其中源代码官方网站是:https://github.com/matterport/Mask_RCNN
自己改好的代码下载地址:点击打开链接 自己上把官网的ipynb格式代码通过Jutyper notebook的【Download as】转化为py格式的代码。其如图:
由于官网经常进行一些代码优化升级,但是其里面的例子程序没有跟着进行更新接口,这就导致一些例子代码运行有些问题。其中有一个例子程序就是形状识别的。其中有一一些小地方需要修改下的。
其形状识别时使用Opencv来构建一个数据集的,其如下:
构造的数据集需要继承utils.Dataset类,使用load_shapes()方法向外提供加载数据的方法,并需要重写下面的方法:
- load_image()
- load_mask()
- image_reference()
构造数据集的代码:
class ShapesDataset(utils.Dataset):
"""
生成一个数据集,数据集由简单的(三角形,正方形,圆形)放置在空白画布的图片组成。
"""
def load_shapes(self, count, height, width):
"""
产生对应数目的固定大小图片
count: 生成数据的数量
height, width: 产生图片的大小
"""
# 添加种类信息
self.add_class("shapes", 1, "square")
self.add_class("shapes", 2, "circle")
self.add_class("shapes", 3, "triangle")
# 生成随机规格形状,每张图片依据image_id指定
for i in range(count):
bg_color, shapes = self.random_image(height, width)
self.add_image("shapes", image_id=i, path=None,
width=width, height=height,
bg_color=bg_color, shapes=shapes)
def load_image(self, image_id):
"""
依据给定的iamge_id产生对应图片。
通常这个函数是读取文件的,这里我们是依据image_id到image_info里面查找信息,再生成图片
"""
info = self.image_info[image_id]
bg_color = np.array(info['bg_color']).reshape([1, 1, 3])
image = np.ones([info['height'], info['width'], 3], dtype=np.uint8)
image = image * bg_color.astype(np.uint8)
for shape, color, dims in info['shapes']:
image = self.draw_shape(image, shape, dims, color)
return image
def image_reference(self, image_id):
"""Return the shapes data of the image."""
info = self.image_info[image_id]
if info["source"] == "shapes":
return info["shapes"]
else:
super(self.__class__).image_reference(self, image_id)
def load_mask(self, image_id):
"""依据给定的image_id产生相应的规格形状的掩膜"""
info = self.image_info[image_id]
shapes = info['shapes']
count = len(shapes)
mask = np.zeros([info['height'], info['width'], count], dtype=np.uint8)
for i, (shape, _, dims) in enumerate(info['shapes']):
mask[:, :, i:i+1] = self.draw_shape(mask[:, :, i:i+1].copy(),
shape, dims, 1)
# Handle occlusions
occlusion = np.logical_not(mask[:, :, -1]).astype(np.uint8)
for i in range(count-2, -1, -1):
mask[:, :, i] = mask[:, :, i] * occlusion
occlusion = np.logical_and(occlusion, np.logical_not(mask[:, :, i]))
# Map class names to class IDs.
class_ids = np.array([self.class_names.index(s[0]) for s in shapes])
return mask, class_ids.astype(np.int32)
def draw_shape(self, image, shape, dims, color):
"""绘制给定的形状."""
# Get the center x, y and the size s
x, y, s = dims
if shape == 'square':
image = cv2.rectangle(image, (x-s, y-s), (x+s, y+s), color, -1)
elif shape == "circle":
image = cv2.circle(image, (x, y), s, color, -1)
elif shape == "triangle":
points = np.array([[(x, y-s),
(x-s/math.sin(math.radians(60)), y+s),
(x+s/math.sin(math.radians(60)), y+s),
]], dtype=np.int32)
image = cv2.fillPoly(image, points, color)
return image
def random_shape(self, height, width):
"""
依据给定的长宽边界生成随机形状
返回一个有三个值的元组:
* shape: 形状名称(square, circle, ...)
* color: 形状颜色(a tuple of 3 values, RGB.)
