1:概念
Amazon Kinesis
Amazon Kinesis是一种全面管理的服务,用于大规模实时处理流数据。提供多种核心功能,可以经济高效地处理任意规模的流数据,同时具有很高的灵活性。借助 Amazon Kinesis,可以获取实时数据 (例如视频、音频、应用程序日志、网站点击流) 以及关于机器学习、分析和其他应用程序的 IoT 遥测数据。借助 Amazon Kinesis,可以即刻对收到的数据进行处理和分析并做出响应,无需等到收集完全部数据后才开始进行处理。
Shard (分区)
分区是 Amazon Kinesis 数据流的基本吞吐量单位。一个分片提供 1MB/秒数据输入和 2MB/秒输入输出容量。一个分片最高可支持每秒 1 000 个 PUT 记录。创建数据流时,必须指定所需的分区数量。
Record(记录)
记录是存储在 Amazon Kinesis 数据流中的数据单元。记录由序列号、分区键和数据 Blob 组成。数据 Blob 是数据创建器添加到数据流的重要数据。数据块的最大尺寸(Base64 编码前的数据有效载荷)是 1 兆字节 (MB)。
Partition Key(分区键)
分区键用于隔离Records并路由到不同的数据流Shards。分区键由数据创建器在添加数据到 Amazon Kinesis 数据流时指定。
Sequence Number(序列号)
序列号是每个Record的唯一标识符
2:Kinesis Data Stream的限制
1. kinesis默认情况下数据量的Record在添加后的最长24小时内进行访问。也可以启动延长数据保留期限来将该限制提升到7天。
2. Record内的数据块最大是1MB
3. 每个Shard 最高可支持每秒1000个Put输入记录。也就是说每个Shard的最大写带宽为1Gb/s
本次实验是以Spark官网给出的例子来实现。有兴趣可以看英文原文:https://spark.apache.org/docs/latest/streaming-kinesis-integration.html 这次实现会创建一个名叫word-counts-kinesis的Kinesis Data Stream Shard 数量为1。
3:创建Kinesis stream

4: 实现一个往kinesis写数据的Producer
代码实现如下:
import java.nio.ByteBuffer
import com.amazonaws.auth.DefaultAWSCredentialsProviderChain
import com.amazonaws.services.kinesis.AmazonKinesisClient
import com.amazonaws.services.kinesis.model.PutRecordRequest
import org.apache.log4j.{Level, Logger}
import scala.util.Random
object KinesisWordProducerASL {
def main(args: Array[String]): Unit = {
//调整日志级别
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//Kinesis Stream 名称
val stream = "word-counts-kinesis"
//Kinesis 访问路径
val endpoint = "https://kinesis.us-east-1.amazonaws.com"
//一秒钟发送1000个Records
val recordsPerSecond = "1000"
//一个Record包含100个单词
val wordsPerRecord = "10"
val totals = generate(stream, endpoint, recordsPerSecond.toInt, wordsPerRecord.toInt)
println("Totals for the words send")
totals.foreach(println(_))
}
private def generate(stream: String,
endpoint: String,
recordsPerSecond: Int,
wordsPerRecord: Int): Seq[(String, Int)] = {
//定义一个单词列表
val randomWords = List("spark", "hadoop", "hive", "kinesis", "kinesis")
val totals = scala.collection.mutable.Map[String, Int]()
//建立Kinesis连接 这里aws_access_key_id,aws_secret_access_key已经存在本地credentials
val kinesisClient = new AmazonKinesisClient(new DefaultAWSCredentialsProviderChain())
kinesisClient.setEndpoint(endpoint)
println(s"Putting records onto stream $stream and endpoint $endpoint at a rate of" +
s" $recordsPerSecond records per second and $wordsPerRecord words per record")
//根据recordsPerSecond 和 wordsPerRecord 将随机生成的单词放入Record
for (i <- 1 to 2) {
val records =(1 to recordsPerSecond.toInt).foreach {
recordNum =>
val data = (1 to wordsPerRecord.toInt).map(x => {
val randomWordIdx = Random.nextInt(randomWords.size)
val randomWord = randomWords(randomWordIdx)
totals(randomWord) = totals.getOrElse(randomWord, 0) + 1
randomWord
}).mkString(" ")
//创建一个分区键
val partitionKey = s"partitionKey-$recordNum"
//创建一个putRecordRequest
val putRecordRequest = new PutRecordRequest().withStreamName(stream)
.withPartitionKey(partitionKey)
.withData(ByteBuffer.wrap(data.getBytes))
