机器学习训练营——机器学习爱好者的自由交流空间(qq 群号:696721295)
sklearn.feature_selection模块里的类能被用来在样本集上作特征选择、或者叫维数降低,改善估计量的准确性、在高维空间的表现。下面我们介绍几种常用的特征选择方法。
删除低方差特征
VarianceThreshold是一个简单的特征选择基准方法。它删除所有方差小于某阈值的特征。默认删除所有0方差特征,即,特征在所有样本里有相同的值。举一个例子,假设我们有一个布尔特征数据集,我们想删除在超过80%的样本里值都是1或都是0的特征。布尔特征是Bernoulli型随机变量,它的方差是
因此我们选择阈值
.
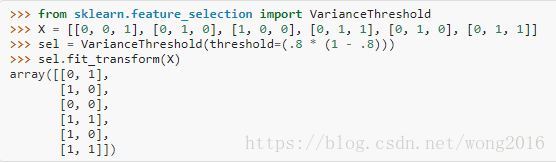
VarianceThreshold删除了第一列,这列包含0的概率
单变量特征选择
单变量特征选择,是根据单变量的统计学检验选择最好的特征。它可以视为估计前的预处理步, Scikit-learn执行transform方法作特征选择。
SelectKBest删除除k个最高分数的特征外的所有特征SelectPercentile删除除最高分位数特征外的所有特征使用普遍的单变量统计检验选择特征:假阳性率(false positive rate)
SelectFpr, 假发现率(false discovery rate)SelectFdr, family wise errorSelectFweGenericUnivariateSelect用一个可配置策略作单变量特征选择。它可以使用超参数搜索估计量选择最好的策略。
例如,我们能作一个样本的
检验,只选择两个最好的特征。

这些对象取一个分数函数作为输入,返回单变量分数和p值。
对于回归:
f_regression,mutual_info_regression对于分类:
chi2,f_classif,mutual_info_classif
基于F检验的方法可以估计两个随机变量的线性关系。另一方面,互信息的方法能够捕捉任何类型的统计关系。
递归特征排除
给定一个外部估计量,分派权给特征(比如说,一个线性模型的系数)。递归特征排除(recursive feature elimination, RFE), 是递归地选择越来越小的特征集。首先,在初始特征集上训练估计量,由coef_或feature_importances_属性获得每个特征的重要性。然后,最不重要的特征被从当前特征集中排除。重复特征排除过程,直到达到想要的特征数。
RFECV在一个交叉验证的循环里作RFE, 找到最优的特征数。
使用SelectFromModel的特征选择
SelectFromModel是一个元转换器,它可以结合任何在拟合后有coef_ and feature_importances_的估计量使用。由参数threshold指定阈值,如果coef_ and feature_importances_的值低于这个阈值,那么对应的特征被认为不重要而排除。除了指定阈值,还可以使用一个字符串参数启发式寻找阈值。可利用的启发式方法有 “mean”, “median”, 浮点值乘均值或中位数,例如,”0.1*mean”
基于L1的特征选择
L1范数惩罚的线性模型有稀疏解,即,它估计的系数里很多是0. 当我们的目标是降低数据的维数时,可以配合feature_selection.SelectFromModel选择这些模型里的非零系数。特别指出,有用的稀疏估计量有linear_model.Lasso回归、svm.LinearSVC分类。
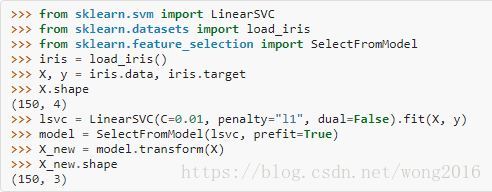
在SVM和logistic回归里,参数C控制稀疏性,即,C值越小,选择的特征就越少。在Lasso里,参数
越大,选择的特征越少。
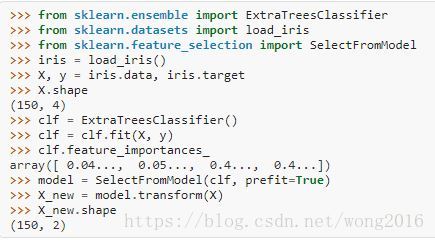
基于树的特征选择
基于树的估计量能被用来计算特征重要性,然后丢弃不相关的特征。
特征选择作为管道一部分
特征选择通常作为实际学习前的数据预处理步。在scikit-learn里,推荐的方法是使用sklearn.pipeline.Pipeline:
clf = Pipeline([
('feature_selection', SelectFromModel(LinearSVC(penalty="l1"))),
('classification', RandomForestClassifier())
])
clf.fit(X, y)在以上代码片里,我们使用了sklearn.svm.LinearSVC and sklearn.ensemble.RandomForestClassifier训练转换后的输出上,即,只使用相关的特征。你也可以用其它特征选择方法,或提供特征重要性的分类器作类似的操作。
阅读更多精彩内容,请关注微信公众号:统计学习与大数据