* dimensions: 随机形状的中心位置和大小(center_x,center_y,size)
"""
# Shape
shape = random.choice(["square", "circle", "triangle"])
# Color
color = tuple([random.randint(0, 255) for _ in range(3)])
# Center x, y
buffer = 20
y = random.randint(buffer, height - buffer - 1)
x = random.randint(buffer, width - buffer - 1)
# Size
s = random.randint(buffer, height//4)
return shape, color, (x, y, s)
def random_image(self, height, width):
"""
产生有多种形状的随机规格的图片
返回背景色 和 可以用于绘制图片的形状规格列表
"""
# 随机生成三个通道颜色
bg_color = np.array([random.randint(0, 255) for _ in range(3)])
# 生成一些随机形状并记录它们的bbox
shapes = []
boxes = []
N = random.randint(1, 4)
for _ in range(N):
shape, color, dims = self.random_shape(height, width)
shapes.append((shape, color, dims))
x, y, s = dims
boxes.append([y-s, x-s, y+s, x+s])
# 使用非极大值抑制避免各种形状之间覆盖 阈值为:0.3
keep_ixs = utils.non_max_suppression(np.array(boxes), np.arange(N), 0.3)
shapes = [s for i, s in enumerate(shapes) if i in keep_ixs]
return bg_color, shapes用上面的数据类构造一组数据,看看:
# 构建训练集,大小为500
dataset_train = ShapesDataset()
dataset_train.load_shapes(500, config.IMAGE_SHAPE[0], config.IMAGE_SHAPE[1])
dataset_train.prepare()
# 构建验证集,大小为50
dataset_val = ShapesDataset()
dataset_val.load_shapes(50, config.IMAGE_SHAPE[0], config.IMAGE_SHAPE[1])
dataset_val.prepare()
# 随机选取4个样本
image_ids = np.random.choice(dataset_train.image_ids, 4)
for image_id in image_ids:
image = dataset_train.load_image(image_id)
mask, class_ids = dataset_train.load_mask(image_id)
visualize.display_top_masks(image, mask, class_ids, dataset_train.class_names)
注意:这个就是其中一个训练样本的原图、mask图。其中不同种类里的mask值是不同的。由于其显示的模态对话框,所以在浏览完随机选取的样本后,需要手动把这个对话框关闭,程序才会继续往下执行。
为上面构造的数据集配置一个对应的ShapesConfig类,该类的作用统一模型配置参数。该类需要继承Config类:
class ShapesConfig(Config):
"""
为数据集添加训练配置
继承基类Config
"""
NAME = "shapes" # 该配置类的识别符
#Batch size is 8 (GPUs * images/GPU).
GPU_COUNT = 1 # GPU数量
IMAGES_PER_GPU = 8 # 单GPU上处理图片数(这里我们构造的数据集图片小,可以多处理几张)
