个性化垃圾邮件过滤系统。首先根据已标注(“垃圾”、“非垃圾”)的邮件训练一个分类器。对每个新邮件用户,适配这个模型给他。但靠模型的数据分布可能和新用户不同,因此这是一个生成式迁移学习问题,目标是将老的邮件过滤模型在更少训练数据和更短训练时间的情况下适配给新情境。
第二个数据集是ICDM-2007中发布的,任务是估计不同时间段内获得的WiFi信号估计用户室内位置。在不同时段,WiFi信号的强度分布可能是时间、位置、设备的不同函数。这个任务中迁移学习被用于减小数据重标注开销。