当面临sql性能优问题时,可以通过以下步骤,定位到问题sql并解决问题。
第一步:通过show status命令来了解各种sql的执行频率
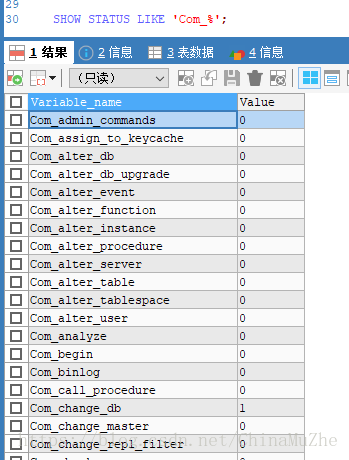
Com_xxx 表示每个 xxx 语句执行的次数,我们通常比较关心的是以下几个统计参数。
Com_select:执行 select 操作的次数,一次查询只累加 1。
Com_insert:执行 INSERT 操作的次数,对于批量插入的 INSERT 操作,只累加一次。
Com_update:执行 UPDATE 操作的次数。
Com_delete:执行 DELETE 操作的次数。
上面这些参数对于所有存储引擎的表操作都会进行累计。
如果是表是InnoDB 存储引擎的,累加的算法也略有不同 。我们使用以下命令:
SHOW STATUS LIKE "Innodb_rows_%";
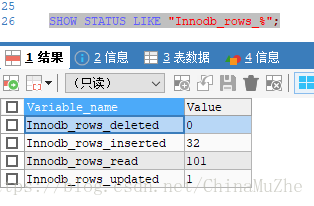
Innodb_rows_read:select 查询返回的行数。
Innodb_rows_inserted:执行 INSERT 操作插入的行数。
Innodb_rows_updated:执行 UPDATE 操作更新的行数。
Innodb_rows_deleted:执行 DELETE 操作删除的行数。
通过以上几个参数,可以很容易地了解当前数据库的应用是以插入更新为主还是以查询操作为主,以及各种类型的 SQL 大致的执行比例是多少。对于更新操作的计数,是对执行次数的计数,不论提交还是回滚都会进行累加。
对于事务型的应用,通过 Com_commit 和 Com_rollback 可以了解事务提交和回滚的情况,对于回滚操作非常频繁的数据库,可能意味着应用编写存在问题。此外,以下几个参数便于用户了解数据
库的基本情况。
Connections:试图连接 MySQL 服务器的次数。
Uptime:服务器工作时间。
Slow_queries:慢查询的次数。
第二步:定位执行效率较低的 SQL 语句
可以通过以下两种方式定位执行效率较低的 SQL 语句。通过慢查询日志定位那些执行效率较低的 SQL 语句,用--log-slow-queries[=file_name]选项启动时,mysqld 写一个包含所有执行时间超过 long_query_time 秒的 SQL 语句的日志文件。具体可以查看本书第 26 章中日志管理的相关部分。
慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题的时候查询慢查询日志并不能定位问题,可以使用 show processlist 命令查看当前 MySQL 在进行的线程,包括线程的状态、是否锁表等,可以实时地查看 SQL 的执行情况,同时对一些锁表操作进行优化。
说明各列的含义和用途:
id列:一个标识,你要kill 一个语句的时候很有用。user列: 显示当前用户,如果不是root,这个命令就只显示你权限范围内的sql语句。
host列:显示这个语句是从哪个ip 的哪个端口上发出的。可用来追踪出问题语句的用户。
db列:显示这个进程目前连接的是哪个数据库。
command列:显示当前连接的执行的命令,一般就是休眠(sleep),查询(query),连接(connect)。
time列:此这个状态持续的时间,单位是秒。
state列:显示使用当前连接的sql语句的状态,很重要的列,后续会有所有的状态的描述,请注意,state只是语 句执行中的某一个状态,一个sql语句,已查询为例,可能需要经过copying to tmp table,Sorting result, Sending data等状态才可以完成。
info列:显示这个sql语句,因为长度有限,所以长的sql语句就显示不全,但是一个判断问题语句的重要依据。
这个命令中最关键的就是state列,mysql列出的状态主要有以下几种:
Checking table:正在检查数据表(这是自动的)。
Closing tables:正在将表中修改的数据刷新到磁盘中,同时正在关闭已经用完的表。这是一个很快的操作,如果不是这样的话,就应该确认磁盘空间是否已经满了或者磁盘是否正处于重负中。
Connect Out:复制从服务器正在连接主服务器。
Copying to tmp table on disk:由于临时结果集大于 tmp_table_size,正在将临时表从内存存储转为磁盘存储以此节省内存。
第三步:通过 EXPLAIN 分析低效 SQL 的执行计划
通过以上步骤查询到效率低的 SQL 语句后,可以通过 EXPLAIN 或者 DESC 命令获取 MySQL如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序,比如查询:

每个列的简单解释如下:
select_type:表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个 SELECT)等。table:输出结果集的表。
type:表示表的连接类型,性能由好到差的连接类型为 system(表中仅有一行,即常量表)、const(单表中最多有一个匹配行,例如 primary key 或者 unique index)、eq_ref(对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用 primary key或者 unique index)、ref (与 eq_ref 类似,区别在于不是使用 primarykey 或者 unique index,而是使用普通的索引)、ref_or_null(与 ref 类似,区别在于条件中包含对 NULL 的查询)、index_merge(索引合并优化)、unique_subquery(in的后面是一个查询主键字段的子查询)、index_subquery(与 unique_subquery 类似,区别在于 in 的后面是查询非唯一索引字段的子查询)、range(单表中的范围查询)、index(对于前面的每一行,都通过查询索引来得到数据)、all(对于前面的每一行,都通过全表扫描来得到数据)。
possible_keys:表示查询时,可能使用的索引。
key:表示实际使用的索引。
key_len:索引字段的长度。
rows:扫描行的数量。
Extra:执行情况的说明和描述。
第四步:确定问题并采取相应的优化措施
在上面的例子中,已经可以确认是对 ols_party 表的全表扫描导致效率的不理想,那么对 ols_party 表的
id 字段创建索引,具体如下:
CREATE INDEX inx_party_id ON ols_party_agent(party_id);创建索引后,再看一下这条语句的执行计划,具体如下:

本文内容主要来自于Linux公社-深入浅出Mysql.pdf。一部分是自己理解和总结的。
本博客为自己总结亦或在网上发现的技术博文的转载。 如果文中有什么错误,欢迎指出。以免更多的人被误导。
邮箱:[email protected]
版权声明:本文为博主原创文章,博客地址:https://blog.csdn.net/ChinaMuZhe,未经博主允许不得转载