1 安装环境
python -V #查看版本
pip -V #查看版本
pip list #查看列表
makedir fisher #新建项目目录
pip install pipenv #进入项目目录安装pipenv
pipenv install #创建的虚拟环境绑定到项目目录
pipenv shell #激活项目,启动虚拟环境2 安装flask
pipenv install flask #用pipenv安装flask
pipenv graph #查看flask版本与依赖
pipenv --venv #查看当前的虚拟环境解释器路径(在pycharm中设置)
pipenv install -r requirements.txt #通过requirements.txt安装包
pipenv lock -r --dev > requirements.txt #像virtualenv一样用命令生成requirements 文件
pipenv shell 激活虚拟环境
python fisher.py 启动服务3 工具
常用命令
1 pipenv --where 列出本地工程路径
2 pipenv --venv 列出虚拟环境路径
3 pipenv --py 列出虚拟环境的Python可执行文件
4 pipenv install 安装包(创建虚拟环境)
5 pipenv install moduel --dev 在开发环境安装包
6 pipenv graph 查看包依赖
7 pipenv lock 生成lockfile
8 pipenv install --dev 安装所有开发环境包
9 pipenv uninstall --all 卸载所有包
10 pipenv --rm 删除虚拟环境
Pycharm (vs code)
Xampp (mysql)
Navicat(数据化可视化工具)
#启动虚拟环境
方法一:
pipenv run python xxx.py
方法二:启动虚拟环境的shell环境
pipenv shell
python xxx.py 4 flask注意事项
1 @app.route('/hello/') #原理是进行了重定向,按照 /hello输入 服务器进行了两个过程
hello 服务器返回状态码301 并设置location重定向 127.0.0.1:5000/hello/,并再次返回200状态码
2 app.add_url_rule('/hello',view_func=hello)
装饰器@app.route('/hello/')其实就是装饰器函数调用app.add_url_rule('/hello',view_func=hello)方法
如果使用基于类的视图(即插视图),只能通过app.add_url_rule('/hello',view_func=hello)
3 host如果想外网访问: host=0.0.0.0,端口port也可以设置
4 配置文件的加载与导入
app.config.from_object('config')
app.config['DEBUG'] #config类本身就是dict的子类,因此可以字典形式访问
5 DEBUG是默认python中的默认参数为DEBUG=False,config['DEBUG']没找到DEBUG则默认False
找到config['DEBUG']则覆盖掉5 简化if else
r = requests.get(url)
r.json() if return_json else r.text
#三元表达式 [真返回 if 条件 else 假执行] 先输出r.json() 如果return_json为假输出r.text6 类方法 静态方法
@classmethod #类方法,当参数需要类不需要实例对象使用
def search_by_keyword(cls,keyword,page=1):
url = cls.keyword_url.format(keyword,current_app.config['PER_PAGE'],cls.calulate_start(page))
result = Http.get(url)
return result
@staticmethod #当方法中既不需要cls类,也不需要实例对象使用
def calulate_start(page):
return (page-1)* current_app.config['PER_PAGE']7 API接口
API难点不在于编写返回的数据,而在于对路由的设计定位
API实质就是提供的数据接口
#API+JS 前后端分离 SEO
#网站多页面ajax
#dict序列化 返回为元组,这就是API接口
return jsonify(result) #flask中提供了jsonify,效果一致
return json.dumps(result),200,{'content-type':'application/json'} #python中写法8 一般常见app下的目录结构与框架搭建
#app应用
cms #文件存放
form #表单类或表单验证
book.py #书相关验证
libs #自定义类及帮助文档
helpper.py
httper.py
models
book.py #模型类
web #蓝图web
__init__.py
book.py
user.py
spider #持久化存储
__init__.py
secure.py #秘钥安全验证之类的配置
setting.py #生产测试通用的配置
fisher.py
#fisher.py
