sql语句的执行顺序:
from where group by select having order by limit
一. 条件查询
①普通条件查询
select XX from 表名 where 查询的条件
②模糊查询
between and,in,or,范围查询,like
③空值查询
is null
二.排序
语法:order by asc(升)或desc(降 )
三.分组
关键字:group by
语法:select 分组的列,聚合函数 from 表名 group by 分组的列
注意:如果使用了group by 分组,那么select 不允许出现其他列,只能出现分组的列
分组本身没有意义,只有配合聚合函数,group_concat(其他列)才有意义
group_concat(其他列名):用来显示分组后某一组的所有数据。
聚合函数:count(),min(),max(),sum(),avg()
having条件表达式:用来限制分组后的输出
区别where和having:
where:作用于视图或者表,是视图和表的查询条件
having:作用于分组后的记录,用于选择符合条件的分组
按照多个字段分组:
group by 列1,列2
先按照列1进行分组,然后列1相等的记录再按照列2分组
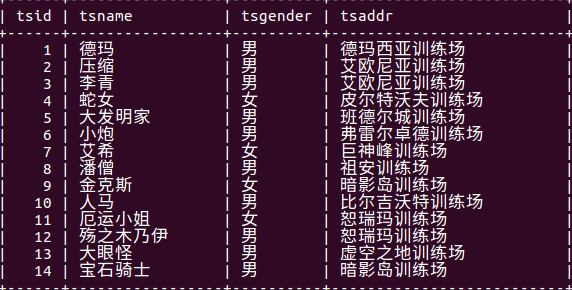
执行select tsgender,tsaddr from 学生表 group by tsgender,tsaddr;
执行结果:
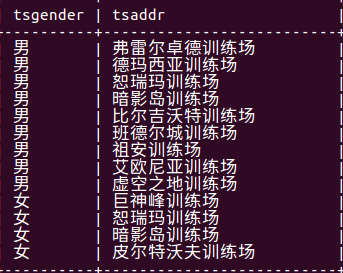
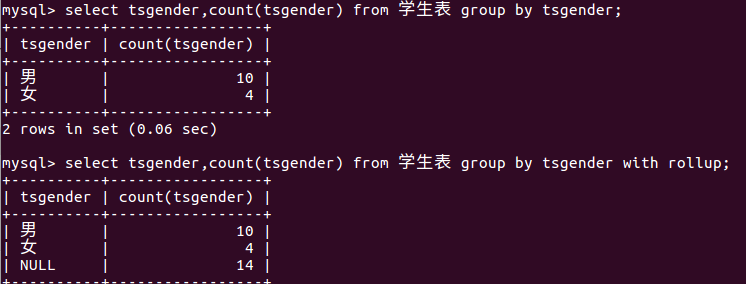
with rollup:
在记录最后加一条记录,该记录是上面所有记录的和
eg:
四.limit关键字的使用:
limit关键字用来规范输出内容的个数
用法:
①limit m:限制输出个数为m个
②limit m,n:限制输出从m+1开始,个数为n个
limit 5,10:输出记录6-15行
注意:默认从0记起
五.连接查询
内连接,左连接,右连接
inner join

left join

right join

这三种连接都是通过笛卡儿积来合并不同表的,这样会导致计算量大,因为先执行笛卡尔,再取两表连接列值相等的数据
自然连接
自动将表中相同名称的列进行记录匹配
表A nature join 表B
不用添加连接条件
自连接
上边我们谈到的所以连接都是基于多个不同表的连接
假想以下场景:某一电商网站想要对站内产品做层级分类,一个类别下面有若干子类,子类下面也会有别的子类。例如数码产品这个类别下面有笔记本,台式机,智能手机等;笔记本,台式机,智能手机又可以按照品牌分类;品牌又可以按照价格分类,等等。也许这些分类会达到一个很深的层次,呈现一种树状的结构。那么这些数据要怎么在数据库中表示呢?我们可以在数据库中创建两个字段来存储id和类别名称,使用第三个字段存储类别的子类或者父类的id,最后通过自连接去查询想要的结果。自连接查询其实等同于连接查询,需要两张表,只不过它的左表(父表)和右表(子表)都是自己。做自连接查询的时候,是自己和自己连接,分别给父表和子表取两个不同的别名,然后附上连接条件。所以用到的关键字仍然是inner join,left join, right join
谈到这里我们不难发现:其实任何表只要有相同数据,都可以进行连接并使用,只需连接的内容有意义即可!!
六.子查询
概念:将select的结果在另一个查询中使用的查询。
select * from (select col1,col2,col3 from table) as t
注意:
如果主查询使用到子查询的数据,则必须给子查询起一个别名。
在子查询使用管子运算符的时候要i注意,因为子查询可能返回多个值。
注意:能用子查询就不用连接查询,以为连接查询建立在笛卡儿积上,会造成比较复杂的合并表前的笛卡儿积计算