# 分类种类数目 (包括背景)
NUM_CLASSES = 1 + 3 # background + 3 shapes
# 使用小图片可以更快的训练
IMAGE_MIN_DIM = 128 # 图片的小边长
IMAGE_MAX_DIM = 128 # 图片的大边长
# 使用小的anchors,因为数据图片和目标都小
RPN_ANCHOR_SCALES = (8, 16, 32, 64, 128) # anchor side in pixels
# 减少训练每张图片上的ROIs,因为图片很小且目标很少,
# Aim to allow ROI sampling to pick 33% positive ROIs.
TRAIN_ROIS_PER_IMAGE = 32
STEPS_PER_EPOCH = 100 # 因为数据简单,使用小的epoch,每个epoch训练的步数
VALIDATION_STPES = 5 # 因为epoch较小,使用小的交叉验证步数
config = ShapesConfig()
config.print()
>>>
>>>
Configurations:
BACKBONE_SHAPES [[32 32]
[16 16]
[ 8 8]
[ 4 4]
[ 2 2]]
BACKBONE_STRIDES [4, 8, 16, 32, 64]
BATCH_SIZE 8
BBOX_STD_DEV [ 0.1 0.1 0.2 0.2]
DETECTION_MAX_INSTANCES 100
DETECTION_MIN_CONFIDENCE 0.7
DETECTION_NMS_THRESHOLD 0.3
GPU_COUNT 1
IMAGES_PER_GPU 8
IMAGE_MAX_DIM 128
IMAGE_MIN_DIM 128
IMAGE_PADDING True
IMAGE_SHAPE [128 128 3]
LEARNING_MOMENTUM 0.9
LEARNING_RATE 0.002
MASK_POOL_SIZE 14
MASK_SHAPE [28, 28]
MAX_GT_INSTANCES 100
MEAN_PIXEL [ 123.7 116.8 103.9]
MINI_MASK_SHAPE (56, 56)
NAME shapes
NUM_CLASSES 4
POOL_SIZE 7
POST_NMS_ROIS_INFERENCE 1000
POST_NMS_ROIS_TRAINING 2000
ROI_POSITIVE_RATIO 0.33
RPN_ANCHOR_RATIOS [0.5, 1, 2]
RPN_ANCHOR_SCALES (8, 16, 32, 64, 128)
RPN_ANCHOR_STRIDE 2
RPN_BBOX_STD_DEV [ 0.1 0.1 0.2 0.2]
RPN_TRAIN_ANCHORS_PER_IMAGE 256
STEPS_PER_EPOCH 100
TRAIN_ROIS_PER_IMAGE 32
USE_MINI_MASK True
USE_RPN_ROIS True
VALIDATION_STPES 5
WEIGHT_DECAY 0.0001
2、加载模型并训练:
上面配置好了个人数据集和对应的Config了,下面加载预训练模型:
# 模型有两种模式: training inference
# 创建模型并设置training模式
model = modellib.MaskRCNN(mode="training", config=config,
model_dir=MODEL_DIR)
# 选择权重类型,这里我们的预训练权重是COCO的
init_with = "coco" # imagenet, coco, or last
if init_with == "imagenet":
model.load_weights(model.get_imagenet_weights(), by_name=True)
elif init_with == "coco":
# 载入在MS COCO上的预训练模型,跳过不一样的分类数目层
model.load_weights(COCO_MODEL_PATH, by_name=True,
exclude=["mrcnn_class_logits", "mrcnn_bbox_fc",
"mrcnn_bbox", "mrcnn_mask"])
elif init_with == "last":
# 载入你最后训练的模型,继续训练
model.load_weights(model.find_last()[1], by_name=True)3、训练模型:
在完成上面的权重加载后,下面就可以执行训练,其中训练的了:
A、其中训练方法有两种一种是进行微调网络最后几层参数。其中需要向train()网络传入layers=‘heads’参数,这种微调方法适合现在的数据种类给coco里的物体种类类似。这样子训练可以省时省事。
B、另一种微调有点类型重新训练。这种是在物体种类跟原始权重检测的物体种类相差太大的时候使用。这是传入的参数是layer='all'。
其中在原例子工程上是这两个训练代码都没有注释的。这时我们只需要注释掉其中的一个训练代码即可。
例如我使用的是微调最后几层参数。则是如下代码:
# Train the head branches
# Passing layers="heads" freezes all layers except the head
# layers. You can also pass a regular expression to select
# which layers to train by name pattern.
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE,
epochs=2,
layers='heads')