from app import create_app
app = create_app()
if __name__ == '__main__':
app.run(debug=app.config['DEBUG'])
#app.__init__.py
from flask import Flask
from app.models.book import db
def create_app():
'''
系统配置注册与蓝图需要绑定app
'''
app = Flask(__name__)
app.config.from_object('app.secure') #系统配置
app.config.from_object('app.setting') #系统配置
register_blueprint(app)
'''初始化数据库'''
db.init_app(app)
db.create_all(app=app)
return app
def register_blueprint(app):
'''蓝图注册'''
#视图函数 帮助文档 模型类 表单类 数据API统一接口9 数据表创建三种方式
# database first 通过建表工具直接创建
# module first 通过创建模型生成数据表结构
# code first 通过ORM映射来生成数据表结构
flask在sqlalchemy 中封装了Flask_SQLAlchemy
flask在WTFORMS 中封装了Flask_WTFORMS
from sqlalchemy import Column,Integer,String #通过sqlalchemy导入基本数据类型
from flask_sqlalchemy import SQLAlchemy #通过flask_sqlalchemy导入SQLAlchemy核心对象
secure中配置
SQLALCHEMY_DATABASE_URI = 'mysql+cymysql://root:[email protected]:3306/fisher'
#方法1:
def create_app():
app = Flask(__name__)
app.config.from_object('app.secure')
app.config.from_object('app.setting')
register_blueprint(app)
db.init_app(app)
db.create_all(app=app) #关键字传递app核心对象
return app
#方法二:
def create_app():
app = Flask(__name__)
app.config.from_object('app.secure')
app.config.from_object('app.setting')
register_blueprint(app)
db.init_app(app)
with app.app_context(): #with上下文管理app核心对象
db.create_all()
return app
#方法三
db = SQLAlchemy(app=app)10 flask中上下文
应用级别上下文 对象 Flask封装
请求级别上下文 对象 Request封装
Flask核心对象 存储在Flask AppContext
Request请求对象 存储在Request RequestContent
让需要获取的两种对象时,我们往往不是通过直接导入获取,而是通过localproxy本地代理间接获取
from flask import Flask,current_app
#入栈方法一:
app = Flask(__name__) #获取app核心对象
ctx = app.app_context() #获取应用上下文
ctx.push() #将应用上下文入栈
a = current_app.config['DEBUG'] #返回的current_app是指应用上下文的app属性
ctx.pop() #出栈
#应用上下文源码:
current_app = LocalProxy(_find_app) #返回的是app
def _find_app():
top = _app_ctx_stack.top
if top is None:
raise RuntimeError(_app_ctx_err_msg)
return top.app
#请求上下文源码:
request = LocalProxy(partial(_lookup_req_object, 'request'))
def _lookup_req_object(name):
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
return getattr(top, name) #返回的是request对应的属性
# with: 可以对实现了上下文协议的对象使用with,对资源进行连接,操作及关闭,例如:数据库与文件读写操作
# 上下文管理器: 实现了__enter__与__exit__两个方法
# 上下文表达式必须返回一个上下文管理器
with app.app_context():
a = current_App.config['DEBUG']
class A: #上下文管理器
def __enter__(self): #代表进入上下文环境
a = 1
return a
def __exit__(self): #代表退出上下文环境
b = 2