//将record放到stream中
val putRecordResult = kinesisClient.putRecord(putRecordRequest)
}
Thread.sleep(1000)
println("Sent " + recordsPerSecond + " records")
}
totals.toSeq.sortBy(_._1)
}
}
运行结果
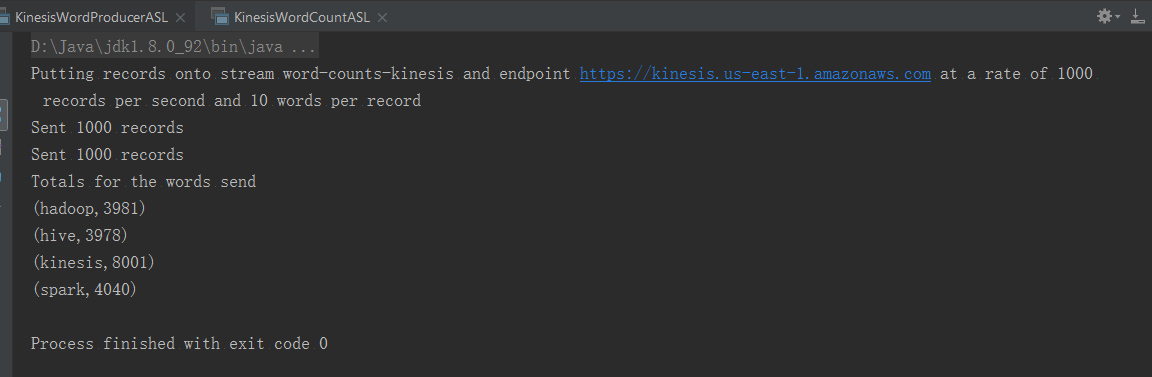
5:实现Spark Streaming往Kinesis读数据
Spark读数据的频率为2秒钟从Kinesis Data Stream读一次
import com.amazonaws.auth.DefaultAWSCredentialsProviderChain
import com.amazonaws.regions.RegionUtils
import com.amazonaws.services.kinesis.{AmazonKinesis, AmazonKinesisClient}
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.kinesis.KinesisInitialPositions.Latest
import org.apache.spark.streaming.kinesis.KinesisInputDStream
import org.apache.spark.streaming.{Milliseconds, StreamingContext}
object KinesisWordCountASL {
def main(args: Array[String]): Unit = {
//调整日志级别
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
val appName = "WordCountsApp"
//Kinesis Stream 名称
val streamName = "word-counts-kinesis"
val endpointUrl = "https://kinesis.us-east-1.amazonaws.com"
val credentials = new DefaultAWSCredentialsProviderChain().getCredentials()
require(credentials !=null, "No AWS credentials found. Please specify credentials using one of the methods specified " +
"in http://docs.aws.amazon.com/AWSSdkDocsJava/latest/DeveloperGuide/credentials.html")
val kinesisClient = new AmazonKinesisClient(credentials)
kinesisClient.setEndpoint(endpointUrl)
val numShards = kinesisClient.describeStream(streamName).getStreamDescription.getShards().size()
val numStreams = numShards
// Spark Streaming batch interval
val batchInterval = Milliseconds(2000)
val kinesisCheckpointInterval = batchInterval
val regionName = getRegionNameByEndpoint(endpointUrl)
val sparkConf = new SparkConf().setAppName("KinesisWordCountASL").setMaster("local[*]")
val ssc = new StreamingContext(sparkConf, batchInterval)
val kinesisStreams = (0 until numStreams).map { i =>
KinesisInputDStream.builder
.streamingContext(ssc)
.streamName(streamName)
.endpointUrl(endpointUrl)
.regionName(regionName)
.initialPosition(new Latest())
.checkpointAppName(appName)
.checkpointInterval(kinesisCheckpointInterval)
.storageLevel(StorageLevel.MEMORY_AND_DISK_2)
.build()
}
//Union all the streams
val unionStreams = ssc.union(kinesisStreams)
val words = unionStreams.flatMap(byteArray => new String(byteArray).split(" "))
val wordCounts =words.map(word => (word, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
def getRegionNameByEndpoint(endpoint: String): String = {
import scala.collection.JavaConverters._
val uri = new java.net.URI(endpoint)
RegionUtils.getRegionsForService(AmazonKinesis.ENDPOINT_PREFIX)
.asScala
.find(_.getAvailableEndpoints.asScala.toSeq.contains(uri.getHost))
.map(_.getName)
.getOrElse(
throw new IllegalArgumentException(s"Could not resolve region for endpoint: $endpoint"))
}
}
运行结果
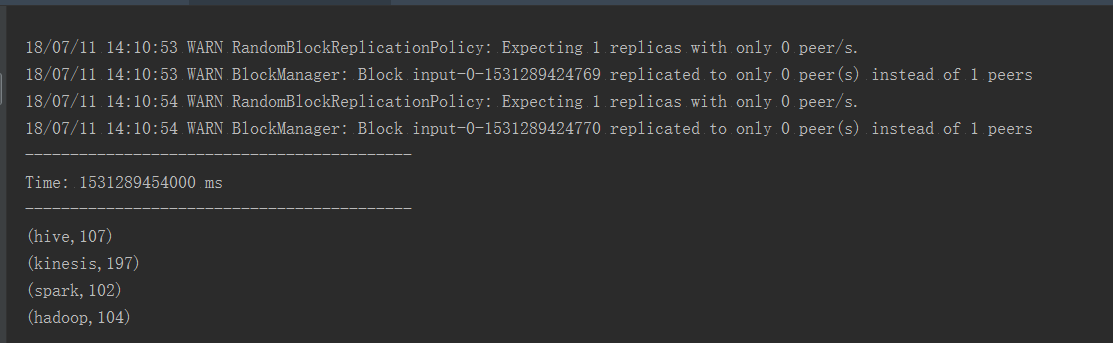
6:架构思路

7:总结
Spark Streaming + Kinesis 易用性高,上手容易。可以很快速的搭建一个大数据爬虫网站。前端开启成千上万个爬虫往Kinesis里面写数据。后端用Spark Streaming 分发,过滤,分析数据。
源码路径: https://github.com/mayflower-zc/spark-kinesis-sample-project