# Fine tune all layers
# Passing layers="all" trains all layers. You can also
# pass a regular expression to select which layers to
# train by name pattern.
# model.train(dataset_train, dataset_val,
# learning_rate=config.LEARNING_RATE / 10,
# epochs=2,
# layers="all")注意:这个是把官网的ipynb格式的代码转为py格式的代码。具体装换方法可以参考网上的一些教程,很方便。
3、模型预测:
模型预测需要配置一个类InferenceConfig类即可,其中就有一些地方需要修改的。
class InferenceConfig(ShapesConfig):
GPU_COUNT = 1
IMAGES_PER_GPU = 1
inference_config = InferenceConfig()
# 重新创建模型设置为inference模式
model = modellib.MaskRCNN(mode="inference",
config=inference_config,
model_dir=MODEL_DIR)
# 这里手动指定训练好的文件名称。这里可以单独放到一个文件里专门是网络预测跟计算
# model_path = os.path.join(ROOT_DIR, ".h5 file name here")
model_path = os.path.join('./', "mask_rcnn_shapes_0002.h5")
# 加载权重
assert model_path != "", "Provide path to trained weights"
print("Loading weights from ", model_path)
model.load_weights(model_path, by_name=True)
# 测试随机图片,官网里的例子是缺失gt_class_id,返回变量的,需要添加上去。
image_id = random.choice(dataset_val.image_ids)
original_image, image_meta,gt_class_id,gt_bbox, gt_mask =\
modellib.load_image_gt(dataset_val, inference_config,
image_id, use_mini_mask=False)
log("original_image", original_image)
log("image_meta", image_meta)log("gt_class_id",gt_class_id)
log("gt_bbox", gt_bbox)
log("gt_mask", gt_mask)
visualize.display_instances(original_image, gt_bbox, gt_mask, gt_class_id,
dataset_train.class_names, figsize=(8, 8))
>>>
>>>
original_image shape: (128, 128, 3) min: 18.00000 max: 231.00000
image_meta shape: (12,) min: 0.00000 max: 128.00000
gt_bbox shape: (2, 5) min: 1.00000 max: 115.00000
gt_mask shape: (128, 128, 2) min: 0.00000 max: 1.00000随机几张验证集图片看看:

注意:这个是其中一个验证集里的样本图片,其中需要把对话框关闭,代码才可以往下执行。
使用模型预测,:
def get_ax(rows=1, cols=1, size=8):
"""返回Matplotlib Axes数组用于可视化.提供中心点控制图形大小"""
_, ax = plt.subplots(rows, cols, figsize=(size*cols, size*rows))
return ax
results = model.detect([original_image], verbose=1) # 预测
r = results[0]
visualize.display_instances(original_image, r['rois'], r['masks'], r['class_ids'],
dataset_val.class_names, r['scores'], ax=get_ax())
>>>
>>>
Processing 1 images
image shape: (128, 128, 3) min: 18.00000 max: 231.00000
molded_images shape: (1, 128, 128, 3) min: -98.80000 max: 127.10000
image_metas shape: (1, 12) min: 0.00000 max: 128.00000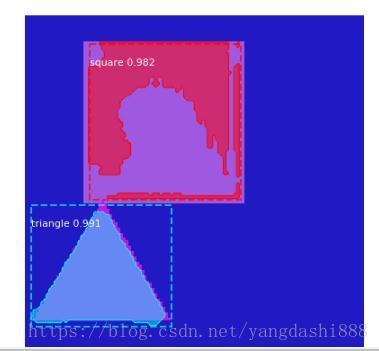
注意:这里需要注意的是把display_instances里的ax=get_ax()参数给注释掉,因为这个参数没注释掉的话则会导致不显示预测出来的结果图,如上。最后在预览完后关闭窗口。
4、计算输出网络的AP值:
image_ids = np.random.choice(dataset_val.image_ids, 10)
APs = []
for image_id in image_ids:
# 加载数据
image, image_meta,class_ids, gt_bbox, gt_mask =\
modellib.load_image_gt(dataset_val, inference_config,
image_id, use_mini_mask=False)
molded_images = np.expand_dims(modellib.mold_image(image, inference_config), 0)
# Run object detection
results = model.detect([image], verbose=0)
r = results[0]
hh=gt_bbox[:,:4]
# hh3=gt_bbox[:,4]
# Compute AP
AP, precisions, recalls, overlaps =\
utils.compute_ap(gt_bbox, class_ids,gt_mask,
r["rois"], r["class_ids"], r["scores"],r["masks"])
visualize.plot_precision_recall(AP,precisions,recalls)
APs.append(AP)
print("mAP: ", np.mean(APs))