with A() as obj_A: #obj_A返回的是__enter__放下对应的值a=1
pass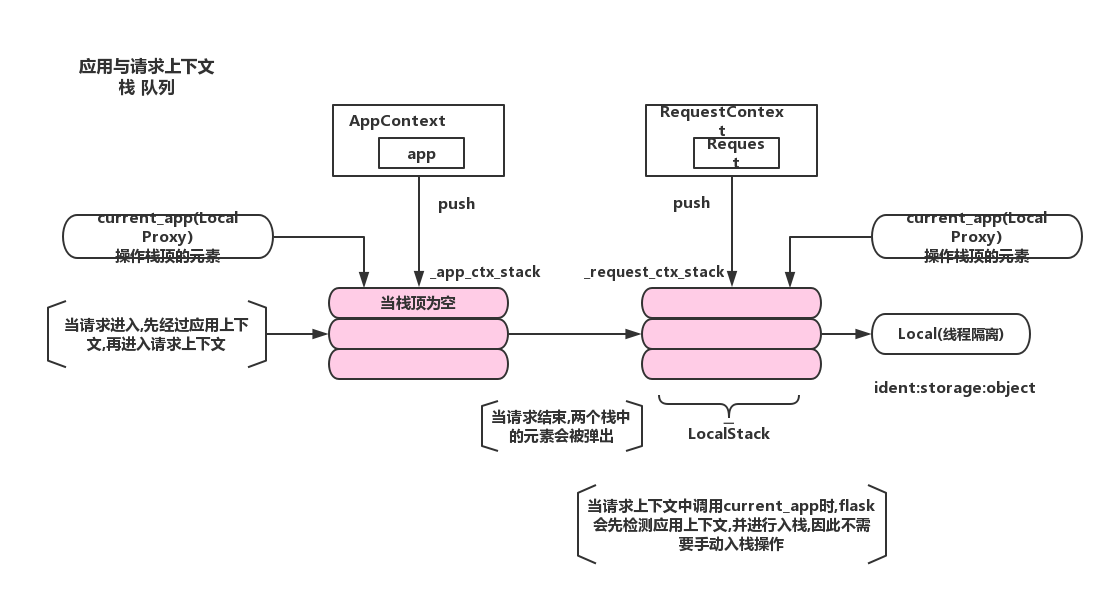
11 线程与进程
进程: 计算机竞争资源的最小单位,占用cpu资源进程,更多是用来分配管理资源. 各个进程根据调度算法实现进程的切 换,明显的缺点是切换开销大,因此进程切换肯定要被淘汰,比进程小的单元线程的诞生!
线程: 进程的一部分,一个进程包含至少一个线程,线程更多是用来执行访问资源的,不占用CPU资源,线程的工作是用过 访问进程cpu资源进行的,由于是在进程内部切换,因此开销明显小很多!
#GIL 全局线程锁
线程是不占有资源,需要访问进程内部的资源的,因此共享资源就会产生一个资源的冲突.因此锁机制就是保证同一时刻只允许一个线程进行访问.
细粒度锁 程序员 主动加锁
粗粒度锁 解释器 GIL
CPU密集型程序 进行CPU密集计算,例如视频的解码操作
IO密集型程序 查询数据库 请求网络资源 读写文件
#flask线程隔离 原因:一个变量对应多个对象引用时,存在引用混乱 原理 字典 保存数据
通过werkzeug库 local模块 Local对象字典管理(获取id号与键值对对应{19943,{key:value}})
使用线程隔离的意义在于使用当前线程能正确地引导到自己所创建的对象,而不是引用到其他线程创建的对象
#LocalStack Local 字典的三者区别
Local通过字典的方式实现线程隔离
LocalStack通过封装Local对象并将其作为私有属性,实现线程隔离的栈结构
s = LocalStack() #栈结构 先进后出
s.push(1)
s.push(2)
print(s.top) #2
print(s.top) #2
print(s.pop()) #2
print(s.top) #1
#以线程ID号作为key的字典 ->Local ->LocalStack
#AppContext RequestContext -> LocalStack
#Flask -> AppContext Request -> RequestContext
#current_app -> (LocalStack.top=AppContext top.app=flask) 栈顶取出上下文,app核心对象是上下文的属性
#request -> (LocalStack.top=RequestContext top.request=Request) 指向Request请求对象#local隔离
import time
from werkzeug.local import Local
class A:
b = 1
my_obj = Local() #将my_obj进行隔离
def worker():
my_obj.b = 2
print(my_obj.b) #输出2
new_th = threading.Thread(target=worker,name='one_thread')
new_th.start()
time.sleep(1)
print(my_obj.b) #输出1
#LocalStack线程隔离
from werkzeug.local import LocalStack
my_stack = LocalStack()
my_stack.push(1)
print('in main thread after push,value is' + str(my_stack.top)) #1
def worker():
print('in new thread after push,value is' + str(my_stack.top)) #None
my_stack.push(2)
print('in new thread after push,value is' + str(my_stack.top)) #2
new_t = threading.Thread(target=worker,name='ne_thread')
new_th.start()
time.sleep(1)
print('finally,in main thread after push,value is' + str(my_stack.top)) #112 编程思维
后端数据应该在原始数据的基础上进行统一格式的模块封装,用户查询的方式可能不同,但是我们返回的数据结构类型应该保持统一格式,提供便捷的API接口
面向对象编程应该包含:
特征(类变量,实例变量)
行为(方法)
#类的重构: 首先要明白类的具体定位,具体作用,为什么要面向对象编程
class YuShuBook:
'''
模型层: mvc中 M层
'''
isbn_url = 'http://t.yushu.im/v2/book/isbn/{}'
keyword_url = 'http://t.yushu.im/v2/book/search?q={}&count={}&start={}'
@classmethod
def search_by_isbn(cls,isbn):
url = cls.isbn_url.format(isbn) #或者self.isbn_url.format(isbn)
result = Http.get(url) #dict
return result
@classmethod
def search_by_keyword(cls,keyword,page=1):
url = cls.keyword_url.format(keyword,current_app.config.get('PER_PAGE'),
cls.calulate_start(page))
result = Http.get(url)
return result
@staticmethod
def calulate_start(page):
return (page-1)* current_app.config.get('PER_PAGE')
#view_models.book.py
class BookViewModel:
#对原始数据进行数据格式统一(裁切,合并等操作)
@classmethod
def package_single(cls, data, keyword):
returned = {
'books': [],
'total': 0,
'keyword': keyword
}
if data:
returned['total'] = 1
returned['books'] = [cls.__cut_book_data(data)]
return returned
@classmethod
def package_collection(cls, data, keyword):
returned = {
'books': [],
'total': 0,
'keyword': keyword
}
if data:
returned['total'] = data['total']
returned['books'] = [cls.__cut_book_data(book) for book in data['books']]
return returned
@classmethod
def __cut_book_data(cls, data):
book = {
'title': data['title'],
'publisher': data['publisher'],
'pages': data['pages'],
'author': '、'.join(data['author']),
'price': data['price'],
'summary': data['summary'],
'image': data['image']
}
return book
#类的重构之后区别:类不但定义了方法,而且重构后具有过滤保存精准查询信息的功能
from flask import current_app
from app.libs.httper import Http
class YuShuBook:
'''
模型层: mvc中 M层
'''
isbn_url = 'http://t.yushu.im/v2/book/isbn/{}'
keyword_url = 'http://t.yushu.im/v2/book/search?q={}&count={}&start={}'
def __init__(self):
self.total = 0
self.books = []
def search_by_isbn(self,isbn):
url = self.isbn_url.format(isbn) #或者self.isbn_url.format(isbn)
result = Http.get(url) #dict
self.__fill_single(result)
def search_by_keyword(self,keyword,page=1):
url = self.keyword_url.format(keyword,current_app.config.get('PER_PAGE'),
self.calulate_start(page))
result = Http.get(url)
self.__fill_collection(result)
def __fill_single(self,data):
if data:
self.total = 1
self.books.append(data)
def __fill_collection(self,data):
if data:
self.total = data['total']
self.books = data['books']
def calulate_start(self,page):
return (page-1)* current_app.config.get('PER_PAGE')
#view_models.book.py
class BookViewModel:
def __init__(self,book):
self.title = book['title']
self.publisher = book['publisher']
self.author = book['author']
self.image = book['image']
self.price = book['price']
self.summary = book['summary']
self.pages = book['pages']
class BookCollection:
def __init__(self):
self.total = 0
self.books = []
self.keyword = ''
def fill(self,yushu_book,keyword):
self.total = yushu_book.total
self.keyword = keyword
self.books = [BookViewModel(book) for book in yushu_book.books]